Researchers have found that giving large language models (LLMs) many examples directly in the prompt can be more effective than time-consuming fine-tuning, according to a study from Carnegie Mellon and Tel Aviv University.

the-decoder.com
AI in practice
May 6, 2024
Massive prompts can outperform fine-tuning for LLMs, researchers find
Midjourney prompted by THE DECODER
Matthias Bastian
Online journalist Matthias is the co-founder and publisher of THE DECODER. He believes that artificial intelligence will fundamentally change the relationship between humans and computers.
Profile
E-Mail
Researchers have found that giving large language models (LLMs) many examples directly in the prompt can be more effective than time-consuming fine-tuning, according to a study from Carnegie Mellon and Tel Aviv University.
This "in-context learning" (ICL) approach becomes more effective as the context window of LLMs grows, allowing for hundreds or thousands of examples in prompts, especially for tasks with many possible answers.
One method for selecting examples for ICL is "retrieval," where an algorithm (BM25) chooses the most relevant examples from a large dataset for each new question. This improves performance compared to random selection, particularly when using fewer examples.
However, the performance gain from retrieval diminishes with large numbers of examples, suggesting that longer prompts become more robust and individual examples or their order become less important.
While fine-tuning usually requires more data than ICL, it can sometimes outperform ICL with very long contexts. In some cases, ICL with long examples can be more effective and efficient than fine-tuning, even though ICL does not actually learn tasks but solves them using the examples, the researchers noted.
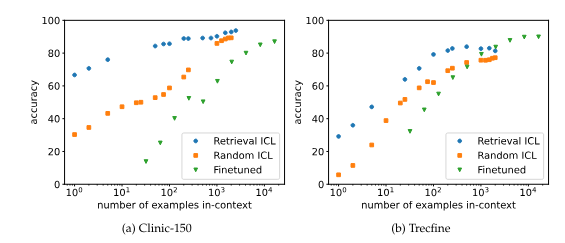
Fine-tuning sometimes, but not always, exceeds ICL at high numbers of demonstrations. | Image: Bertsch et al.
The experiments used special variants of the Llama-2-7B and Mistral-7B language models, which can process particularly long input text. The results suggest that ICL with many examples can be a viable alternative to retrieval and fine-tuning, especially as future models improve at handling extremely long input texts.
Ultimately, the choice between ICL and fine-tuning comes down to cost. Fine-tuning has a higher one-time cost, while ICL requires more computing power due to the many examples in the prompt. In some cases, it may be best to use many-shot prompts until you get a robust, reliable, high-quality result, and then use that data for fine-tuning.
While finetuning with full datasets is still a powerful option if the data vastly exceeds the context length, our results suggest that long-context ICL is an effective alternative– trading finetuning-time cost for increased inference-time compute. As the effectiveness and effiency of using very long model context lengths continues to increase, we believe long-context ICL will be a powerful tool for many tasks.
From the paper
The study confirms the results of a recent
Google Deepmind study on many-shot prompts, which also showed that using hundreds to thousands of examples can significantly improve LLM results.
- Researchers at Carnegie Mellon and Tel Aviv University have discovered that the results of large language models (LLMs) improve the more examples you give them directly in the input (prompt) as context. This method, called "In-Context Learning" (ICL), could be an alternative to time-consuming fine-tuning.
- In ICL with a large number of examples in the prompt, the performance of the language models increases further, especially for tasks with many possible answers. Retrieval methods for selecting relevant examples further improve the results. Finetuning requires more data than ICL, but can provide even better results in some cases.
- The researchers believe that ICL with long contexts will be a powerful tool for many tasks as language models get better at handling extremely long texts. Ultimately, it is also a question of cost whether ICL or fine-tuning is used. The study confirms earlier results from Google Deepmind on many-shot prompts.
Sources
Arxiv
Computer Science > Computation and Language
[Submitted on 30 Apr 2024]
In-Context Learning with Long-Context Models: An In-Depth Exploration
Amanda Bertsch,
Maor Ivgi,
Uri Alon,
Jonathan Berant,
Matthew R. Gormley,
Graham Neubig
As model context lengths continue to increase, the number of demonstrations that can be provided in-context approaches the size of entire training datasets. We study the behavior of in-context learning (ICL) at this extreme scale on multiple datasets and models. We show that, for many datasets with large label spaces, performance continues to increase with hundreds or thousands of demonstrations. We contrast this with example retrieval and finetuning: example retrieval shows excellent performance at low context lengths but has diminished gains with more demonstrations; finetuning is more data hungry than ICL but can sometimes exceed long-context ICL performance with additional data. We use this ICL setting as a testbed to study several properties of both in-context learning and long-context models. We show that long-context ICL is less sensitive to random input shuffling than short-context ICL, that grouping of same-label examples can negatively impact performance, and that the performance boosts we see do not arise from cumulative gain from encoding many examples together. We conclude that although long-context ICL can be surprisingly effective, most of this gain comes from attending back to similar examples rather than task learning.
Submission history
From: Amanda Bertsch [view email]
[v1] Tue, 30 Apr 2024 21:06:52 UTC (233 KB)













