You might enjoy this
It’s a long watch / listen but bashes the idea that we’re anywhere close to agi
Best/worst advertisement for Japanese Selvedge Denim?
13 minutes into it, this cat is DEEP. He's great at "explain it like I'm 5"

You might enjoy this
It’s a long watch / listen but bashes the idea that we’re anywhere close to agi


 techcrunch.com
techcrunch.com
 techcrunch.com
techcrunch.com

 techcrunch.com
techcrunch.com


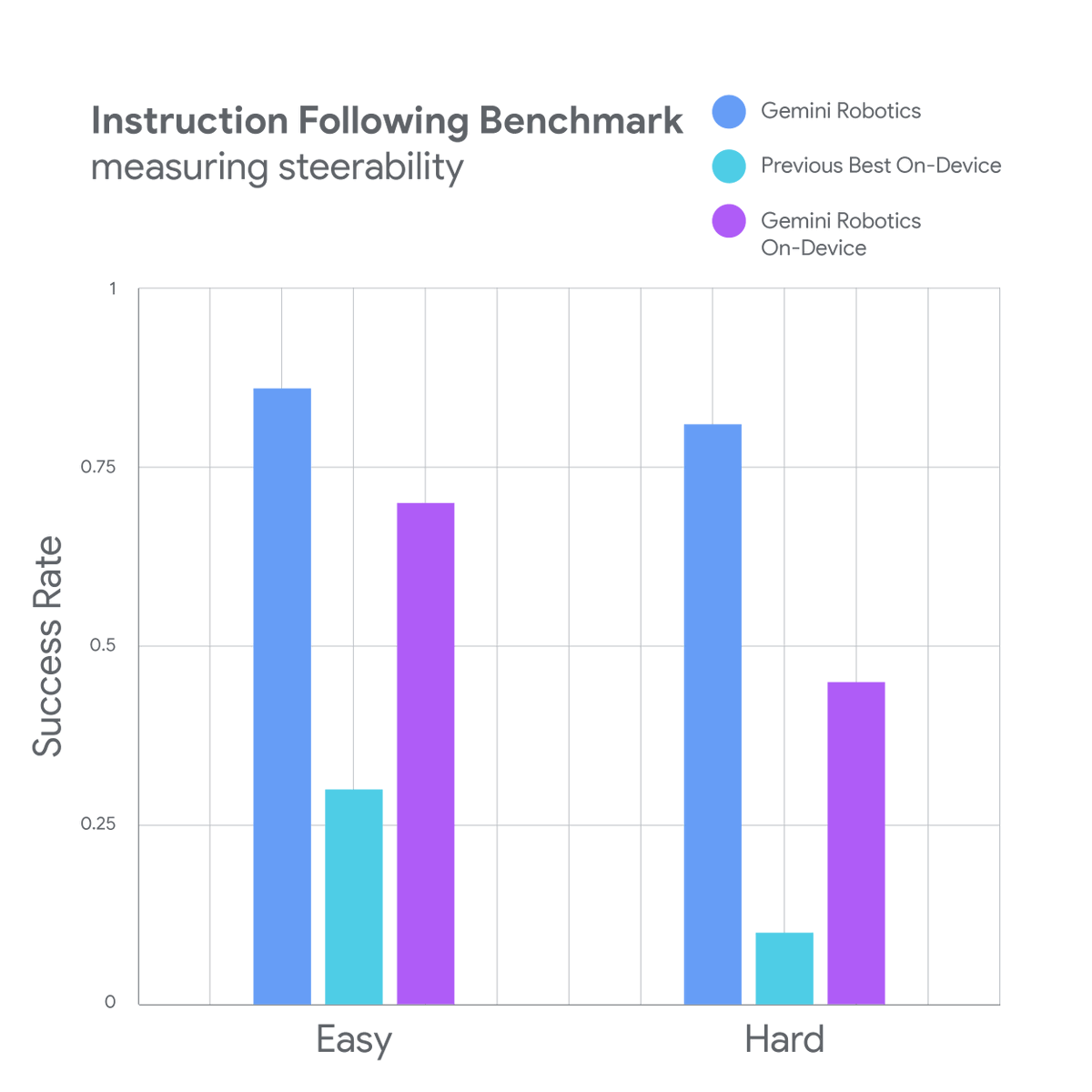
 It has the generality and dexterity of Gemini Robotics - but it can run locally on the device It can handle a wide variety of complex, two-handed tasks out of the box It can learn new skills with as few as 50-100 demonstrations
It has the generality and dexterity of Gemini Robotics - but it can run locally on the device It can handle a wide variety of complex, two-handed tasks out of the box It can learn new skills with as few as 50-100 demonstrations







 Can LLMs really reason outside the box in math? Or are they just remixing familiar strategies?
Can LLMs really reason outside the box in math? Or are they just remixing familiar strategies? 

 We found that although very powerful, RL struggles to compose skills and to innovate new strategies that were not seen during training.
We found that although very powerful, RL struggles to compose skills and to innovate new strategies that were not seen during training. 

 Inspired by Boden’s creativity framework (1998), OMEGA tests:
Inspired by Boden’s creativity framework (1998), OMEGA tests: Exploratory: Can the model adapt a known algorithm to solve harder variants within the same problem family?
Exploratory: Can the model adapt a known algorithm to solve harder variants within the same problem family? Compositional: Can the model compose familiar skills to solve a novel problem that requires the synergy of those skills?
Compositional: Can the model compose familiar skills to solve a novel problem that requires the synergy of those skills? Transformative: Can the model invent a new unconventional strategy by moving beyond familiar approaches to solve problems more effectively?
Transformative: Can the model invent a new unconventional strategy by moving beyond familiar approaches to solve problems more effectively?
 You may wonder why we're introducing yet another math benchmark when the community already has plenty. The issue is that most existing benchmarks don't let us precisely control the difficulty or the specific skills each problem requires.
You may wonder why we're introducing yet another math benchmark when the community already has plenty. The issue is that most existing benchmarks don't let us precisely control the difficulty or the specific skills each problem requires.
 : even a slight increase in task complexity causes performance to collapse to 0%.
: even a slight increase in task complexity causes performance to collapse to 0%. This suggests that current models may not have fully internalized the underlying algorithms, but rather learned patterns at specific complexity levels
This suggests that current models may not have fully internalized the underlying algorithms, but rather learned patterns at specific complexity levels
 We noticed that many failures stem not from lack of knowledge but from overthinking. Models often find the right answer early in CoT, but spiral into self-corrections and abandon correct solutions. This challenges the assumption:
We noticed that many failures stem not from lack of knowledge but from overthinking. Models often find the right answer early in CoT, but spiral into self-corrections and abandon correct solutions. This challenges the assumption:
 it Helps at moderate complexity, but Gains plateau at higher levels
it Helps at moderate complexity, but Gains plateau at higher levels
 Can RL effectively generalize from easy to hard problems? We find strong early gains, but generalization plateaus with task complexity
Can RL effectively generalize from easy to hard problems? We find strong early gains, but generalization plateaus with task complexity 0.45 → 0.80 after RL).
0.45 → 0.80 after RL). performance drops on the same problem family. There are limits to how far learned strategies can stretch
performance drops on the same problem family. There are limits to how far learned strategies can stretch Can RL learn to compose math skills into integrated solutions?
Can RL learn to compose math skills into integrated solutions? Strong on isolated skills
Strong on isolated skills Weak on composition: even when models mastered A & B, they failed on A⊕B.
Weak on composition: even when models mastered A & B, they failed on A⊕B. Unlike humans, who naturally combine what they know to tackle novel problems.
Unlike humans, who naturally combine what they know to tackle novel problems. Transformative generalization?
Transformative generalization?
 Paper: OMEGA: Can LLMs Reason Outside the Box in Math? Evaluating Exploratory, Compositional, and Transformative Generalization
Paper: OMEGA: Can LLMs Reason Outside the Box in Math? Evaluating Exploratory, Compositional, and Transformative Generalization Blog: OMEGA: Can LLMs Reason Outside the Box in Math? | Ai2
Blog: OMEGA: Can LLMs Reason Outside the Box in Math? | Ai2 Code & data: GitHub - sunblaze-ucb/math_ood
Code & data: GitHub - sunblaze-ucb/math_ood The next paper, proving again..
The next paper, proving again.. Collapse under modest complexity: All four top models keep near perfect accuracy at level 1, but even a two-step jump in difficulty drives accuracy toward 0%.A thread
Collapse under modest complexity: All four top models keep near perfect accuracy at level 1, but even a two-step jump in difficulty drives accuracy toward 0%.A thread 
 The Core Problem
The Core Problem
 Benchmark Design
Benchmark Design

 Three Generalization Axes
Three Generalization Axes Baseline Model Limits
Baseline Model Limits


 Reinforcement Learning Gains and Ceiling
Reinforcement Learning Gains and Ceiling
 Composing Skills Trouble
Composing Skills Trouble Creativity Roadblock
Creativity Roadblock
 Takeaways
Takeaways
 : This is MCP server for Claude that gives it terminal control, file system search and diff file editing capabilities
: This is MCP server for Claude that gives it terminal control, file system search and diff file editing capabilities github. com/wonderwhy-er/DesktopCommanderMCP
github. com/wonderwhy-er/DesktopCommanderMCP : Agent S: an open agentic framework that uses computers like a human github. com/simular-ai/Agent-S
: Agent S: an open agentic framework that uses computers like a human github. com/simular-ai/Agent-S