LLMs Can Now Reason in Parallel: UC Berkeley and UCSF Researchers Introduce Adaptive Parallel Reasoning to Scale Inference Efficiently Without Exceeding Context Windows

www.marktechpost.com
LLMs Can Now Reason in Parallel: UC Berkeley and UCSF Researchers Introduce Adaptive Parallel Reasoning to Scale Inference Efficiently Without Exceeding Context Windows
By
Mohammad Asjad
May 2, 2025
Large language models (LLMs) have made significant strides in reasoning capabilities, exemplified by breakthrough systems like OpenAI o1 and DeepSeekR1, which utilize test-time compute for search and reinforcement learning to optimize performance. Despite this progress, current methodologies face critical challenges that impede their effectiveness. Serialized chain-of-thought approaches generate excessively long output sequences, increasing latency and pushing against context window constraints. In contrast, parallel methods such as best-of-N and self-consistency suffer from poor coordination between inference paths and lack end-to-end optimization, resulting in computational inefficiency and limited improvement potential. Also, structured inference-time search techniques like tree-of-thought rely on manually designed search structures, significantly restricting their flexibility and ability to scale across different reasoning tasks and domains.
Several approaches have emerged to address the computational challenges in LLM reasoning. Inference-time scaling methods have improved downstream task performance by increasing test-time computation, but typically generate significantly longer output sequences. This creates higher latency and forces models to fit entire reasoning chains into a single context window, making it difficult to attend to relevant information. Parallelization strategies like ensembling have attempted to mitigate these issues by running multiple independent language model calls simultaneously. However, these methods suffer from poor coordination across parallel threads, leading to redundant computation and inefficient resource utilization. Fixed parallelizable reasoning structures, such as tree-of-thought and multi-agent reasoning systems, have been proposed, but their hand-designed search structures limit flexibility and scalability. Other approaches, like PASTA decompose tasks into parallel sub-tasks but ultimately reintegrate the complete context into the main inference trajectory, failing to reduce context usage effectively. Meanwhile, Hogwild! Inference employs parallel worker threads but relies exclusively on prompting without end-to-end optimization.
Researchers from UC Berkeley and UCSF have proposed
Adaptive Parallel Reasoning (APR) . This robust approach enables language models to dynamically distribute inference-time computation across both serial and parallel operations. This methodology generalizes existing reasoning approaches—including serialized chain-of-thought reasoning, parallelized inference with self-consistency, and structured search—by training models to determine when and how to parallelize inference operations rather than imposing fixed search structures. APR introduces two key innovations: a parent-child threading mechanism and end-to-end reinforcement learning optimization. The threading mechanism allows parent inference threads to delegate subtasks to multiple child threads through a spawn() operation, enabling parallel exploration of distinct reasoning paths. Child threads then return outcomes to the parent thread via a join() operation, allowing the parent to continue decoding with this new information. Built on the SGLang model serving framework, APR significantly reduces real-time latency by performing inference in child threads simultaneously through batching. The second innovation—fine-tuning via end-to-end reinforcement learning—optimizes for overall task success without requiring predefined reasoning structures. This approach delivers three significant advantages: higher performance within fixed context windows, superior scaling with increased compute budgets, and improved performance at equivalent latency compared to traditional methods.

The APR architecture implements a sophisticated multi-threading mechanism that enables language models to dynamically orchestrate parallel inference processes. APR addresses the limitations of serialized reasoning methods by distributing computation across parent and child threads, minimizing latency while improving performance within context constraints. The architecture consists of three key components:
First, the
multi-threading inference system allows parent threads to spawn multiple child threads using a spawn(msgs) operation. Each child thread receives a distinct context and executes inference independently, yet simultaneously using the same language model. When a child thread completes its task, it returns results to the parent via a join(msg) operation, selectively communicating only the most relevant information. This approach significantly reduces token usage by keeping intermediate search traces confined to child threads.
Second, the
training methodology employs a two-phase approach. Initially, APR utilizes supervised learning with automatically-generated demonstrations that incorporate both depth-first and breadth-first search strategies, creating hybrid search patterns. The symbolic solver creates demonstrations with parallelization, decomposing searches into multiple components that avoid context window bottlenecks during both training and inference.
Finally, the system implements
end-to-end reinforcement learning optimization with GRPO (Gradient-based Policy Optimization). During this phase, the model learns to strategically determine when and how broadly to invoke child threads, optimizing for computational efficiency and reasoning effectiveness. The model iteratively samples reasoning traces, evaluates their correctness, and adjusts parameters accordingly, ultimately learning to balance parallel exploration against context window constraints for maximum performance.

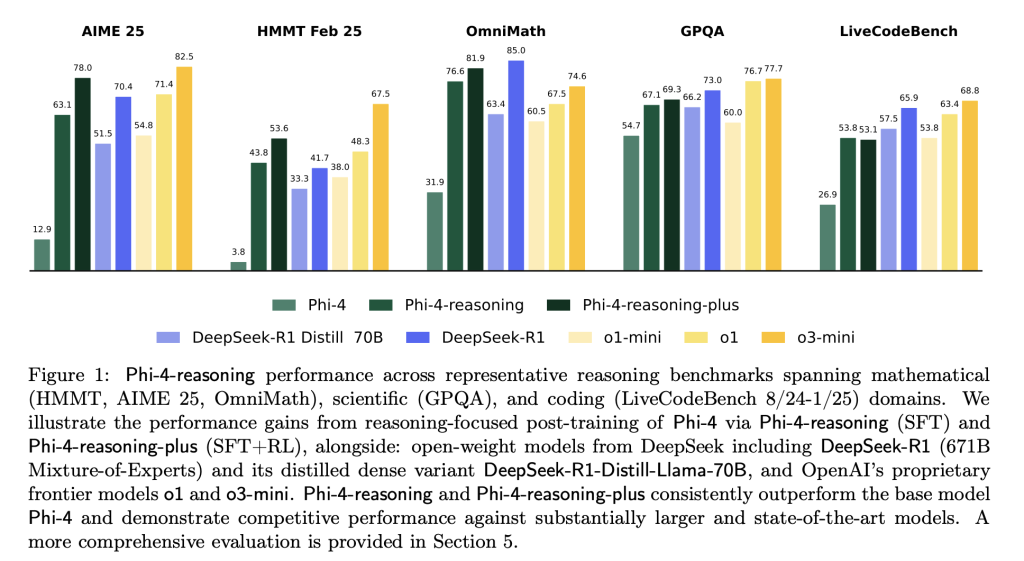
The evaluation compared Adaptive Parallel Reasoning against serialized chain-of-thought reasoning and self-consistency methods using a standard decoder-only language model with 228M parameters built on the Llama2 architecture and supporting a 4,096-token context window. All models were initialized through supervised learning on 500,000 trajectories from symbolic solvers. For direct compute-accuracy assessment, the team implemented a budget constraint method with context-window conditioning for SoS+ models and thread count conditioning for APR models. The SGLang framework was utilized for inference due to its support for continuous batching and radix attention, enabling efficient APR implementation.
Experimental results demonstrate that APR consistently outperforms serialized methods across multiple dimensions. When scaling with higher compute, APR initially underperforms in low-compute regimes due to parallelism overhead but significantly outpaces SoS+ as compute increases, achieving a 13.5% improvement at 20k tokens and surpassing SoS+ pass@8 performance while using 57.4% less compute. For context window scaling, APR consistently exploits context more efficiently, with 10 threads achieving approximately 20% higher accuracy at the 4k-token limit by distributing reasoning across parallel threads rather than containing entire traces within a single context window.

End-to-end reinforcement learning significantly enhances APR performance, boosting accuracy from 75.5% to 83.4%. The RL-optimized models demonstrate markedly different behaviors, increasing both sequence length (22.1% relative increase) and number of child threads (34.4% relative increase). This reveals that for Countdown tasks, RL-optimized models favor broader search patterns over deeper ones, demonstrating the algorithm’s ability to discover optimal search strategies autonomously.

APR demonstrates superior efficiency in both theoretical and practical evaluations. When measuring sequential token usage, APR significantly boosts accuracy with minimal additional sequential tokens beyond 2,048, rarely exceeding 2,500 tokens, while SoS+ shows only marginal improvements despite approaching 3,000 tokens. Real-world latency testing on an 8-GPU NVIDIA RTX A6000 server reveals APR achieves substantially better accuracy-latency trade-offs, reaching 75% accuracy at 5000ms per sample—an 18% absolute improvement over SoS+’s 57%. These results highlight APR’s effective hardware parallelization and potential for optimized performance in deployment scenarios.


Adaptive Parallel Reasoning represents a significant advancement in language model reasoning capabilities by enabling dynamic distribution of computation across serial and parallel paths through a parent-child threading mechanism. By combining supervised training with end-to-end reinforcement learning, APR eliminates the need for manually designed structures while allowing models to develop optimal parallelization strategies. Experimental results on the Countdown task demonstrate APR’s substantial advantages: higher performance within fixed context windows, superior scaling with increased compute budgets, and significantly improved success rates at equivalent latency constraints. These achievements highlight the potential of reasoning systems that dynamically structure inference processes to achieve enhanced scalability and efficiency in complex problem-solving tasks.
Check out the
Paper . Also, don’t forget to follow us on
Twitter and join our
Telegram Channel and
LinkedIn Gr oup . Don’t Forget to join our
90k+ ML SubReddit . For Promotion and Partnerships,
please talk us .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop

 Localized captions
Localized captions Region-specific precision
Region-specific precision Works on images AND video
Works on images AND video



 (see architecture below, authors feed both focal crops and whole image)
(see architecture below, authors feed both focal crops and whole image)





 x
x  .
.






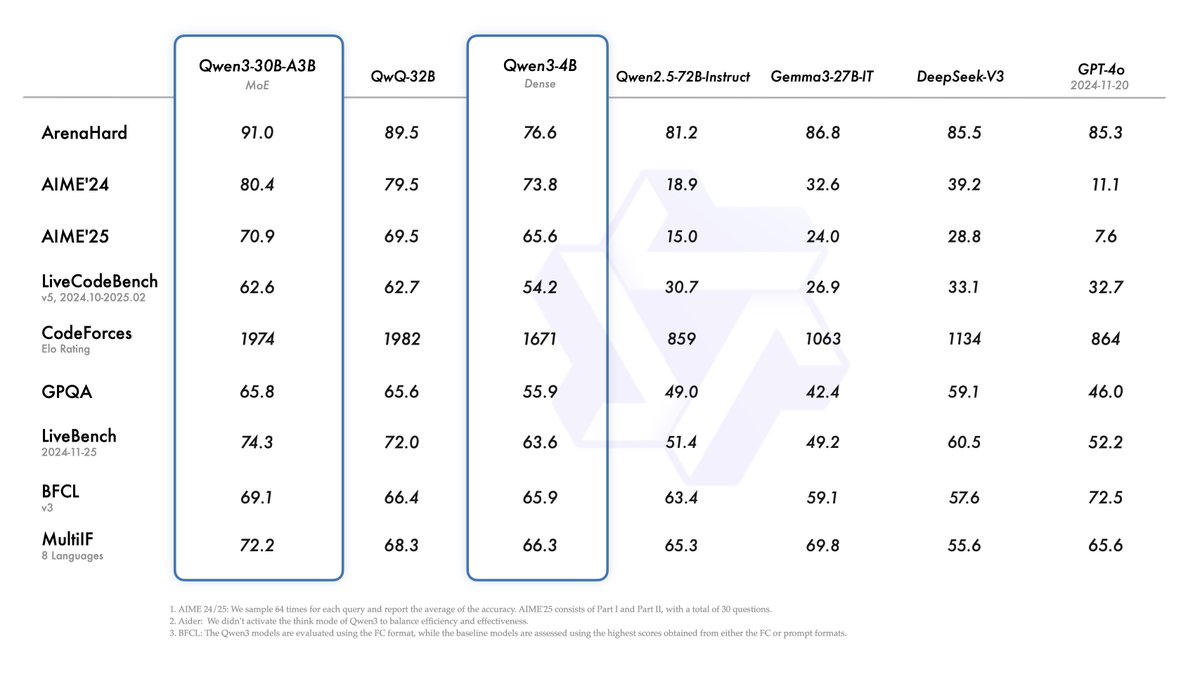





 BREAKING: Alibaba just launched "Qwen3" its most powerful AI model yet.
BREAKING: Alibaba just launched "Qwen3" its most powerful AI model yet.


 our new toys
our new toys





 Realistic Talking Videos
Realistic Talking Videos Diverse Character Styles
Diverse Character Styles Comparison with Closed-Source Methods
Comparison with Closed-Source Methods Lip Sync with Half-Body Motion
Lip Sync with Half-Body Motion Diverse Character Styles
Diverse Character Styles Diverse Characters with Full-Body Motion
Diverse Characters with Full-Body Motion FantasyTalking: Realistic Talking Portrait Generation via Coherent Motion Synthesis
FantasyTalking: Realistic Talking Portrait Generation via Coherent Motion Synthesis

 github.com
github.com

 techcrunch.com
techcrunch.com