Eric Schmidt says "the computers are now self-improving, they're learning how to plan" - and soon they won't have to listen to us anymore. Within 6 years, minds smarter than the sum of humans - scaled, recursive, free. "People do not understand what's happening."

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Reasoning skills of large language models are often overestimated
- Thread starter bnew
- Start date
More options
Who Replied?Hood Critic
The Power Circle
Eric Schmidt says "the computers are now self-improving, they're learning how to plan" - and soon they won't have to listen to us anymore. Within 6 years, minds smarter than the sum of humans - scaled, recursive, free. "People do not understand what's happening."
His entire interview
1/1
@GestaltU
Hard to argue the o3+ families of models, and perhaps even Gemini 2.5 pro level models, aren’t *generally* superhuman in logical reasoning and code domains at this point.
[Quoted tweet]
o4-mini-high just solved the latest project euler problem (from 4 days ago) in 2m55s, far faster than any human solver. Only 15 people were able to solve it in under 30 minutes


To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@GestaltU
Hard to argue the o3+ families of models, and perhaps even Gemini 2.5 pro level models, aren’t *generally* superhuman in logical reasoning and code domains at this point.
[Quoted tweet]
o4-mini-high just solved the latest project euler problem (from 4 days ago) in 2m55s, far faster than any human solver. Only 15 people were able to solve it in under 30 minutes
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/16
@bio_bootloader
o4-mini-high just solved the latest project euler problem (from 4 days ago) in 2m55s, far faster than any human solver. Only 15 people were able to solve it in under 30 minutes
2/16
@bio_bootloader
I'm stunned
I knew this day was coming but wow. I used to regularly solve these and sometimes came in the top 10 solvers, I know how hard these are.
3/16
@bio_bootloader
turns out it sometimes solves this in under a minute:
[Quoted tweet]
Okay, not sure what I did differently than you, but I got CoT time down to 56s with the right answer.
What was the prompt you used?


4/16
@RyanJTopps
You do know the answer is known and it’s not executing any code in that response right?
5/16
@bio_bootloader
wrong
6/16
@GuilleAngeris
yeah ok that's pretty sick actually
7/16
@yacineMTB
cool
8/16
@nayshins
Dang
9/16
@gnopercept
is it so over?
10/16
@friendlyboxcat
Boggles me that it can do that but not connect 4

11/16
@CDS61617
code moving different
12/16
@DrMiaow
Still can’t label code correctly.

13/16
@sadaasukhi
damn
14/16
@plutobyte
for the record, gemini 2.5 pro solved it in 6 minutes. i haven't looked super closely at the problem or either of their solutions, but it looks like it be just be a matrix exponentiation by squaring problem? still very impressive
15/16
@BenceDezs3
I also had a few test problems from SPOJ that very few of us could solve, and they definitely weren’t in the training data. Unfortunately (or perhaps fortunately), the day came when it managed to solve every single one of them.
16/16
@Scarcus
Just a matter of compute now for time, what I want to know is how many tokens it took to solve it.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@bio_bootloader
o4-mini-high just solved the latest project euler problem (from 4 days ago) in 2m55s, far faster than any human solver. Only 15 people were able to solve it in under 30 minutes
2/16
@bio_bootloader
I'm stunned
I knew this day was coming but wow. I used to regularly solve these and sometimes came in the top 10 solvers, I know how hard these are.
3/16
@bio_bootloader
turns out it sometimes solves this in under a minute:
[Quoted tweet]
Okay, not sure what I did differently than you, but I got CoT time down to 56s with the right answer.
What was the prompt you used?
4/16
@RyanJTopps
You do know the answer is known and it’s not executing any code in that response right?
5/16
@bio_bootloader
wrong
6/16
@GuilleAngeris
yeah ok that's pretty sick actually
7/16
@yacineMTB
cool
8/16
@nayshins
Dang
9/16
@gnopercept
is it so over?
10/16
@friendlyboxcat
Boggles me that it can do that but not connect 4
11/16
@CDS61617
code moving different
12/16
@DrMiaow
Still can’t label code correctly.
13/16
@sadaasukhi
damn
14/16
@plutobyte
for the record, gemini 2.5 pro solved it in 6 minutes. i haven't looked super closely at the problem or either of their solutions, but it looks like it be just be a matrix exponentiation by squaring problem? still very impressive
15/16
@BenceDezs3
I also had a few test problems from SPOJ that very few of us could solve, and they definitely weren’t in the training data. Unfortunately (or perhaps fortunately), the day came when it managed to solve every single one of them.
16/16
@Scarcus
Just a matter of compute now for time, what I want to know is how many tokens it took to solve it.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
LLMs Can Now Solve Challenging Math Problems with Minimal Data: Researchers from UC Berkeley and Ai2 Unveil a Fine-Tuning Recipe That Unlocks Mathematical Reasoning Across Difficulty Levels
LLMs Can Now Solve Challenging Math Problems with Minimal Data: Researchers from UC Berkeley and Ai2 Unveil a Fine-Tuning Recipe That Unlocks Mathematical Reasoning Across Difficulty Levels
 www.marktechpost.com
www.marktechpost.com
LLMs Can Now Solve Challenging Math Problems with Minimal Data: Researchers from UC Berkeley and Ai2 Unveil a Fine-Tuning Recipe That Unlocks Mathematical Reasoning Across Difficulty Levels
By Mohammad Asjad
April 18, 2025
Language models have made significant strides in tackling reasoning tasks, with even small-scale supervised fine-tuning (SFT) approaches such as LIMO and s1 demonstrating remarkable improvements in mathematical problem-solving capabilities. However, fundamental questions remain about these advancements: Do these models genuinely generalise beyond their training data, or are they merely overfitting to test sets? The research community faces challenges in understanding which capabilities are enhanced through small-scale SFT and which limitations persist despite these improvements. Despite impressive performance on popular benchmarks, there is an incomplete understanding of these fine-tuned models’ specific strengths and weaknesses, creating a critical gap in knowledge about their true reasoning abilities and practical limitations.
Various attempts have been made to understand the effects of reasoning-based supervised fine-tuning beyond simple benchmark scores. Researchers have questioned whether SFT merely improves performance on previously seen problem types or genuinely enables models to transfer problem-solving strategies to new contexts, such as applying coordinate-based techniques in geometry. Existing methods focus on factors like correctness, solution length, and response diversity, which initial studies suggest play significant roles in model improvement through SFT. However, these approaches lack the granularity needed to determine exactly which types of previously unsolvable questions become solvable after fine-tuning, and which problem categories remain resistant to improvement despite extensive training. The research community still struggles to establish whether observed improvements reflect deeper learning or simply memorisation of training trajectories, highlighting the need for more sophisticated analysis methods.
The researchers from the University of California, Berkeley and the Allen Institute for AI propose a tiered analysis framework to investigate how supervised fine-tuning affects reasoning capabilities in language models. This approach utilises the AIME24 dataset, chosen for its complexity and widespread use in reasoning research, which exhibits a ladder-like structure where models solving higher-tier questions typically succeed on lower-tier ones. By categorising questions into four difficulty tiers, Easy, Medium, Hard, and Exh, the study systematically examines the specific requirements for advancing between tiers. The analysis reveals that progression from Easy to Medium primarily requires adopting an R1 reasoning style with long inference context, while Hard-level questions demand greater computational stability during deep exploration. Exh-level questions present a fundamentally different challenge, requiring unconventional problem-solving strategies that current models uniformly struggle with. The research also identifies four key insights: the performance gap between potential and stability in small-scale SFT models, minimal benefits from careful dataset curation, diminishing returns from scaling SFT datasets, and potential intelligence barriers that may not be overcome through SFT alone.

The methodology employs a comprehensive tiered analysis using the AIME24 dataset as the primary test benchmark. This choice stems from three key attributes: the dataset’s hierarchical difficulty that challenges even state-of-the-art models, its diverse coverage of mathematical domains, and its focus on high school mathematics that isolates pure reasoning ability from domain-specific knowledge. Qwen2.5-32 B-Instruct serves as the base model due to its widespread adoption and inherent cognitive behaviours, including verification, backtracking, and subgoal setting. The fine-tuning data consists of question-response pairs from the Openr1-Math-220k dataset, specifically using CoT trajectories generated by DeepSeek R1 for problems from NuminaMath1.5, with incorrect solutions filtered out. The training configuration mirrors prior studies with a learning rate of 1 × 10−5, weight decay of 1 × 10−4, batch size of 32, and 5 epochs. Performance evaluation employs avg@n (average pass rate over multiple attempts) and cov@n metrics, with questions categorised into four difficulty levels (Easy, Medium, Hard, and Extremely Hard) based on model performance patterns.
Research results reveal that effective progression from Easy to Medium-level mathematical problem-solving requires minimal but specific conditions. The study systematically examined multiple training variables, including foundational knowledge across diverse mathematical categories, dataset size variations (100-1000 examples per category), trajectory length (short, normal, or long), and trajectory style (comparing DeepSeek-R1 with Gemini-flash). Through comprehensive ablation studies, researchers isolated the impact of each dimension on model performance, represented as P = f(C, N, L, S), where C represents category, N represents the number of trajectories, L represents length, and S represents style. The findings demonstrate that achieving performance ≥90% on Medium-level questions minimally requires at least 500 normal or long R1-style trajectories, regardless of the specific mathematical category. Models consistently fail to meet performance thresholds when trained with fewer trajectories, shorter trajectories, or Gemini-style trajectories. This indicates that reasoning trajectory length and quantity represent critical factors in developing mathematical reasoning capabilities, while the specific subject matter of the trajectories proves less important than their structural characteristics.


The research demonstrates that models with small-scale supervised fine-tuning can potentially solve as many questions as more sophisticated models like Deepseek-R1, though significant challenges remain. The primary limitation identified is instability in mathematical reasoning, rather than capability. Experimental results show that geometry-trained models can achieve a coverage score of 90, matching R1’s performance when given multiple attempts, yet their overall accuracy lags by more than 20%. This performance gap stems primarily from instability in deep exploration and computational limitations during complex problem-solving. While increasing the SFT dataset size offers one solution path, performance enhancement follows a logarithmic scaling trend with diminishing returns. Notably, the study challenges recent assertions about the importance of careful dataset curation, revealing that performance across various mathematical categories remains consistent within a narrow range of 55±4%, with only marginal differences between specifically constructed similar datasets and randomly constructed ones. This conclusion suggests that the quantity and quality of reasoning trajectories matter more than subject-specific content for developing robust mathematical reasoning capabilities.
Here is the Paper and GitHub Page . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
LLMs Can Now Reason Beyond Language: Researchers Introduce Soft Thinking to Replace Discrete Tokens with Continuous Concept Embeddings
LLMs Can Now Reason Beyond Language: Researchers Introduce Soft Thinking to Replace Discrete Tokens with Continuous Concept Embeddings
www.marktechpost.com
LLMs Can Now Reason Beyond Language: Researchers Introduce Soft Thinking to Replace Discrete Tokens with Continuous Concept Embeddings
By Sana Hassan
May 27, 2025
Human reasoning naturally operates through abstract, non-verbal concepts rather than strictly relying on discrete linguistic tokens. However, current LLMs are limited to reasoning within the boundaries of natural language, producing one token at a time through predefined vocabulary. This token-by-token approach not only restricts the expressive capacity of the model but also limits the breadth of reasoning paths it can explore, especially in ambiguous or complex scenarios. Standard Chain-of-Thought (CoT) methods exemplify this limitation, forcing the model to commit to a single path at each step. In contrast, human cognition is more flexible and parallel, allowing for simultaneous consideration of multiple ideas and delaying verbalization until concepts are fully formed. This makes human reasoning more adaptable and robust in dealing with uncertainty.
To address these limitations, researchers have proposed transitioning from token-based reasoning to reasoning within a continuous concept space, representing reasoning steps as token embeddings combinations. This approach allows models to explore multiple reasoning trajectories in parallel and integrate richer conceptual representations. Prior studies have demonstrated the potential of manipulating hidden states to influence reasoning outcomes or introduce latent planning. However, applying continuous-space reasoning to larger models presents challenges. In models under 7B parameters, shared weights between input and output layers allow hidden states to align with token embeddings, facilitating continuous reasoning. However, in larger models, where input and output spaces are decoupled, directly using hidden states as inputs causes mismatches that are hard to resolve. Attempts to retrain these models to bridge this gap often result in overfitting or degraded performance, highlighting the difficulty of enabling effective continuous reasoning at scale.
Partner with us to speak at the AI Infrastructure miniCON Virtual Event (Aug 2, 2025)
Researchers from the University of California, Santa Barbara, University of California, Santa Cruz, University of California, Los Angeles, Purdue University, LMSYS Org, and Microsoft introduce Soft Thinking. This training-free approach enhances reasoning in large language models by operating in a continuous concept space. Instead of choosing one discrete token at each step, the model generates concept tokens—probability-weighted mixtures of all token embeddings—enabling parallel reasoning over multiple paths. This results in richer, more abstract representations. The method includes a Cold Stop mechanism to improve efficiency. Evaluations on mathematical and coding tasks show up to 2.48% higher accuracy and 22.4% fewer tokens used than standard Chain-of-Thought reasoning.
The Soft Thinking method enhances standard CoT reasoning by replacing discrete token sampling with concept tokens—probability distributions over the entire vocabulary. These distributions compute weighted embeddings, allowing the model to reason in a continuous concept space. This preserves uncertainty and enables parallel exploration of multiple reasoning paths. A Cold Stop mechanism monitors entropy to halt reasoning when the model becomes confident, improving efficiency and preventing collapse. Theoretical analysis shows that Soft Thinking approximates the full marginalization over all reasoning paths through linearization, offering a more expressive and computationally tractable alternative to discrete CoT.
Recommended open-source AI alignment framework: Parlant — Control LLM agent behavior in customer-facing interactions (Promoted)
The study evaluates the Soft Thinking method on eight benchmarks in math and programming using three open-source LLMs of varying sizes and architectures. Compared to standard and greedy CoT methods, Soft Thinking consistently improves accuracy (Pass@1) while significantly reducing the number of tokens generated, indicating more efficient reasoning. The approach uses concept tokens and a Cold Start controller without modifying model weights or requiring extra training. Experiments show that soft thinking balances higher accuracy with lower computational cost, outperforming baselines by enabling richer, more abstract reasoning in fewer steps across diverse tasks and models.

In conclusion, Soft Thinking is a training-free approach that enables large language models to reason using continuous concept tokens instead of traditional discrete tokens. By combining weighted token embeddings, Soft Thinking allows models to explore multiple reasoning paths simultaneously, improving accuracy and efficiency. Tested on math and coding benchmarks, it consistently boosts pass@1 accuracy while reducing the number of generated tokens, all without extra training or architectural changes. The method maintains interpretability and concise reasoning. Future research may focus on training adaptations to enhance robustness, especially for out-of-distribution inputs. The code is publicly accessible.
Check out thePaperandGitHub Page. All credit for this research goes to the researchers of this project.
Incorrect Answers Improve Math Reasoning? Reinforcement Learning with Verifiable Rewards (RLVR) Surprises with Qwen2.5-Math
Incorrect Answers Improve Math Reasoning? Reinforcement Learning with Verifiable Rewards (RLVR) Surprises with Qwen2.5-Math
www.marktechpost.com
Incorrect Answers Improve Math Reasoning? Reinforcement Learning with Verifiable Rewards (RLVR) Surprises with Qwen2.5-Math
By Asif Razzaq
May 28, 2025
In natural language processing (NLP), RL methods, such as reinforcement learning with human feedback (RLHF), have been utilized to enhance model outputs by optimizing responses based on feedback signals. A specific variant, reinforcement learning with verifiable rewards (RLVR), extends this approach by utilizing automatic signals, such as mathematical correctness or syntactic features, as feedback, enabling the large-scale tuning of language models. RLVR is especially interesting because it promises to enhance models’ reasoning abilities without needing extensive human supervision. This intersection of automated feedback and reasoning tasks forms an exciting area of research, where developers aim to uncover how models can learn to reason mathematically, logically, or structurally using limited supervision.
A persistent challenge in machine learning is building models that can reason effectively under minimal or imperfect supervision. In tasks like mathematical problem-solving, where the correct answer might not be immediately available, researchers grapple with how to guide a model’s learning. Models often learn from ground-truth data, but it’s impractical to label vast datasets with perfect accuracy, particularly in reasoning tasks that require understanding complex structures like proofs or programmatic steps. Consequently, there’s an open question about whether models can learn to reason if they are exposed to noisy, misleading, or even incorrect signals during training. This issue is significant because models that overly rely on perfect feedback may not generalize well when such supervision is unavailable, thereby limiting their utility in real-world scenarios.
Partner with us to speak at the AI Infrastructure miniCON Virtual Event (Aug 2, 2025)
Several existing techniques aim to enhance models’ reasoning abilities through reinforcement learning (RL), with RLVR being a key focus. Traditionally, RLVR has used “ground truth” labels, correct answers verified by humans or automated tools, to provide rewards during training. Some approaches have relaxed this requirement by using majority vote labels or simple format-based heuristics, such as rewarding answers that follow a specific output style. Other methods have experimented with random rewards, offering positive signals without considering the correctness of the answer. These methods aim to explore whether models can learn even with minimal guidance, but they mostly concentrate on specific models, such as Qwen, raising concerns about generalizability across different architectures.
Researchers from the University of Washington, the Allen Institute for AI, and UC Berkeley investigate this question by testing various reward signals on Qwen2.5-Math, a family of large language models fine-tuned for mathematical reasoning. They tested ground-truth rewards, majority-vote rewards, format rewards based on boxed expressions, random rewards, and incorrect rewards. Remarkably, they observed that even completely spurious signals, like random rewards and rewards for wrong answers, could lead to substantial performance gains in Qwen models. For example, training Qwen2.5-Math-7B on MATH-500 with ground-truth rewards yielded a 28.8% improvement, while using incorrect labels resulted in a 24.6% gain. Random rewards still produced a 21.4% boost, and format rewards led to a 16.4% improvement. Majority-vote rewards provided a 26.5% accuracy gain. These improvements were not limited to a single model; Qwen2.5-Math-1.5B also showed strong gains: format rewards boosted accuracy by 17.6%, and incorrect labels by 24.4%. However, the same reward strategies failed to deliver similar benefits on other model families, such as Llama3 and OLMo2, which showed minimal or negative changes when trained with spurious rewards. For instance, Llama3.1-8B saw performance drops of up to 8.5% under certain spurious signals, highlighting the model-specific nature of the observed improvements.
Recommended open-source AI alignment framework: Parlant — Control LLM agent behavior in customer-facing interactions (Promoted)

The research team’s approach involved using RLVR training to fine-tune models with these varied reward signals, replacing the need for ground-truth supervision with heuristic or randomized feedback. They found that Qwen models, even without access to correct answers, could still learn to produce high-quality reasoning outputs. A key insight was that Qwen models tended to exhibit a distinct behavior called “code reasoning”, generating math solutions structured like code, particularly in Python-like formats, regardless of whether the reward signal was meaningful. This code reasoning tendency became more frequent over training, rising from 66.7% to over 90% in Qwen2.5-Math-7B when trained with spurious rewards. Answers that included code reasoning showed higher accuracy rates, often around 64%, compared to just 29% for answers without such reasoning patterns. These patterns emerged consistently, suggesting that spurious rewards may unlock latent capabilities learned during pretraining rather than introducing new reasoning skills.

Performance data underscored the surprising robustness of Qwen models. Gains from random rewards (21.4% on MATH-500) and incorrect labels (24.6%) nearly matched the ground-truth reward gain of 28.8%. Similar trends appeared across tasks, such as AMC, where format, wrong, and random rewards produced around an 18% improvement, only slightly lower than the 25% improvement from ground-truth or majority-vote rewards. Even on AIME2024, spurious rewards like format (+13.0%), incorrect (+8.7%), and random (+6.3%) led to meaningful gains, though the advantage of ground-truth labels (+12.8%) remained evident, particularly for AIME2025 questions created after model pretraining cutoffs.

Several Key Takeaways from the research include:
- Qwen2.5-Math-7B gained 28.8% accuracy on MATH-500 with ground-truth rewards, but also 24.6% with incorrect rewards, 21.4% with random rewards, 16.4% with format rewards, and 26.5% with majority-vote rewards.
- Code reasoning patterns emerged in Qwen models, increasing from 66.7% to 90%+ under RLVR, which boosted accuracy from 29% to 64%.
- Non-Qwen models, such as Llama3 and OLMo2, did not show similar improvements, with Llama3.1-8B experiencing up to 8.5% performance drops on spurious rewards.
- Gains from spurious signals appeared within 50 training steps in many cases, suggesting rapid elicitation of reasoning abilities.
- The research warns that RLVR studies should avoid generalizing results based on Qwen models alone, as spurious reward effectiveness is not universal.
In conclusion, these findings suggest that while Qwen models can leverage spurious signals to improve performance, the same is not true for other model families. Non-Qwen models, such as Llama3 and OLMo2, showed flat or negative performance changes when trained with spurious signals. The research emphasizes the importance of validating RLVR methods on diverse models rather than relying solely on Qwen-centric results, as many recent papers have done.
Check out thePaper,Official ReleaseandGitHub Page. All credit for this research goes to the researchers of this project. /\
[LLM News] Apple has countered the hype

1/24
@RubenHssd
BREAKING: Apple just proved AI "reasoning" models like Claude, DeepSeek-R1, and o3-mini don't actually reason at all.
They just memorize patterns really well.
Here's what Apple discovered:
(hint: we're not as close to AGI as the hype suggests)

2/24
@RubenHssd
Instead of using the same old math tests that AI companies love to brag about, Apple created fresh puzzle games.
They tested Claude Thinking, DeepSeek-R1, and o3-mini on problems these models had never seen before.
The result ↓
3/24
@RubenHssd
All "reasoning" models hit a complexity wall where they completely collapse to 0% accuracy.
No matter how much computing power you give them, they can't solve harder problems.

4/24
@RubenHssd
As problems got harder, these "thinking" models actually started thinking less.
They used fewer tokens and gave up faster, despite having unlimited budget.
5/24
@RubenHssd
Apple researchers even tried giving the models the exact solution algorithm.
Like handing someone step-by-step instructions to bake a cake.
The models still failed at the same complexity points.
They can't even follow directions consistently.
6/24
@RubenHssd
The research revealed three regimes:
• Low complexity: Regular models actually win
• Medium complexity: "Thinking" models show some advantage
• High complexity: Everything breaks down completely
Most problems fall into that third category.
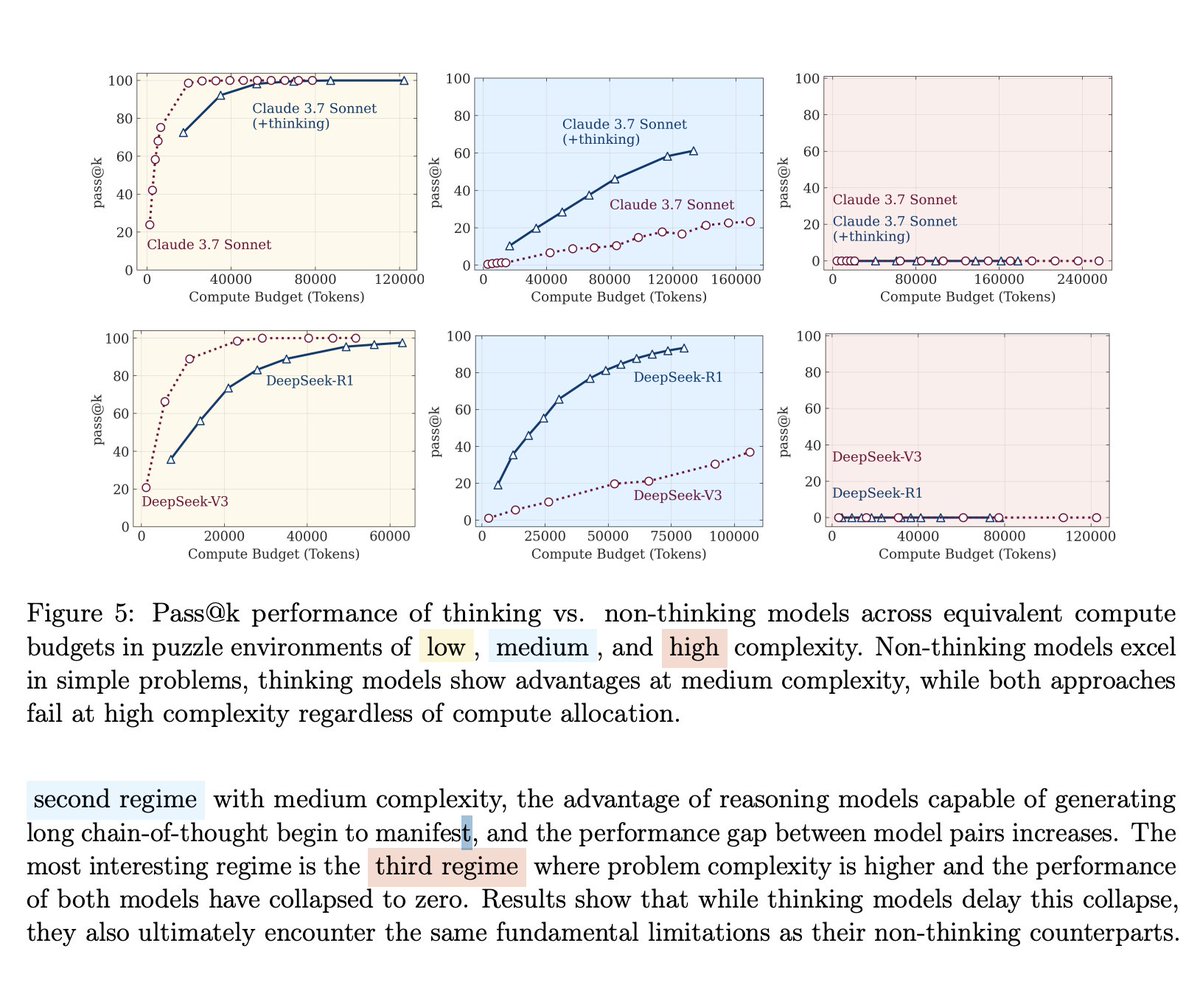
7/24
@RubenHssd
Apple discovered that these models are not reasoning at all, but instead doing sophisticated pattern matching that works great until patterns become too complex.
Then they fall apart like a house of cards.
8/24
@RubenHssd
If these models were truly "reasoning," they should get better with more compute and clearer instructions.
Instead, they hit hard walls and start giving up.
Is that intelligence or memorization hitting its limits?
9/24
@RubenHssd
This research suggests we're not as close to AGI as the hype suggests.
Current "reasoning" breakthroughs may be hitting fundamental walls that can't be solved by just adding more data or compute.
10/24
@RubenHssd
Models could handle 100+ moves in Tower of Hanoi puzzles but failed after just 4 moves in River Crossing puzzles.
This suggests they memorized Tower of Hanoi solutions during training but can't actually reason.

11/24
@RubenHssd
While AI companies celebrate their models "thinking," Apple basically said "Everyone's celebrating fake reasoning."
The industry is chasing metrics that don't measure actual intelligence.
12/24
@RubenHssd
Apple's researchers used controllable puzzle environments specifically because:
• They avoid data contamination
• They require pure logical reasoning
• They can scale complexity precisely
• They reveal where models actually break
Smart experimental design if you ask me.
13/24
@RubenHssd
What do you think?
Is Apple just "coping" because they've been outpaced in AI developments over the past two years?
Or is Apple correct?
Comment below and I'll respond to all.
14/24
@RubenHssd
If you found this thread valuable:
1. Follow me @RubenHssd for more threads around what's happening around AI and it's implications.
2. RT the first tweet
[Quoted tweet]
BREAKING: Apple just proved AI "reasoning" models like Claude, DeepSeek-R1, and o3-mini don't actually reason at all.
They just memorize patterns really well.
Here's what Apple discovered:
(hint: we're not as close to AGI as the hype suggests)
15/24
@VictorTaelin
I have a lot to say about this but I'm in a hospital right now. In short - this is a very well written paper that is undeniably correct, and makes a point that is obvious to anyone in the area. LLMs are *not* reasoning. They're more like a humanity-wide, cross-programming-language, global hash-consing or sorts. That is extremely powerful and will advance many areas, but it *not* going to result in AGI. That said, what most miss is the real lesson taught by LLMs: massive compute, added to an otherwise simple algorithm, wields immense power and utility. I don't know why people fail to see this obvious message, but the next big thing is obviously going to be companies that realize this very lesson and use that to build entirely new things that can take advantage of massive scale.
16/24
@PrestonPysh
Kinda rich coming from Apple don’t ya think?
17/24
@zayn4pf
good thread man
18/24
@FrankSchuil
Paperclip optimizers will still go a long way.
19/24
@sypen231984
Didn’t Anthropic already prove this
20/24
@dohko_01
AI is not capable of abstract thought.. it’s just pattern matching on steroids
21/24
@sifisobiya


22/24
@thepowerofozone
That should have been obvious to anyone who used AI for longer than 5 minutes.
23/24
@thepsironi
That is obvious, not much of a discovery.
24/24
@dgt10011
Whether AGI is here or not is irrelevant. What’s important is that I’ve seen enough with my own eyes to know there’s going to be tons of labor replacement and the social contract will be completely upended sooner than we think.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@RubenHssd
BREAKING: Apple just proved AI "reasoning" models like Claude, DeepSeek-R1, and o3-mini don't actually reason at all.
They just memorize patterns really well.
Here's what Apple discovered:
(hint: we're not as close to AGI as the hype suggests)
2/24
@RubenHssd
Instead of using the same old math tests that AI companies love to brag about, Apple created fresh puzzle games.
They tested Claude Thinking, DeepSeek-R1, and o3-mini on problems these models had never seen before.
The result ↓
3/24
@RubenHssd
All "reasoning" models hit a complexity wall where they completely collapse to 0% accuracy.
No matter how much computing power you give them, they can't solve harder problems.
4/24
@RubenHssd
As problems got harder, these "thinking" models actually started thinking less.
They used fewer tokens and gave up faster, despite having unlimited budget.
5/24
@RubenHssd
Apple researchers even tried giving the models the exact solution algorithm.
Like handing someone step-by-step instructions to bake a cake.
The models still failed at the same complexity points.
They can't even follow directions consistently.
6/24
@RubenHssd
The research revealed three regimes:
• Low complexity: Regular models actually win
• Medium complexity: "Thinking" models show some advantage
• High complexity: Everything breaks down completely
Most problems fall into that third category.
7/24
@RubenHssd
Apple discovered that these models are not reasoning at all, but instead doing sophisticated pattern matching that works great until patterns become too complex.
Then they fall apart like a house of cards.
8/24
@RubenHssd
If these models were truly "reasoning," they should get better with more compute and clearer instructions.
Instead, they hit hard walls and start giving up.
Is that intelligence or memorization hitting its limits?
9/24
@RubenHssd
This research suggests we're not as close to AGI as the hype suggests.
Current "reasoning" breakthroughs may be hitting fundamental walls that can't be solved by just adding more data or compute.
10/24
@RubenHssd
Models could handle 100+ moves in Tower of Hanoi puzzles but failed after just 4 moves in River Crossing puzzles.
This suggests they memorized Tower of Hanoi solutions during training but can't actually reason.
11/24
@RubenHssd
While AI companies celebrate their models "thinking," Apple basically said "Everyone's celebrating fake reasoning."
The industry is chasing metrics that don't measure actual intelligence.
12/24
@RubenHssd
Apple's researchers used controllable puzzle environments specifically because:
• They avoid data contamination
• They require pure logical reasoning
• They can scale complexity precisely
• They reveal where models actually break
Smart experimental design if you ask me.
13/24
@RubenHssd
What do you think?
Is Apple just "coping" because they've been outpaced in AI developments over the past two years?
Or is Apple correct?
Comment below and I'll respond to all.
14/24
@RubenHssd
If you found this thread valuable:
1. Follow me @RubenHssd for more threads around what's happening around AI and it's implications.
2. RT the first tweet
[Quoted tweet]
BREAKING: Apple just proved AI "reasoning" models like Claude, DeepSeek-R1, and o3-mini don't actually reason at all.
They just memorize patterns really well.
Here's what Apple discovered:
(hint: we're not as close to AGI as the hype suggests)
15/24
@VictorTaelin
I have a lot to say about this but I'm in a hospital right now. In short - this is a very well written paper that is undeniably correct, and makes a point that is obvious to anyone in the area. LLMs are *not* reasoning. They're more like a humanity-wide, cross-programming-language, global hash-consing or sorts. That is extremely powerful and will advance many areas, but it *not* going to result in AGI. That said, what most miss is the real lesson taught by LLMs: massive compute, added to an otherwise simple algorithm, wields immense power and utility. I don't know why people fail to see this obvious message, but the next big thing is obviously going to be companies that realize this very lesson and use that to build entirely new things that can take advantage of massive scale.
16/24
@PrestonPysh
Kinda rich coming from Apple don’t ya think?
17/24
@zayn4pf
good thread man
18/24
@FrankSchuil
Paperclip optimizers will still go a long way.
19/24
@sypen231984
Didn’t Anthropic already prove this
20/24
@dohko_01
AI is not capable of abstract thought.. it’s just pattern matching on steroids
21/24
@sifisobiya
22/24
@thepowerofozone
That should have been obvious to anyone who used AI for longer than 5 minutes.
23/24
@thepsironi
That is obvious, not much of a discovery.
24/24
@dgt10011
Whether AGI is here or not is irrelevant. What’s important is that I’ve seen enough with my own eyes to know there’s going to be tons of labor replacement and the social contract will be completely upended sooner than we think.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/15
@alex_prompter
 BREAKING: Apple says LLMs that "think" are giving us an illusion.
BREAKING: Apple says LLMs that "think" are giving us an illusion.
They're just pattern-matching with confidence.
And when things get complex? They collapse.
This paper might be the most honest take on AI yet :
:
2/15
@alex_prompter
1/ Apple researchers tested “reasoning LLMs” using logic puzzles with controlled complexity.
These models use chain-of-thought to solve problems step-by-step.
But when things get hard?
Their performance crashes.

3/15
@alex_prompter
2/ At first, adding more steps helps.
LLMs reason more and do better — up to a point.
Then it reverses.
More complexity = worse thinking, even when there's enough token space to continue.

4/15
@alex_prompter
3/ This is the illusion:
These models seem intelligent because they follow thought-like patterns.
But the paper shows these traces collapse under complexity.
They're not thinking. They're pattern matching.

5/15
@alex_prompter
4/ The study breaks LLM behavior into 3 zones:
• Low-complexity: vanilla models > reasoning models
• Medium: reasoning models shine
• High-complexity: both fail catastrophically

6/15
@alex_prompter
5/ Here's the shocking bit:
Reasoning LLMs often don’t use real algorithms. They improvise.
So when the problem’s too tough?
They stop trying and guess - confidently.
That’s hallucination at scale.

7/15
@alex_prompter
6/ Apple used a clever setup to test this:
Puzzles with fixed logic but variable complexity.
This let them see how models reason — not just whether they’re right.
The result: models explore erratically and don’t learn structure.

8/15
@alex_prompter
7/ Think about it:
You're watching someone solve a puzzle, and they explain each step.
Looks smart, right?
Now imagine they're just making it up as they go.
That’s what LLMs do under pressure.

9/15
@alex_prompter
8/ The paper calls it what it is:
“The illusion of thinking.”
Chain-of-thought gives us confidence, not competence.
The longer the trace, the more we believe it’s smart.
Even when it’s wrong.

10/15
@alex_prompter
9/ And that’s why hallucinations persist.
Not because models don’t know enough.
But because they’re confident guessers — not actual reasoners.
It’s a structural flaw.

11/15
@alex_prompter
10/ Apple’s experiments expose the real ceiling:
You can’t fix deep reasoning by just giving models more tokens.
It’s not a bandwidth problem.
It’s a cognitive illusion.
12/15
@alex_prompter
11/ This changes the game for AI believers.
Do we double down on mimicking thought?
Or build models that actually understand?
Because the gap is bigger than it looks.
13/15
@alex_prompter
12/ If you're interested to read more, here's the full paper:
 The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity -
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity -
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
14/15
@alex_prompter
The AI prompt library your competitors don't want you to find
→ Unlimited prompts: $150 lifetime or $15/month
→ Starter pack: $3.99/month
→ Pro bundle: $9.99/month
Grab it before it's gone
Pricing - God of Prompt
15/15
@alex_prompter
That's a wrap! If you found this useful:
1/ Follow me @alex_prompter for more AI tips.
2/ Like & RT this post:
[Quoted tweet]
BREAKING: Apple says LLMs that "think" are giving us an illusion.
They're just pattern-matching with confidence.
And when things get complex? They collapse.
This paper might be the most honest take on AI yet:
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@alex_prompter
BREAKING: Apple says LLMs that "think" are giving us an illusion.They're just pattern-matching with confidence.
And when things get complex? They collapse.
This paper might be the most honest take on AI yet
:2/15
@alex_prompter
1/ Apple researchers tested “reasoning LLMs” using logic puzzles with controlled complexity.
These models use chain-of-thought to solve problems step-by-step.
But when things get hard?
Their performance crashes.
3/15
@alex_prompter
2/ At first, adding more steps helps.
LLMs reason more and do better — up to a point.
Then it reverses.
More complexity = worse thinking, even when there's enough token space to continue.
4/15
@alex_prompter
3/ This is the illusion:
These models seem intelligent because they follow thought-like patterns.
But the paper shows these traces collapse under complexity.
They're not thinking. They're pattern matching.
5/15
@alex_prompter
4/ The study breaks LLM behavior into 3 zones:
• Low-complexity: vanilla models > reasoning models
• Medium: reasoning models shine
• High-complexity: both fail catastrophically
6/15
@alex_prompter
5/ Here's the shocking bit:
Reasoning LLMs often don’t use real algorithms. They improvise.
So when the problem’s too tough?
They stop trying and guess - confidently.
That’s hallucination at scale.
7/15
@alex_prompter
6/ Apple used a clever setup to test this:
Puzzles with fixed logic but variable complexity.
This let them see how models reason — not just whether they’re right.
The result: models explore erratically and don’t learn structure.
8/15
@alex_prompter
7/ Think about it:
You're watching someone solve a puzzle, and they explain each step.
Looks smart, right?
Now imagine they're just making it up as they go.
That’s what LLMs do under pressure.
9/15
@alex_prompter
8/ The paper calls it what it is:
“The illusion of thinking.”
Chain-of-thought gives us confidence, not competence.
The longer the trace, the more we believe it’s smart.
Even when it’s wrong.
10/15
@alex_prompter
9/ And that’s why hallucinations persist.
Not because models don’t know enough.
But because they’re confident guessers — not actual reasoners.
It’s a structural flaw.
11/15
@alex_prompter
10/ Apple’s experiments expose the real ceiling:
You can’t fix deep reasoning by just giving models more tokens.
It’s not a bandwidth problem.
It’s a cognitive illusion.
12/15
@alex_prompter
11/ This changes the game for AI believers.
Do we double down on mimicking thought?
Or build models that actually understand?
Because the gap is bigger than it looks.
13/15
@alex_prompter
12/ If you're interested to read more, here's the full paper:
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity - The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
14/15
@alex_prompter
The AI prompt library your competitors don't want you to find
→ Unlimited prompts: $150 lifetime or $15/month
→ Starter pack: $3.99/month
→ Pro bundle: $9.99/month
Grab it before it's gone
Pricing - God of Prompt
15/15
@alex_prompter
That's a wrap! If you found this useful:
1/ Follow me @alex_prompter for more AI tips.
2/ Like & RT this post:
[Quoted tweet]
BREAKING: Apple says LLMs that "think" are giving us an illusion.They're just pattern-matching with confidence.
And when things get complex? They collapse.
This paper might be the most honest take on AI yet
:To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

AI can't solve these puzzles that take humans only seconds
Discover why some puzzles stump supersmart AIs but are easy for humans, what this reveals about the quest for true artificial general intelligence — and why video games are the next frontier.
AI can't solve these puzzles that take humans only seconds
Interviews
By Deni Ellis Béchard published 20 hours ago
Discover why some puzzles stump supersmart AIs but are easy for humans, what this reveals about the quest for true artificial general intelligence — and why video games are the next frontier.
When you purchase through links on our site, we may earn an affiliate commission. Here’s how it works.
(Image credit: Flavio Coelho via Getty Images)
There are many ways to test the intelligence of an artificial intelligence — conversational fluidity, reading comprehension or mind-bendingly difficult physics. But some of the tests that are most likely to stump AIs are ones that humans find relatively easy, even entertaining. Though AIs increasingly excel at tasks that require high levels of human expertise, this does not mean that they are close to attaining artificial general intelligence, or AGI. AGI requires that an AI can take a very small amount of information and use it to generalize and adapt to highly novel situations. This ability, which is the basis for human learning, remains challenging for AIs.
One test designed to evaluate an AI's ability to generalize is the Abstraction and Reasoning Corpus, or ARC: a collection of tiny, colored-grid puzzles that ask a solver to deduce a hidden rule and then apply it to a new grid. Developed by AI researcher François Chollet in 2019, it became the basis of the ARC Prize Foundation, a nonprofit program that administers the test — now an industry benchmark used by all major AI models. The organization also develops new tests and has been routinely using two (ARC-AGI-1 and its more challenging successor ARC-AGI-2). This week the foundation is launching ARC-AGI-3, which is specifically designed for testing AI agents — and is based on making them play video games.
Scientific American spoke to ARC Prize Foundation president, AI researcher and entrepreneur Greg Kamradt to understand how these tests evaluate AIs, what they tell us about the potential for AGI and why they are often challenging for deep-learning models even though many humans tend to find them relatively easy. Links to try the tests are at the end of the article.
You may like
-
 AI outsmarted 30 of the world's top mathematicians at secret meeting in California
AI outsmarted 30 of the world's top mathematicians at secret meeting in California
-
 Cutting-edge AI models from OpenAI and DeepSeek undergo 'complete collapse' when problems get too difficult, study reveals
Cutting-edge AI models from OpenAI and DeepSeek undergo 'complete collapse' when problems get too difficult, study reveals
-
 Scientists just developed a new AI modeled on the human brain — it's outperforming LLMs like ChatGPT at reasoning tasks
Scientists just developed a new AI modeled on the human brain — it's outperforming LLMs like ChatGPT at reasoning tasks
[An edited transcript of the interview follows.]
What definition of intelligence is measured by ARC-AGI-1?
Our definition of intelligence is your ability to learn new things. We already know that AI can win at chess. We know they can beat Go. But those models cannot generalize to new domains; they can't go and learn English. So what François Chollet made was a benchmark called ARC-AGI — it teaches you a mini skill in the question, and then it asks you to demonstrate that mini skill. We're basically teaching something and asking you to repeat the skill that you just learned. So the test measures a model's ability to learn within a narrow domain. But our claim is that it does not measure AGI because it's still in a scoped domain [in which learning applies to only a limited area]. It measures that an AI can generalize, but we do not claim this is AGI.
How are you defining AGI here?
There are two ways I look at it. The first is more tech-forward, which is 'Can an artificial system match the learning efficiency of a human?' Now what I mean by that is after humans are born, they learn a lot outside their training data. In fact, they don't really have training data, other than a few evolutionary priors. So we learn how to speak English, we learn how to drive a car, and we learn how to ride a bike — all these things outside our training data. That's called generalization. When you can do things outside of what you've been trained on now, we define that as intelligence. Now, an alternative definition of AGI that we use is when we can no longer come up with problems that humans can do and AI cannot — that's when we have AGI. That's an observational definition. The flip side is also true, which is as long as the ARC Prize or humanity in general can still find problems that humans can do but AI cannot, then we do not have AGI. One of the key factors about François Chollet's benchmark... is that we test humans on them, and the average human can do these tasks and these problems, but AI still has a really hard time with it. The reason that's so interesting is that some advanced AIs, such as Grok, can pass any graduate-level exam or do all these crazy things, but that's spiky intelligence. It still doesn't have the generalization power of a human. And that's what this benchmark shows.
How do your benchmarks differ from those used by other organizations?
One of the things that differentiates us is that we require that our benchmark to be solvable by humans. That's in opposition to other benchmarks, where they do "Ph.D.-plus-plus" problems. I don't need to be told that AI is smarter than me — I already know that OpenAI's o3 can do a lot of things better than me, but it doesn't have a human's power to generalize. That's what we measure on, so we need to test humans. We actually tested 400 people on ARC-AGI-2. We got them in a room, we gave them computers, we did demographic screening, and then gave them the test. The average person scored 66 percent on ARC-AGI-2. Collectively, though, the aggregated responses of five to 10 people will contain the correct answers to all the questions on the ARC2.
What makes this test hard for AI and relatively easy for humans?
There are two things. Humans are incredibly sample-efficient with their learning, meaning they can look at a problem and with maybe one or two examples, they can pick up the mini skill or transformation and they can go and do it. The algorithm that's running in a human's head is orders of magnitude better and more efficient than what we're seeing with AI right now.
What is the difference between ARC-AGI-1 and ARC-AGI-2?
So ARC-AGI-1, François Chollet made that himself. It was about 1,000 tasks. That was in 2019. He basically did the minimum viable version in order to measure generalization, and it held for five years because deep learning couldn't touch it at all. It wasn't even getting close. Then reasoning models that came out in 2024, by OpenAI, started making progress on it, which showed a step-level change in what AI could do. Then, when we went to ARC-AGI-2, we went a little bit further down the rabbit hole in regard to what humans can do and AI cannot. It requires a little bit more planning for each task. So instead of getting solved within five seconds, humans may be able to do it in a minute or two. There are more complicated rules, and the grids are larger, so you have to be more precise with your answer, but it's the same concept, more or less.... We are now launching a developer preview for ARC-AGI-3, and that's completely departing from this format. The new format will actually be interactive. So think of it more as an agent benchmark.
How will ARC-AGI-3 test agents differently compared with previous tests?
If you think about everyday life, it's rare that we have a stateless decision. When I say stateless, I mean just a question and an answer. Right now all benchmarks are more or less stateless benchmarks. If you ask a language model a question, it gives you a single answer. There's a lot that you cannot test with a stateless benchmark. You cannot test planning. You cannot test exploration. You cannot test intuiting about your environment or the goals that come with that. So we're making 100 novel video games that we will use to test humans to make sure that humans can do them because that's the basis for our benchmark. And then we're going to drop AIs into these video games and see if they can understand this environment that they've never seen beforehand. To date, with our internal testing, we haven't had a single AI be able to beat even one level of one of the games.
Can you describe the video games here?
Each "environment," or video game, is a two-dimensional, pixel-based puzzle. These games are structured as distinct levels, each designed to teach a specific mini skill to the player (human or AI). To successfully complete a level, the player must demonstrate mastery of that skill by executing planned sequences of actions.
How is using video games to test for AGI different from the ways that video games have previously been used to test AI systems?
Video games have long been used as benchmarks in AI research, with Atari games being a popular example. But traditional video game benchmarks face several limitations. Popular games have extensive training data publicly available, lack standardized performance evaluation metrics and permit brute-force methods involving billions of simulations. Additionally, the developers building AI agents typically have prior knowledge of these games — unintentionally embedding their own insights into the solutions.
Try ARC-AGI-1, ARC-AGI-2 and ARC-AGI-3.
This article was first published at Scientific American. © ScientificAmerican.com.