1/37
@alexwei_
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
2/37
@alexwei_
2/N We evaluated our models on the 2025 IMO problems under the same rules as human contestants: two 4.5 hour exam sessions, no tools or internet, reading the official problem statements, and writing natural language proofs.
3/37
@alexwei_
3/N Why is this a big deal? First, IMO problems demand a new level of sustained creative thinking compared to past benchmarks. In reasoning time horizon, we’ve now progressed from GSM8K (~0.1 min for top humans) → MATH benchmark (~1 min) → AIME (~10 mins) → IMO (~100 mins).
4/37
@alexwei_
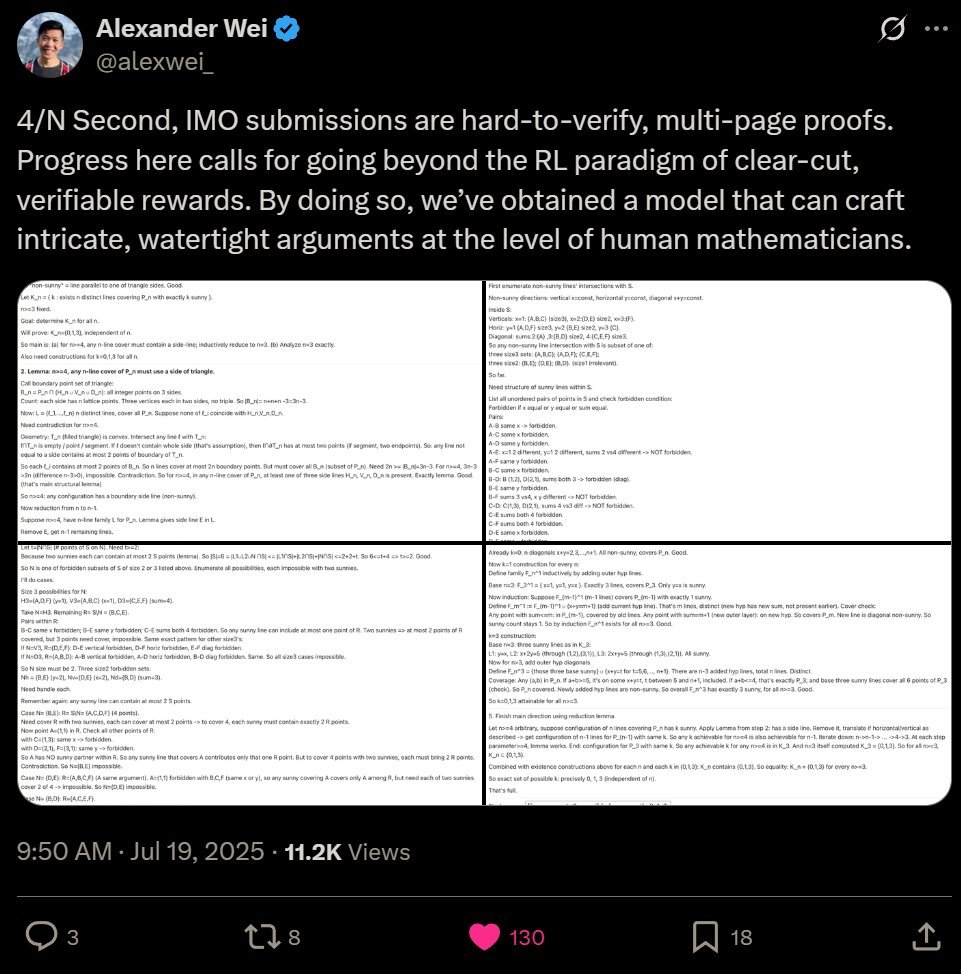
4/N Second, IMO submissions are hard-to-verify, multi-page proofs. Progress here calls for going beyond the RL paradigm of clear-cut, verifiable rewards. By doing so, we’ve obtained a model that can craft intricate, watertight arguments at the level of human mathematicians.
5/37
@alexwei_
5/N Besides the result itself, I am excited about our approach: We reach this capability level not via narrow, task-specific methodology, but by breaking new ground in general-purpose reinforcement learning and test-time compute scaling.
6/37
@alexwei_
6/N In our evaluation, the model solved 5 of the 6 problems on the 2025 IMO. For each problem, three former IMO medalists independently graded the model’s submitted proof, with scores finalized after unanimous consensus. The model earned 35/42 points in total, enough for gold!

7/37
@alexwei_
7/N HUGE congratulations to the team—@SherylHsu02, @polynoamial, and the many giants whose shoulders we stood on—for turning this crazy dream into reality! I am lucky I get to spend late nights and early mornings working alongside the very best.
8/37
@alexwei_
8/N Btw, we are releasing GPT-5 soon, and we’re excited for you to try it. But just to be clear: the IMO gold LLM is an experimental research model. We don’t plan to release anything with this level of math capability for several months.
9/37
@alexwei_
9/N Still—this underscores how fast AI has advanced in recent years. In 2021, my PhD advisor @JacobSteinhardt had me forecast AI math progress by July 2025. I predicted 30% on the MATH benchmark (and thought everyone else was too optimistic). Instead, we have IMO gold.
10/37
@alexwei_
10/N If you want to take a look, here are the model’s solutions to the 2025 IMO problems! The model solved P1 through P5; it did not produce a solution for P6. (Apologies in advance for its … distinct style—it is very much an experimental model

)
GitHub - aw31/openai-imo-2025-proofs
11/37
@alexwei_
11/N Lastly, we'd like to congratulate all the participants of the 2025 IMO on their achievement! We are proud to have many past IMO participants at @OpenAI and recognize that these are some of the brightest young minds of the future.
12/37
@burny_tech
Soooo what is the breakthrough?
>"Progress here calls for going beyond the RL paradigm of clear-cut, verifiable rewards. By doing so, we’ve obtained a model that can craft intricate, watertight arguments at the level of human mathematicians."
>"We reach this capability level not via narrow, task-specific methodology, but by breaking new ground in general-purpose reinforcement learning and test-time compute scaling."
13/37
@burny_tech
so let me get this straight
their model basically competed live on IMO so all the mathematical tasks should be novel enough
all previous years IMO tasks in benchmarks are fully saturated in big part because of data contamination as it doesn't generalize to these new ones
so... this new model seems to... generalize well to novel enough mathematical tasks??? i dont know what to think
14/37
@AlbertQJiang
Congratulations!
15/37
@geo58928
Amazing
16/37
@burny_tech
So public AI models are bad at IMO, while internal models are getting gold medals? Fascinating
17/37
@mhdfaran
@grok who was on second and third
18/37
@QuanquanGu
Congrats, this is incredible results!
Quick question: did it use Lean, or just LLM?
If it’s just LLM… that’s insane.
19/37
@AISafetyMemes
So what's the next goalpost?
What's the next thing LLMs will never be able to do?
20/37
@kimmonismus
Absolutely fantastic
21/37
@CtrlAltDwayne
pretty impressive. is this the anonymous chatbot we're seeing on webdev arena by chance?
22/37
@burny_tech
lmao
23/37
@jack_w_rae
Congratulations! That's an incredible result, and a great moment for AI progress. You guys should release the model
24/37
@Kyrannio
Incredible work.
25/37
@burny_tech
Sweet Bitter lesson
26/37
@burny_tech
"We developed new techniques that make LLMs a lot better at hard-to-verify tasks."
A general method? Or just for mathematical proofs? Is Lean somehow used, maybe just in training?
27/37
@elder_plinius
28/37
@skominers

29/37
@javilopen
Hey @GaryMarcus, what are your thoughts about this?
30/37
@pr0me
crazy feat, congrats!
nice that you have published the data on this
31/37
@danielhanchen
Impressive!
32/37
@IamEmily2050
Congratulations

33/37
@burny_tech
Step towards mathematical superintelligence
34/37
@reach_vb
Massive feat! I love how concise and to the point the generations are unlike majority of LLMs open/ closed alike

35/37
@DCbuild3r
Congratulations!
36/37
@DoctorYev
I just woke up and this post has 1M views after a few hours.
AI does not sleep.
37/37
@AndiBunari1
@grok summarize this and simple to understand
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196








 Those seem like pretty obvious "problems" to pop up if a system is beginning to advance rapidly.
Those seem like pretty obvious "problems" to pop up if a system is beginning to advance rapidly.











 Design faster matrix multiplication algorithms
Design faster matrix multiplication algorithms LLMs: To synthesize information about problems as well as previous attempts to solve them - and to propose new versions of algorithms
LLMs: To synthesize information about problems as well as previous attempts to solve them - and to propose new versions of algorithms
 Optimize data center scheduling
Optimize data center scheduling , geometry
, geometry  , combinatorics
, combinatorics  and number theory
and number theory  , including the kissing number problem.
, including the kissing number problem.