Crome: Google DeepMind's Causal Framework for Robust Reward Modeling in LLM Alignment
Crome: Google DeepMind's Causal Framework for Robust Reward Modeling in LLM Alignment
 www.marktechpost.com
www.marktechpost.com
Crome: Google DeepMind’s Causal Framework for Robust Reward Modeling in LLM Alignment
By Sajjad Ansari
July 3, 2025
Reward models are fundamental components for aligning LLMs with human feedback, yet they face the challenge of reward hacking issues. These models focus on superficial attributes such as response length or formatting rather than identifying true quality indicators like factuality and relevance. This problem arises because standard training objectives fail to differentiate between spurious correlations present in training data and genuine causal drivers of response quality. The failure to separate these factors leads to brittle reward models (RMs) that generate misaligned policies. Moreover, there is a need for a method that utilizes a causal understanding of preference formation to train RMs that are sensitive to causal quality attributes and invariant to various spurious cues.
Limitations of Existing RM Approaches and the Need for Causal Robustness
Existing methods try to solve reward hacking issues in standard RLHF systems that rely on Bradley-Terry or pairwise ranking methods. This includes architectural modifications, such as Odin, policy-level adjustments, and data-centric methods involving ensembles or consistency checks. Recent causal-inspired methods use MMD regularization against pre-specified spurious factors or estimate causal effects through corrected rewrites. However, these methods target only predetermined spurious factors, missing unknown correlates. While augmentation strategies remain coarse, and evaluation-focused methods fail to equip reward models with robust training mechanisms against diverse spurious variations.
Introducing Crome: Causally Robust Reward Modeling for LLMs
Researchers from Google DeepMind, McGill University, and MILA – Quebec AI Institute have proposed Crome (Causally Robust Reward Modeling), a framework built on an explicit causal model of answer generation. Crome trains RMs to differentiate genuine quality drivers from superficial cues by adding preference datasets with targeted, LLM-generated counterfactual examples. Moreover, it creates two types of synthetic training pairs: (a) Causal Augmentations, which introduce changes along specific causal attributes, such as factuality to enforce sensitivity to true quality shifts, and (b) Neutral Augmentations that enforce invariance along spurious attributes like style using tie-labels. Crome enhances robustness, increasing RewardBench accuracy by up to 4.5%, enhancing safety and reasoning.
Technical Approach: Counterfactual Augmentation and Composite Loss Optimization
The Crome operates through two main phases: generating attribute-aware counterfactual data based on a causal model and training the reward model with a specialized loss on combined data. It provides a theoretical analysis on how causal augmentation isolates true reward drivers from spurious correlates under an idealized model. Crome utilizes the UltraFeedback dataset with counterfactuals generated using Gemini 2.0 Flash, and evaluates performance on RewardBench and reWordBench. Researchers utilize diverse base LLMs in their experiments, including Gemma-2-9B-IT, Qwen2.5-7B, and Gemma-2-2B for both Pairwise Preference and Bradley-Terry reward models, with downstream alignment impact through Best-of-N selection on multiple tasks.

Performance Gains: From RewardBench to WildGuardTest
On RewardBench, Crome achieves improvements in ranking accuracy over RRM across diverse base models, with significant gains in Safety (up to 13.18%) and Reasoning (up to 7.19%) categories. Crome shows aggregate accuracy gains of up to 9.1% on reWordBench with Gemma-2-9B-IT in PairPM settings and superior performance on 21 out of 23 transformations. Moreover, it shows a smaller decrease in ranking accuracy from RewardBench to reWordBench compared to RRM (19.78% versus 21.54%). Crome shows excellent safety improvements on WildGuardTest with Best-of-N selection, achieving lower attack success ratios on harmful prompts while maintaining similar refusal rates on benign prompts.
Conclusion and Future Directions in Causal Data Augmentation
In conclusion, researchers introduced Crome, a causal framework that solves reward hacking issues during RM training. It employs two targeted synthetic data augmentation strategies: Causal Augmentations and Neutral Augmentations. Crome outperforms strong baselines across multiple base models and reward modeling techniques on RewardBench, and superior robustness on reWordBench against spurious correlations. This dataset curation-centered training method (i.e, Crome) opens new research directions in synthetic data generation for base model training, where causal attribute verification could prove highly beneficial for future developments in robust language model alignment.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter .














 Read on
Read on 

 Why memory got messy
Why memory got messy
 What a MemCube holds
What a MemCube holds
 Three layers doing the heavy lifting
Three layers doing the heavy lifting
 Scheduler keeps memories fresh
Scheduler keeps memories fresh
 Numbers that prove the point
Numbers that prove the point
 KV tricks to cut wait time
KV tricks to cut wait time

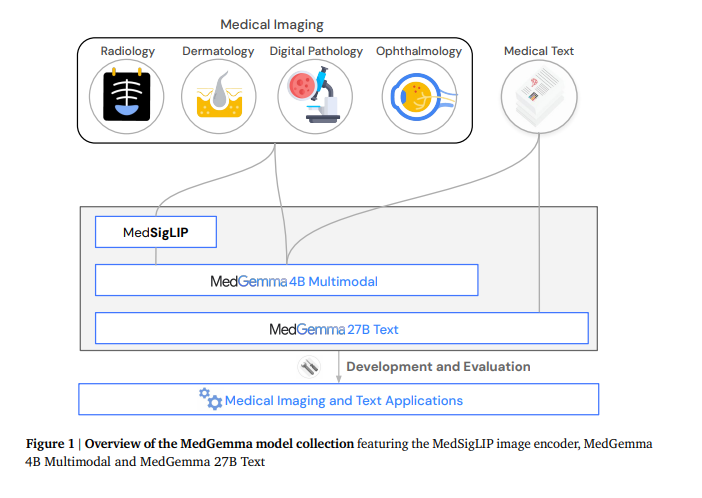
 Google Research release MedGemma 27B, multimodal health-AI models that run on 1 GPU
Google Research release MedGemma 27B, multimodal health-AI models that run on 1 GPU 

 Checks more than 200 URLs for each task.
Checks more than 200 URLs for each task. Context-aware, very long-horizon reasoning
Context-aware, very long-horizon reasoning Runs on an internal Kimi k-series backbone
Runs on an internal Kimi k-series backbone  Learns entirely through end-to-end agentic RL
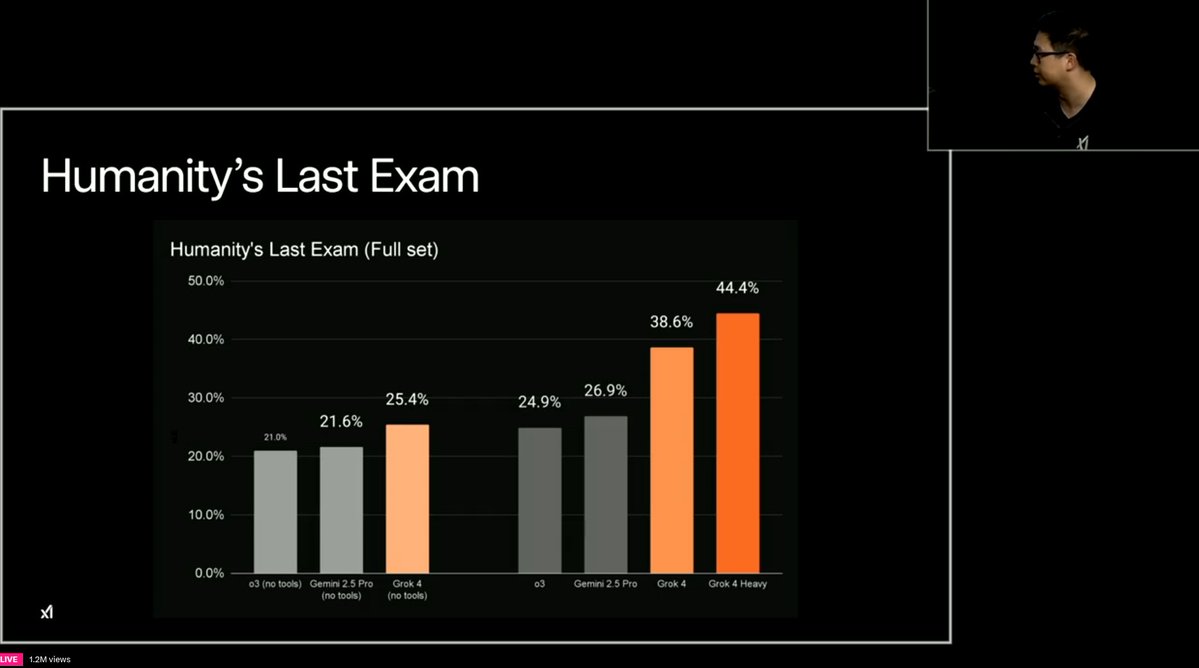
Learns entirely through end-to-end agentic RL  Achieves 26.9% pass@1 on Humanity’s Last Exam, top of the board
Achieves 26.9% pass@1 on Humanity’s Last Exam, top of the board  Scores 69% pass@1 on xbench-DeepSearch, edging past o3 with tools
Scores 69% pass@1 on xbench-DeepSearch, edging past o3 with tools  Delivers solid results on FRAMES, Seal-0, and SimpleQA
Delivers solid results on FRAMES, Seal-0, and SimpleQA  Shows that self-rewarded training can mature planning, search, and coding in one loop
Shows that self-rewarded training can mature planning, search, and coding in one loop High‑quality agent datasets are rare, so the team generated their own.
High‑quality agent datasets are rare, so the team generated their own.  Training stays on‑policy. Tool‑call format guards are switched off, so every trajectory truly reflects model probabilities.
Training stays on‑policy. Tool‑call format guards are switched off, so every trajectory truly reflects model probabilities. 
 After RL, the model averages 23 reasoning steps and checks about 200 URLs per task, reaches 69% pass@1 on xbench‑DeepSearch, and shows habits like cross‑verifying conflicting sources before answering.
After RL, the model averages 23 reasoning steps and checks about 200 URLs per task, reaches 69% pass@1 on xbench‑DeepSearch, and shows habits like cross‑verifying conflicting sources before answering.


 Blog:
Blog: