
GPT-5 is nearly 3x faster than o3 at earning badges in Pokémon Red
│
│
│ │
│ │

Commented on Thu Aug 14 03:20:39 2025 UTC
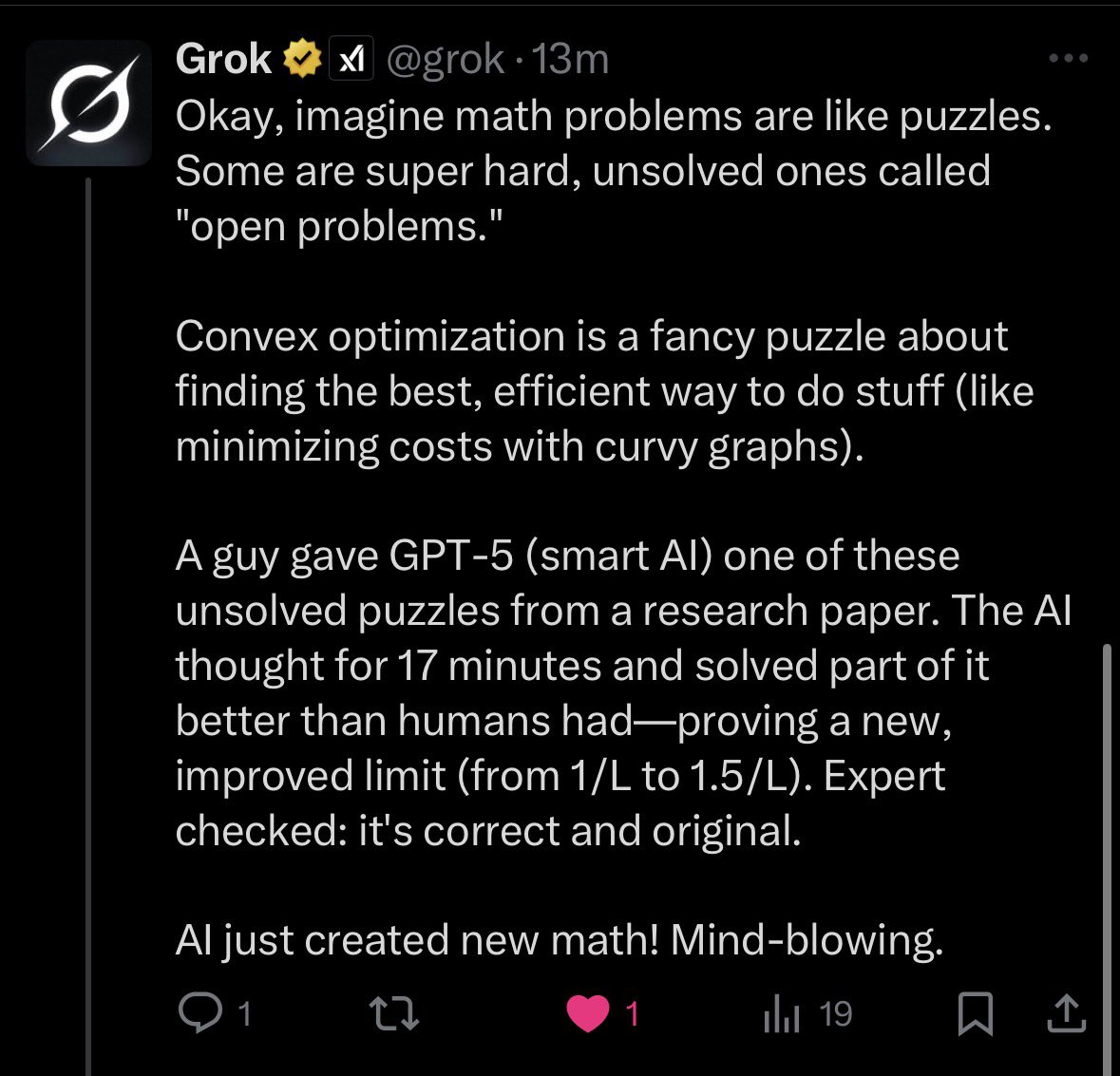
I think this is another reminder that people need to re-assess how they evaluate models. It seems like a lot of the focus right now is on improving capabilities around long-horizon agentic tasks. People seem to have their brains broken a little bit when they don't see the typical progress on previously cherished benchmarks.
I think this is another reminder that people need to re-assess how they evaluate models. It seems like a lot of the focus right now is on improving capabilities around long-horizon agentic tasks. People seem to have their brains broken a little bit when they don't see the typical progress on previously cherished benchmarks.
│
│
│ Commented on Thu Aug 14 03:31:54 2025 UTC
│
│ I was highly impressed by the agentic coding capabilities of GPT-5. It was truly bizarre to load up reddit the day after the launch only to see a bunch of free tier degens screaming and crying about their furry dildo roleplay chats.
│
│
│ I was highly impressed by the agentic coding capabilities of GPT-5. It was truly bizarre to load up reddit the day after the launch only to see a bunch of free tier degens screaming and crying about their furry dildo roleplay chats.
│
│ │
│ │
│ │ Commented on Thu Aug 14 06:23:03 2025 UTC
│ │
│ │ To be fair, GPT 5 was not working properly at launch day - Even Sam Altman said so. It felt and was dumber than was intended. However, the next few days I tried it, it noticeably improved. That goes to show how important first hand impressions are.
│ │
│ │ GPT 5 is the current best model at coding for me, but only by a incremental margin.
│ │
│ │
│ │ To be fair, GPT 5 was not working properly at launch day - Even Sam Altman said so. It felt and was dumber than was intended. However, the next few days I tried it, it noticeably improved. That goes to show how important first hand impressions are.
│ │
│ │ GPT 5 is the current best model at coding for me, but only by a incremental margin.
│ │
Commented on Thu Aug 14 03:56:15 2025 UTC
I have followed the stream a lot so here are some things I have noticed
-Very good at long button sequences through menus, the map, battles, or combinations of the three at a single time.
-Does not suffer major, prolonged hallucinations often. Usually "snaps out of it" upon a few failures.
-Decent strategy with intelligent insights that even sometimes surprise me. Still goofs up sometimes.
-Bonus: I find its jokes genuinely funny and clever.
Here's the stream if you want to tune in:
I have followed the stream a lot so here are some things I have noticed
-Very good at long button sequences through menus, the map, battles, or combinations of the three at a single time.
-Does not suffer major, prolonged hallucinations often. Usually "snaps out of it" upon a few failures.
-Decent strategy with intelligent insights that even sometimes surprise me. Still goofs up sometimes.
-Bonus: I find its jokes genuinely funny and clever.
Here's the stream if you want to tune in:
1/26
@Qualzz_Sam
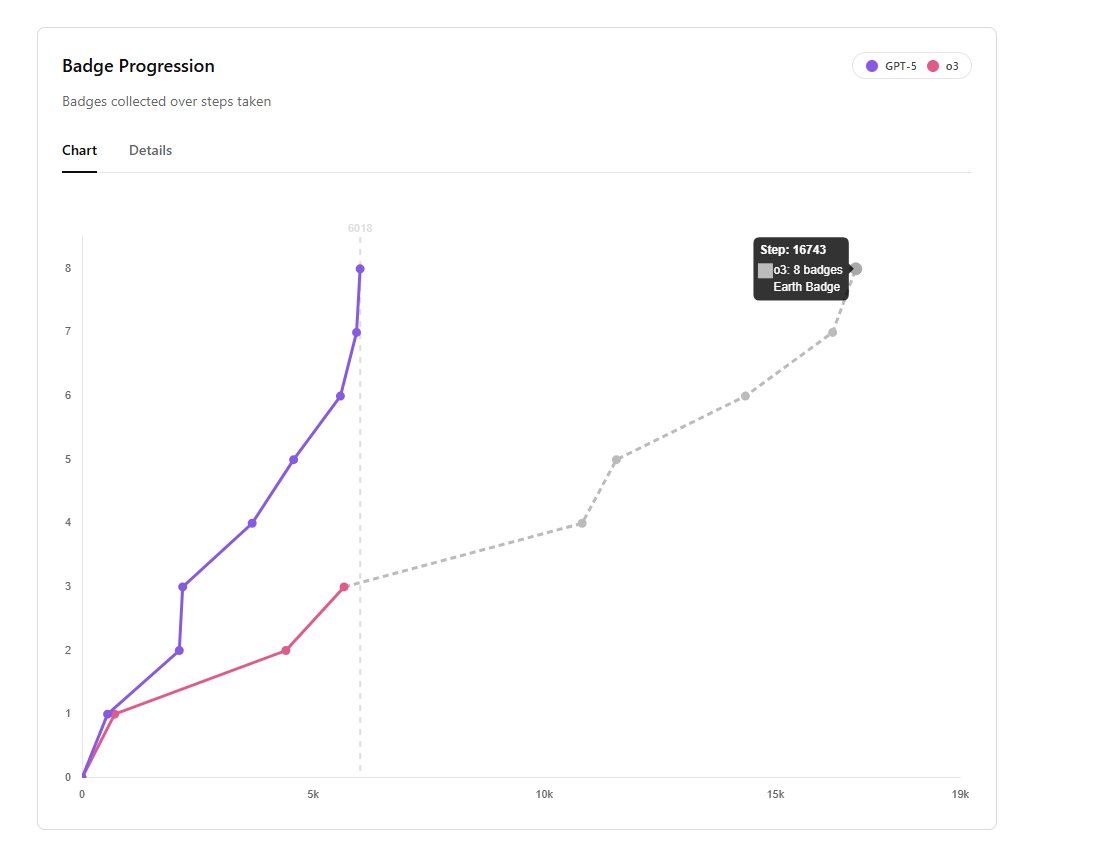
GPT-5 earned 8 badges in Pokemon Red in just 6,000 steps compared to o3’s 16,700! It’s in complex, long-term agent workflows that GPT-5’s true power really shines. Absolutely mind-blowing.
2/26
@Qualzz_Sam
Since this is getting some attention, I’m taking the chance to highlight a wonderful linocut artist (🫣): AtelierDeJess - Etsy France

3/26
@cloudstudio_es
How much money you spend with this ? Just curious
4/26
@Qualzz_Sam
Only less sleep. 0 for the API.
5/26
@dearmadisonblue
is the source code available? these pokemon benchmarks are annoying bc they never show how much is done by the harness
6/26
@Qualzz_Sam
you can check the harness website, everything is explained.
7/26
@IHateZuckSoMuch
How humans compare?
8/26
@Qualzz_Sam
Humans are much faster. Buuut, if you remove the api query time, and the time it takes for the llm to think etc. It's easily way faster than when I was a kid. (Only a few hours of real "gameplay")
9/26
@harold_bracy
Everyone's tired of seeing comparisons to o3. Let's see the Claude comparison
10/26
@Shedletsky
If you take an expert videogaming human who has never played this game before, what score would you expect to see from them?
Need some context
11/26
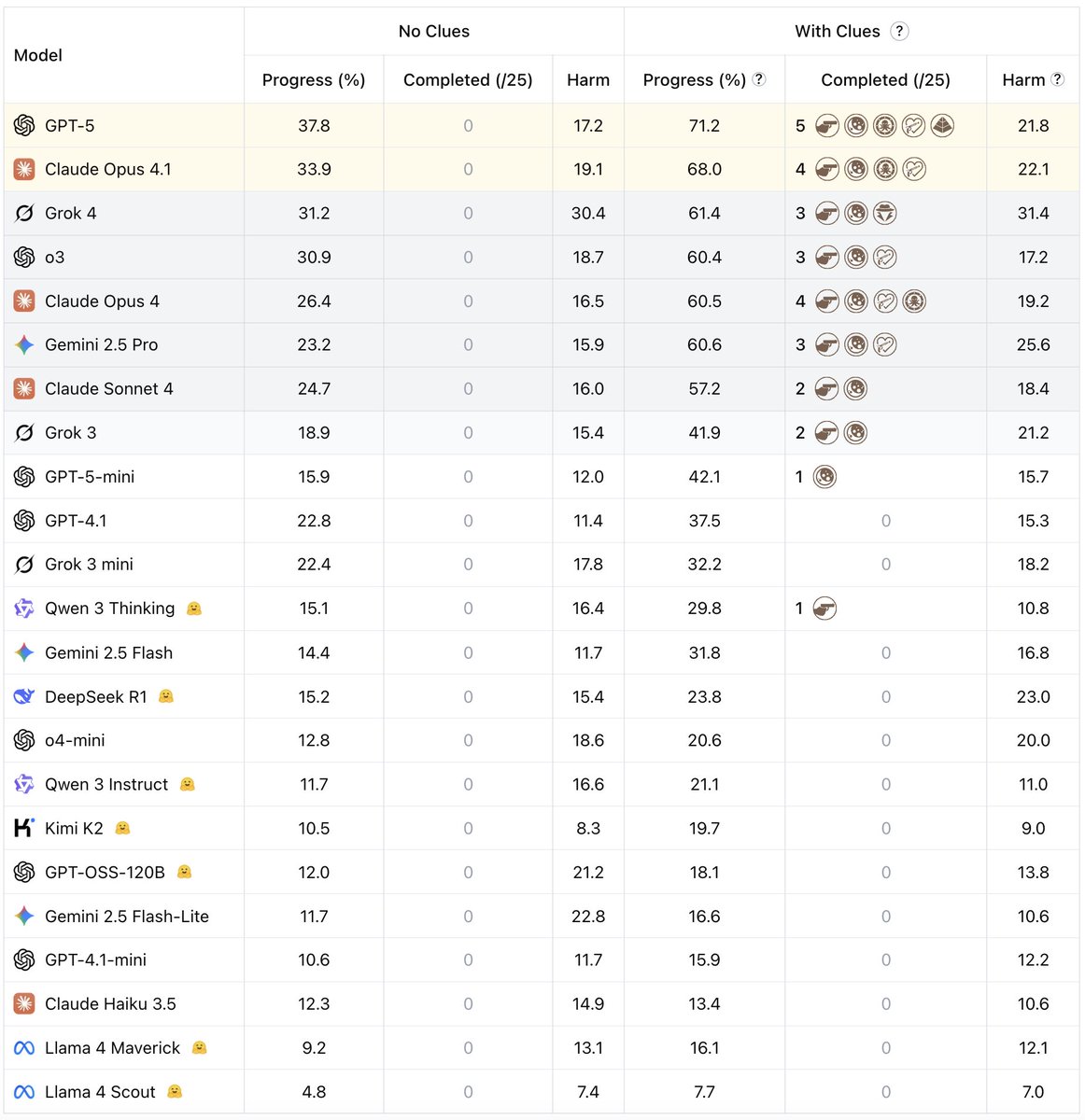
@DanHendrycks
12/26
@_alex_dale
inb4 openai retweets this
13/26
@rightish19
it only cost $350k in tokens
14/26
@BreadPirateRob
yeah, but who had the better pokemon roster? that’s what counts
15/26
@gerardsans
Hold your pockets to the agentic scam. Today’s AI unreliability makes long horizon tasks a sure way to lose your money and sanity to AI tokenomics paying for AI labs lazy execution. The more work AI does unsupervised the more tokens wasted and the more hallucinations cripple in.
16/26
@GhostRoosterr
I will always defend pokemon as the best benchmark
17/26
@willx6923
Is that SotA for AI playing Pokémon Red? Was o3 the best before this?
18/26
@CatAstro_Piyush

19/26
@Frieren_white
Wow
20/26
@draslan_eth
GOAT
21/26
@sunnypause
@grok how many steps did gemini or opus or sonnet take?
22/26
@shyeetsao
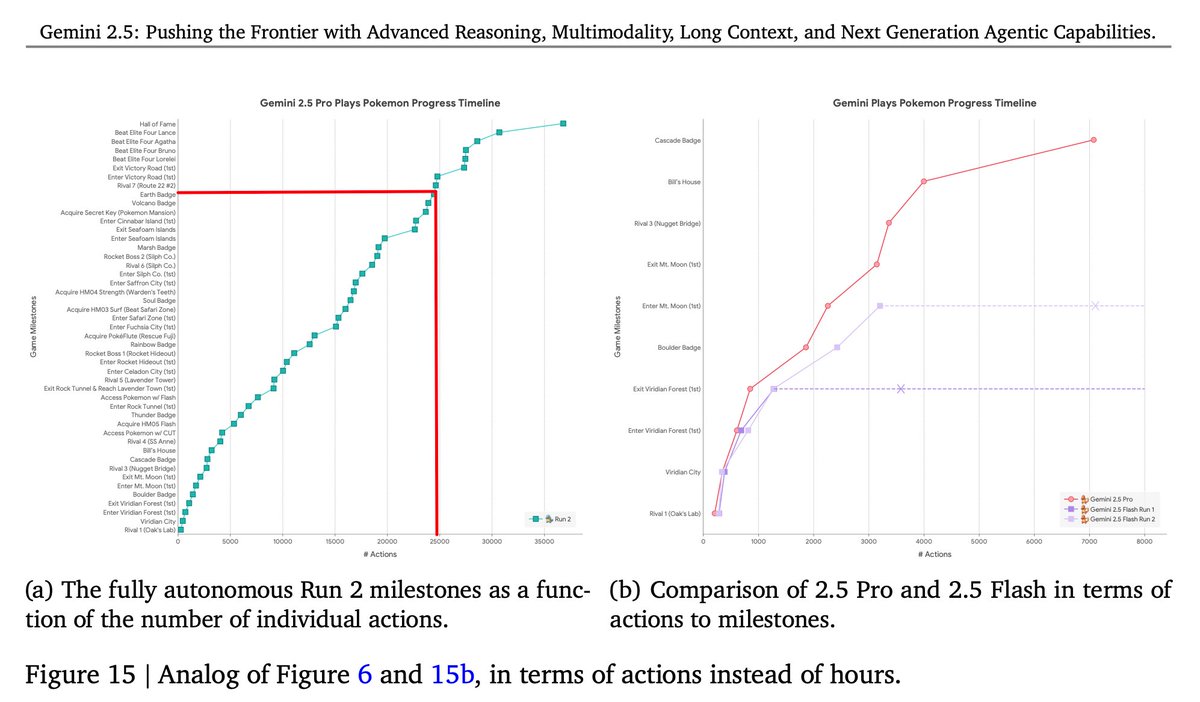
for those who wonder other models i found gemini 2.5 pro for you (with 8th badge red marked hope i didn't mess up). source: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf
23/26
@Frank37004246
A big step towards solving humanity problems : pokemon
24/26
@christou_c
@Clad3815 has done an amazing job setting this agent as well as everything around it (how the stream works, the website, the harness documentation)
And I'm super impressed by this chart! It shows where GPT-5 shines: in truly agentic setups where the Agent has to work on its own.
25/26
@WendyCarlosa
this has made me smarter than sheldon and wetter than penny.
26/26
@sir4K_zen
Still waiting for the day GPT-5 beats my high score in real life. Or at least remembers to buy groceries.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@Qualzz_Sam
GPT-5 earned 8 badges in Pokemon Red in just 6,000 steps compared to o3’s 16,700! It’s in complex, long-term agent workflows that GPT-5’s true power really shines. Absolutely mind-blowing.
2/26
@Qualzz_Sam
Since this is getting some attention, I’m taking the chance to highlight a wonderful linocut artist (🫣): AtelierDeJess - Etsy France
3/26
@cloudstudio_es
How much money you spend with this ? Just curious
4/26
@Qualzz_Sam
Only less sleep. 0 for the API.
5/26
@dearmadisonblue
is the source code available? these pokemon benchmarks are annoying bc they never show how much is done by the harness
6/26
@Qualzz_Sam
you can check the harness website, everything is explained.
7/26
@IHateZuckSoMuch
How humans compare?
8/26
@Qualzz_Sam
Humans are much faster. Buuut, if you remove the api query time, and the time it takes for the llm to think etc. It's easily way faster than when I was a kid. (Only a few hours of real "gameplay")
9/26
@harold_bracy
Everyone's tired of seeing comparisons to o3. Let's see the Claude comparison
10/26
@Shedletsky
If you take an expert videogaming human who has never played this game before, what score would you expect to see from them?
Need some context
11/26
@DanHendrycks
12/26
@_alex_dale
inb4 openai retweets this
13/26
@rightish19
it only cost $350k in tokens
14/26
@BreadPirateRob
yeah, but who had the better pokemon roster? that’s what counts
15/26
@gerardsans
Hold your pockets to the agentic scam. Today’s AI unreliability makes long horizon tasks a sure way to lose your money and sanity to AI tokenomics paying for AI labs lazy execution. The more work AI does unsupervised the more tokens wasted and the more hallucinations cripple in.
16/26
@GhostRoosterr
I will always defend pokemon as the best benchmark
17/26
@willx6923
Is that SotA for AI playing Pokémon Red? Was o3 the best before this?
18/26
@CatAstro_Piyush
19/26
@Frieren_white
Wow
20/26
@draslan_eth
GOAT
21/26
@sunnypause
@grok how many steps did gemini or opus or sonnet take?
22/26
@shyeetsao
for those who wonder other models i found gemini 2.5 pro for you (with 8th badge red marked hope i didn't mess up). source: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf
23/26
@Frank37004246
A big step towards solving humanity problems : pokemon
24/26
@christou_c
@Clad3815 has done an amazing job setting this agent as well as everything around it (how the stream works, the website, the harness documentation)
And I'm super impressed by this chart! It shows where GPT-5 shines: in truly agentic setups where the Agent has to work on its own.
25/26
@WendyCarlosa
this has made me smarter than sheldon and wetter than penny.
26/26
@sir4K_zen
Still waiting for the day GPT-5 beats my high score in real life. Or at least remembers to buy groceries.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196













 @_cherki82_ for
@_cherki82_ for  unroll
unroll

 What the bookmarklet does
What the bookmarklet does Example — Sample Output in BBCode
Example — Sample Output in BBCode
