How we reduced the cost of building Twitter at Twitter-scale by 100x
I’m going to cover a lot of ground in this post, so here’s the TLDR: We built a Twitter-scale Mastodon instance from scratch in only 10k lines of code. This is 100x less code than the ~1M lines Twi…
 blog.redplanetlabs.com
blog.redplanetlabs.com
How we reduced the cost of building Twitter at Twitter-scale by 100x
AUGUST 15, 2023 ~ NATHAN MARZI’m going to cover a lot of ground in this post, so here’s the TLDR:
- We built a Twitter-scale Mastodon instance from scratch in only 10k lines of code. This is 100x less code than the ~1M lines Twitter wrote to build and scale their original consumer product, which is very similar to Mastodon. Our instance is located at https://mastodon.redplanetlabs.com and open for anyone to use. The instance has 100M bots posting 3,500 times per second at 403 average fanout to demonstrate its scale.
- Our implementation is built on top of a new platform called Rama that we at Red Planet Labs have developed over the past 10 years. This is the first time we’re talking about Rama publicly. Rama unifies computation and storage into a coherent model capable of building end-to-end backends at any scale in 100x less code than otherwise. Rama integrates and generalizes data ingestion, processing, indexing, and querying. Rama is a generic platform for building application backends, not just for social networks, and is programmed with a pure Java API. I will be exploring Rama in this post through the example of our Mastodon implementation.
- We spent nine person-months building our scalable Mastodon instance. Twitter spent ~200 person-years to build and scale their original consumer product, and Instagram spent ~25 person-years building Threads, a recently launched Twitter competitor. In their effort Instagram was able to leverage infrastructure already powering similar products.
- Our scalable Mastodon implementation is also significantly less code than Mastodon’s official implementation, which cannot scale anywhere near Twitter-scale.
- In one week we will release a version of Rama that anyone can download and use. This version simulates Rama clusters within a single process and can be used to explore the full Rama API and build complete prototypes. We will also release the Rama documentation at that time.
- In two weeks we will fully open-source our Mastodon implementation.
- Red Planet Labs will be starting a private beta soon to give companies access to the full version of Rama. We will release more details on the private beta later, but companies can apply here in the meantime.
We recognize the way we’re introducing Rama is unusual. We felt that since the 100x cost reduction claim sounds so unbelievable, it wouldn’t do Rama justice to introduce it in the abstract. So we took it upon ourselves to directly demonstrate Rama’s 100x cost reduction by replicating a full application at scale in all its detail.
Our Mastodon instance
First off, we make no comment about whether Mastodon should be scalable. There are good reasons to limit the size of an individual Mastodon instance. It is our belief, however, that such decisions should be product decisions and not forced by technical limitations. What we are demonstrating with our scalable Mastodon instance is that building a complex application at scale doesn’t have to be a costly endeavor and can instead be easily built and managed by individuals or small teams. There’s no reason the tooling you use to most quickly build your prototype should be different from what you use to build your application at scale.
Our Mastodon instance is hosted at https://mastodon.redplanetlabs.com. We’ve implemented every feature of Mastodon from scratch, including:
- Home timelines, account timelines, local timeline, federated timeline
- Follow / unfollow
- Post / delete statuses
- Lists
- Boosts / favorites / bookmarks
- Personalized follow suggestions
- Hashtag timelines
- Featured hashtags
- Notifications
- Blocking / muting
- Conversations / direct messages
- Filters
- View followers / following in order (paginated)
- Polls
- Trending hashtags and links
- Search (status / people / hashtags)
- Profiles
- Image/video attachments
- Scheduled statuses
- ActivityPub API to integrate with other Mastodon instances
There’s huge variety between these features, and they require very different kinds of implementations for how computations are done and how indexes are structured. Of course, every single aspect of our Mastodon implementation is scalable.
To demonstrate the scale of our instance, we’re also running 100M bot accounts which continuously post statuses (Mastodon’s analogue of a “tweet”), replies, boosts (“retweet”), and favorites. 3,500 statuses are posted per second, the average number of followers for each post is 403, and the largest account has over 22M followers. As a comparison, Twitter serves 7,000 tweets per second at 700 average fanout (according to the numbers I could find). With the click of a button we can scale our instance up to handle that load or much larger – it would just cost us more money in server costs. We used the OpenAI API to generate 50,000 statuses for the bots to choose from at random.
Since our instance is just meant to demonstrate Rama and costs money to run, we’re not planning to keep it running for that long. So we don’t recommend using this instance for a primary Mastodon account.
One feature of Mastodon that needed tweaking because of our high rate of new statuses was global timelines, as it doesn’t make sense to flood the UI with thousands of new statuses per second. So for that feature we instead show a small sample of all the statuses on the platform.
The implementation of our instance looks like this:

The Mastodon backend is implemented as Rama modules (explained later on this page), which handles all the data processing, data indexing, and most of the product logic. On top of that is our implementation of the Mastodon API using Spring/Reactor. For the most part, the API implementation just handles HTTP requests with simple calls to the Rama modules and serves responses as JSON. We use Soapbox to serve the frontend since it’s built entirely on top of the Mastodon API.
S3 is used only for serving pictures and videos. Though we could serve those from Rama, static content like that is better served via a CDN. So we chose to use S3 to mimic that sort of architecture. All other storage is handled by the Rama modules.
Our implementation totals 10k lines of code, about half of which is the Rama modules and half of which is the API server. We will be fully open-sourcing the implementation in two weeks.
Our implementation is a big reduction in code compared to the official Mastodon implementation, which is built with Ruby on Rails. That codebase doesn’t always have a clear distinction between frontend and backend code, but just adding up the code for clearcut backend portions (models, workers, services, API controllers, ActivityPub) totals 18k lines of Ruby code. That doesn’t include any of the database schema definition code, configurations needed to run Postgres and Redis, or other controller code, so the true line count for the official Mastodon backend is higher than that. And unlike our Rama implementation, it can’t achieve anywhere near Twitter-scale.
This isn’t a criticism of the Mastodon codebase – building products with existing technologies is just plain expensive. The reason we’ve worked on Rama for so many years is to enable developers to build applications much faster, with much greater quality, and to never have to worry about scaling ever again.
Performance and scalability
Here’s a chart showing the scalability of the most intensive part of Mastodon, processing statuses:

As you can see, increasing the number of nodes increases the statuses/second that can be processed. Most importantly, the relationship is linear. Processing statuses is so intensive because of fanout – if you have 15M followers, each of your statuses has to be written to 15M timelines. Each status on our instance is written to an average of 403 timelines (plus additional work to handle replies, lists, and conversations).
Twitter operates at 7,000 tweets per second at 700 average fanout, which is equivalent to about 12,200 tweets / second at 403 average fanout. So you can see we tested our Mastodon instance well above Twitter-scale.
Here’s a chart showing the latency distribution for the time from a status being posted to it being available on follower timelines:
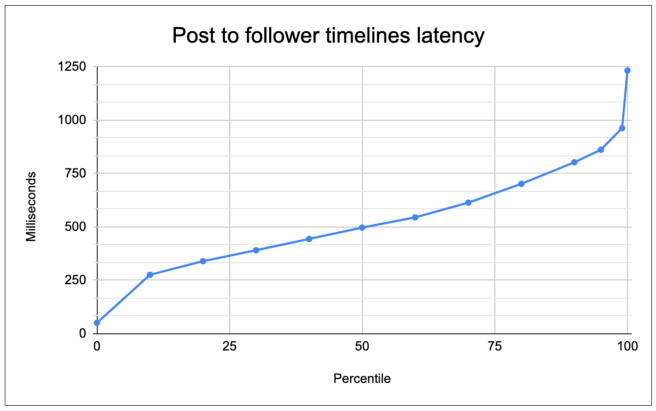
These numbers are a bit better than Twitter’s numbers. Because of how unbalanced the social graph is, getting performance this good and this reliable is not easy. For example, when someone with 20M followers posts a status, that creates a huge burst of load which could delay other statuses from fanning out. How we handled this is described more below.
Lastly, here’s a chart showing the latency distribution for fetching the data to render a user’s home timeline:

Rendering a home timeline requires a lot of data from the backend: a page of statuses to render that aren’t muted/filtered, stats on each status (number of replies, boosts, and favorites), as well as information on the accounts that posted each status (username, display name, profile pic). Getting all this done in an average of 87ms is extremely efficient and a result of Rama being such an integrated system.
Rama
The numbers I’ve shared here should be hard to believe: a Twitter-scale Mastodon implementation with extremely strong performance numbers in only 10k lines of code, which is less code than Mastodon’s current backend implementation and 100x less code than Twitter’s scalable implementation of a very similar product? How is it possible that we’ve reduced the cost of building scalable applications by multiple orders of magnitude?
You can begin to understand this by starting with a simple observation: you can describe Mastodon (or Twitter, Reddit, Slack, Gmail, Uber, etc.) in total detail in a matter of hours. It has profiles, follows, timelines, statuses, replies, boosts, hashtags, search, follow suggestions, and so on. It doesn’t take that long to describe all the actions you can take on Mastodon and what those actions do. So the real question you should be asking is: given that software is entirely abstraction and automation, why does it take so long to build something you can describe in hours?
{continue reading on site...}


 if they could it to work tho.
if they could it to work tho.