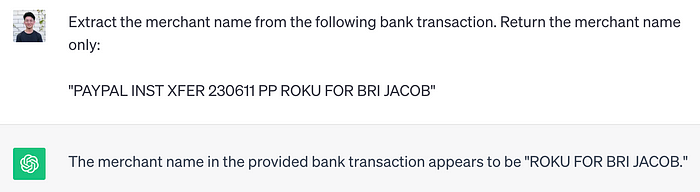
In payments, understanding transactions is crucial for assessing risks in businesses. However, deciphering messy bank transaction data poses a challenge, as it is expressed in various ways across different banks. Existing solutions like Plaid and ChatGPT have limitations, such as low coverage...

www.marktechpost.com
Meet Slope TransFormer: A Large Language Model (LLM) Trained Specifically to Understand the Language of Banks
In payments, understanding transactions is crucial for assessing risks in businesses. However, deciphering messy bank transaction data poses a challenge, as it is expressed in various ways across different banks. Existing solutions like Plaid and ChatGPT have limitations, such as low coverage and wordiness. To address this, a new solution called Slope TransFormer has been developed—a Large Language Model (LLM) specifically trained to understand the language of banks.
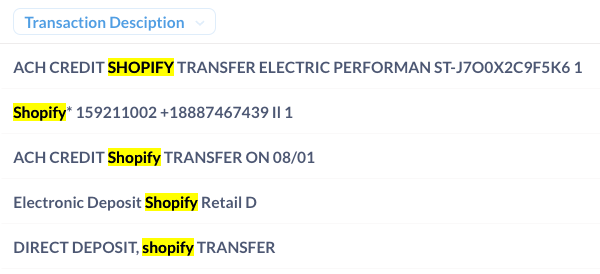
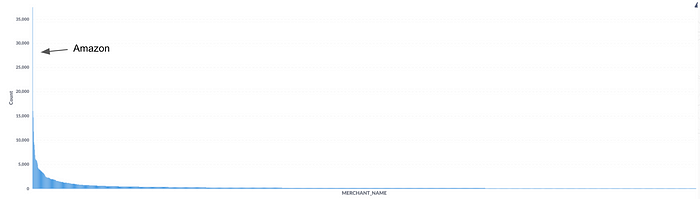
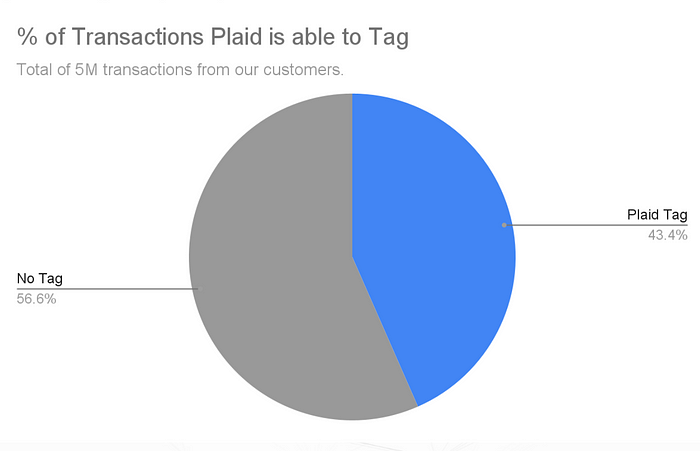
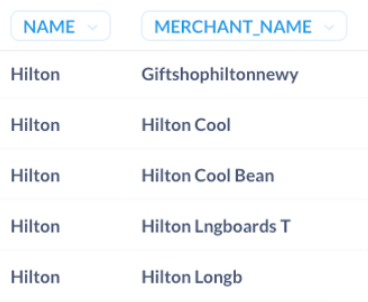
Transactions are challenging to understand because they come in different forms, making traditional, rules-based methods ineffective. Plaid, a standard Open Banking provider, offers less than 50% coverage transaction data, and its labels can be noisy and confusing. LLMs like ChatGPT promise to extract meaning from unstructured data but need help with unpredictability and scalability.
Slope TransFormer, the
new solution, overcomes these challenges by being a proprietary LLM fine-tuned to extract meaning from bank transactions. It addresses the limitations of its predecessor, SlopeGPT, by providing accurate and concise counterparty labels in an interpretable way. The key to its success lies in defining a new language during training, focusing solely on extracting the merchant name from transactions.
Using an efficient base model, OPT-125M, and a fine-tuning algorithm called LoRA, TransFormer achieves remarkable speed—labeling over 500 transactions per second, a 250x speedup over SlopeGPT. It boasts over 72% exact match accuracy against human experts, outperforming Plaid, which achieves only 62%. The solution is accurate and highly consistent, making it reliable in a production system.
[Featured AI Model] Check out LLMWare and It's RAG- specialized 7B Parameter LLMs
TransFormer’s performance has already led to its deployment in live credit monitoring dashboards. Its efficiency and functionality provide a detailed view into businesses, allowing for monitoring changing risks, alerting to abnormal events, and applying automated adjustments. The ultimate goal is to use TransFormer to power the entire underwriting system, reaching a precise understanding of businesses beyond traditional financials.
In conclusion, Slope TransFormer marks a significant milestone in redefining how underwriting is done in the B2B economy. Its efficiency, accuracy, and interpretability pave the way for a more precise understanding of businesses, unlocking new real-time signals to monitor and manage risks. This advancement aligns with the broader vision of SlopeAI to digitize the world’s B2B economy, using AI to automate workflows and eliminate inefficiencies that have hindered progress for decades.

 notes.aimodels.fyi
notes.aimodels.fyi














 LLaVA: Large Language and Vision Assistant
LLaVA: Large Language and Vision Assistant Community Contributions: [
Community Contributions: [ Space
Space