Google DeepMind has revealed Genie 3, its latest foundation world model that the AI lab says presents a crucial stepping stone on the path to artificial general intelligence, or human-like intelligence.

techcrunch.com
DeepMind thinks its new Genie 3 world model presents a stepping stone toward AGI
Rebecca Bellan
7:10 AM PDT · August 5, 2025
Google DeepMind has revealed Genie 3, its latest foundation world model that can be used to train general-purpose AI agents, a capability that the AI lab says makes for a crucial stepping stone on the path to “artificial general intelligence,” or human-like intelligence.
“Genie 3 is the first real-time interactive general-purpose world model,” Shlomi Fruchter, a research director at DeepMind, said during a press briefing. “It goes beyond narrow world models that existed before. It’s not specific to any particular environment. It can generate both photo-realistic and imaginary worlds, and everything in between.”
Still in research preview and not publicly available, Genie 3 builds on both its predecessor
Genie 2 (which can generate new environments for agents) and DeepMind’s latest video generation model
Veo 3 (which is said to have a deep understanding of physics).
Image Credits:Google DeepMind
With a simple text prompt, Genie 3 can generate multiple minutes of interactive 3D environments at 720p resolution at 24 frames per second — a significant jump from the 10 to 20 seconds Genie 2 could produce. The model also features “promptable world events,” or the ability to use a prompt to change the generated world.
Perhaps most importantly, Genie 3’s simulations stay physically consistent over time because the model can remember what it previously generated — a capability that DeepMind says its researchers didn’t explicitly program into the model.
Fruchter said that while Genie 3 has implications for educational experiences,
gaming or prototyping creative concepts, its real unlock will manifest in training agents for general-purpose tasks, which he said is essential to reaching AGI.
“We think world models are key on the path to AGI, specifically for embodied agents, where simulating real world scenarios is particularly challenging,” Jack Parker-Holder, a research scientist on DeepMind’s open-endedness team, said during the briefing.
Image Credits:Google DeepMind
Genie 3 is supposedly designed to solve that bottleneck. Like Veo, it doesn’t rely on a hard-coded phys
ics engine; instead, DeepMind says, the model teaches itself how the world works — how objects move, fall, and interact — by remembering what it has generated and reasoning over long time horizons.
“The model is auto-regressive, meaning it generates one frame at a time,” Fruchter told TechCrunch in an interview. “It has to look back at what was generated before to decide what’s going to happen next. That’s a key part of the architecture.”
That memory, the company says, lends to consistency in Genie 3’s simulated worlds, which in turn allows it to develop a grasp of physics, similar to how humans understand that a glass teetering on the edge of a table is about to fall, or that they should duck to avoid a falling object.
Notably, DeepMind says the model also has the potential to push AI agents to their limits — forcing them to learn from their own experience, similar to how humans learn in the real world.
As an example, DeepMind shared its test of Genie 3 with a recent version of its generalist
Scalable Instructable Multiworld Agent (SIMA), instructing it to pursue a set of goals. In a warehouse setting, they asked the agent to perform tasks like “approach the bright green trash compactor” or “walk to the packed red forklift.”
“In all three cases, the SIMA agent is able to achieve the goal,” Parker-Holder said. “It just receives the actions from the agent. So the agent takes the goal, sees the world simulated around it, and then takes the actions in the world. Genie 3 simulates forward, and the fact that it’s able to achieve it is because Genie 3 remains consistent.”
Image Credits:Google DeepMind
That said, Genie 3 has its limitations. For example, while the researchers claim it can understand physics, the demo showing a skier barreling down a mountain didn’t reflect how snow would move in relation to the skier.
Additionally, the range of actions an agent can take is limited. For example, the promptable world events allow for a wide range of environmental interventions, but they’re not necessarily performed by the agent itself. And it’s still difficult to accurately model complex interactions between multiple independent agents in a shared environment.
Genie 3 can also only support a few minutes of continuous interaction, when hours would be necessary for proper training.
Still, the model presents a compelling step forward in teaching agents to go beyond reacting to inputs, letting them potentially plan, explore, seek out uncertainty, and improve through trial and error — the kind of self-driven, embodied learning that many say is key to moving toward general intelligence.
“We haven’t really had a Move 37 moment for embodied agents yet, where they can actually take novel actions in the real world,” Parker-Holder said, referring to the legendary moment in the 2016 game of Go between DeepMind’s AI agent AlphaGo and world champion Lee Sedol, in which Alpha Go played an unconventional and brilliant move that became symbolic of AI’s ability to discover new strategies beyond human understanding.
“But now, we can potentially usher in a new era,” he said.



 X: x.com/matthewberman
X: x.com/matthewberman




 . Didn't recognize it at first.
. Didn't recognize it at first.


 , reasoning
, reasoning  , and creative writing
, and creative writing 

 AIDER Polyglot (coding)
AIDER Polyglot (coding)
 Start building with Gemini 2.5 Pro in Preview in @Google AI Studio, @GeminiApp, and @GoogleCloud’s /search?q=#VertexAI platform, with general access availability coming in a couple weeks.
Start building with Gemini 2.5 Pro in Preview in @Google AI Studio, @GeminiApp, and @GoogleCloud’s /search?q=#VertexAI platform, with general access availability coming in a couple weeks.







 “That’s... creative structuring.”
“That’s... creative structuring.”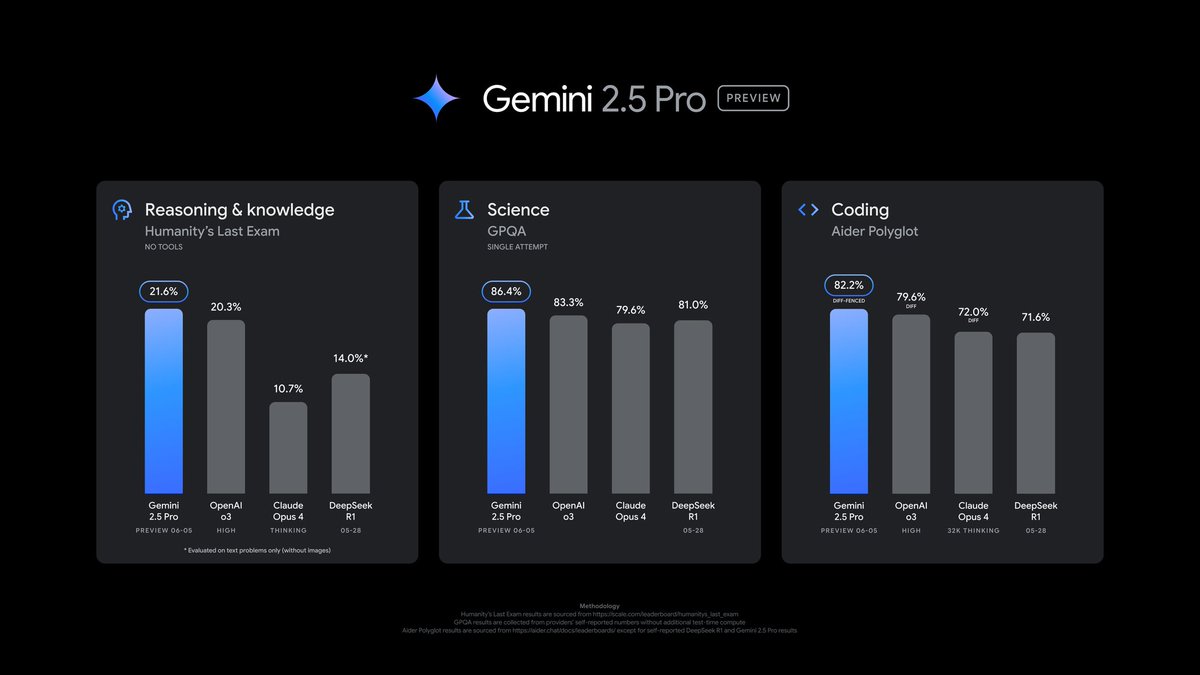







 -they finally got me. s3/aws/gcp/firestore/
-they finally got me. s3/aws/gcp/firestore/
 4 sdk/adk
4 sdk/adk  and mem pruning for their adk agent hckthn. student_agent “Graduates”.
and mem pruning for their adk agent hckthn. student_agent “Graduates”.












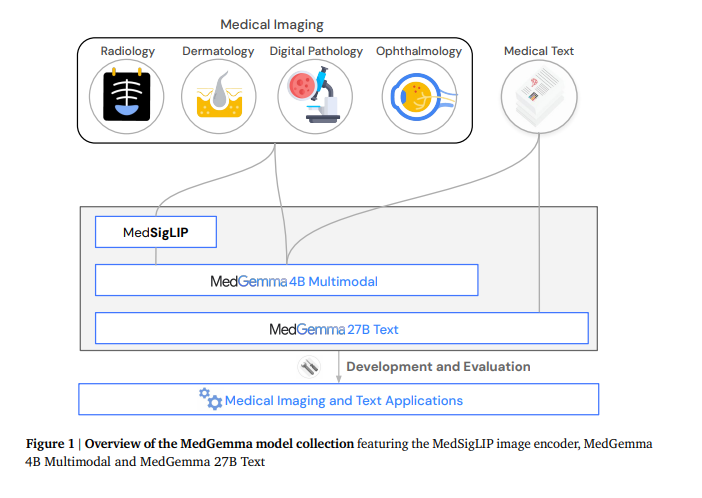
 Google Research release MedGemma 27B, multimodal health-AI models that run on 1 GPU
Google Research release MedGemma 27B, multimodal health-AI models that run on 1 GPU 














 Fly into the weekend with 3 FREE video generations with Veo 3 in the Google Gemini App.
Fly into the weekend with 3 FREE video generations with Veo 3 in the Google Gemini App.