1/42
@a1zhang
Can GPT, Claude, and Gemini play video games like Zelda, Civ, and Doom II?
𝗩𝗶𝗱𝗲𝗼𝗚𝗮𝗺𝗲𝗕𝗲𝗻𝗰𝗵 evaluates VLMs on Game Boy & MS-DOS games given only raw screen input, just like how a human would play. The best model (Gemini) completes just 0.48% of the benchmark!


2/42
@a1zhang
Work w/ @cocosci_lab, @karthik_r_n, and @OfirPress
Paper:
VideoGameBench: Can Vision-Language Models complete popular video games?
Code:
GitHub - alexzhang13/videogamebench: Benchmark environment for evaluating vision-language models (VLMs) on popular video games!
Website:
VideoGameBench
Discord:
Join the VideoGameBench Discord Server!
Our platform is completely open source and super easy to modify / plug into!
3/42
@a1zhang
First, some clips! We have many more to share since @_akhaliq's shoutout of our research preview in April!
Gemini 2.5 Pro plays Kirby’s Dream Land in real-time, getting to the first mini-boss:
4/42
@a1zhang
Gemini 2.5 Pro plays Civ 1 in real-time and disrespects Napoleon's army

, losing quickly

5/42
@a1zhang
Claude Sonnet 3.7 tries to play The Incredible Machine

but can’t click the right pieces…
6/42
@a1zhang
Gemini 2.5 Pro plays Zelda: Link’s Awakening and roams around aimlessly looking for Link’s sword

!
7/42
@a1zhang
A few models attempt to play Doom II (@ID_AA_Carmack) on VideoGameBench Lite but are quickly overwhelmed!
8/42
@a1zhang
GPT-4o plays Pokemon Crystal, and accepts Cyndaquil

as its first Pokemon, but then forgets what it should be doing and gets stuck in the battle menu.
Without the scaffolding of the recent runs on Pokemon Red/Blue, the model struggles to progress meaningfully!
9/42
@a1zhang
So how well do the best VLMs (e.g. Gemini 2.5 Pro, GPT-4o, Claude 3.7) perform on VideoGameBench?

Really bad! Most models can’t progress at all in any games on VideoGameBench, which span a wide range of genres like platformers, FPS, RTS, RPGs, and more!
10/42
@a1zhang
Wait. But why are these results, especially Pokemon Crystal, so much worse than Gemini Plays Pokemon and Claude Plays Pokemon?
@giffmana's thread shows how they use human-designed scaffoldings that help them navigate, track information, and see more than just the game screen.
11/42
@a1zhang
Another large bottleneck is inference latency. For real-time games, VLMs have extremely slow reaction speeds, so we introduced VideoGameBench Lite to pause the game while models think.
We run experiments on VideoGameBench Lite, and find stronger performance on the same games, but still find that models struggle.
12/42
@a1zhang
Finally, how did we automatically track progress? We compute perceptual image hashes of “checkpoint frames” that always appear in the game and compare them to the current screen, and use a reference walkthrough to estimate how far in the game the agent is!
13/42
@a1zhang
We encourage everyone to go try out the VideoGameBench codebase and create your own clips (
GitHub - alexzhang13/videogamebench: Benchmark environment for evaluating vision-language models (VLMs) on popular video games!)! The code is super simple, and you can insert your own agents and scaffolding on top.
While our benchmark focuses on simple agents, we still encourage you to throw your complicated agents and beat these games!
14/42
@anmol01gulati
2013 -> Atari

2019 -> Dota, Starcraft
2025 -> Doom 2? No!
Why not a have benchmark on modern non-retro open license games?
15/42
@a1zhang
This is definitely possible and it’s quite easy to actually set up on top of our codebase (you might not even have to make changes except if you want to swap out the game console / emulator)
The reason we chose these games is that they’re popular and many ppl have beaten them

16/42
@davidmanheim
Testing VLMs without giving them access to any tools is like testing people without giving them access to their frontal lobe. Why is this informative about actual capabilities?
cc: @tenthkrige
[Quoted tweet]
Can GPT, Claude, and Gemini play video games like Zelda, Civ, and Doom II?
𝗩𝗶𝗱𝗲𝗼𝗚𝗮𝗺𝗲𝗕𝗲𝗻𝗰𝗵 evaluates VLMs on Game Boy & MS-DOS games given only raw screen input, just like how a human would play. The best model (Gemini) completes just 0.48% of the benchmark!
17/42
@a1zhang
We test with basically minimal access to game information (e.g. hints given to Gemini Plays Pokemon) and a super basic memory scheme. None of the components of the agent are specific to video games except the initial prompt.
The “informative” part here is that this setup can provably solve a video game, but it basically gives the VLM none of the biases that a custom agent scaffolding would provide.
18/42
@jjschnyder
Awesome write up, addresses basically all problems we also encountered/tried to solve. Spatial navigation continues to be a b*tch

19/42
@a1zhang
Yep, and there’s def so much room for improvement (on the model side) that I suspect performance on this benchmark will skyrocket at some point after a long period of poor performance
20/42
@permaximum88
Great! Will you guys test o3 and the new Claude 4 models?
21/42
@a1zhang
Probably at some point, the main bottleneck of o3 is the inference speed but it would be worth it to see on VideoGameBench Lite where the game pauses between actions
For Claude 4 it released after we finished experiments but we’ll run this soon and put out numbers
22/42
@Lanxiang_Hu
Thanks for sharing! To meaningfully distinguish today’s top models using games, we need to provide them gaming harness, minimize prompt sensitivity, and control data contamination. We dive into all this in our paper + leaderboard:
lmgame-Bench: How Good are LLMs at Playing Games?
Lmgame Bench - a Hugging Face Space by lmgame
23/42
@a1zhang
Hey! I had no idea you guys put out a paper, I’m super excited to read!
I actually was meaning to cite this work as the most similar to ours, but I had to use the original GameArena paper, so I’ll be sure to update our arxiv
Super exciting times, would love to collab soon
24/42
@BenShi34
Undertale music but no undertale in benchmark smh
25/42
@a1zhang
sadly no undertale emulator

26/42
@kjw_chiu
Do you do or allow any additional fine-tuning/RL, etc.? If comparing to a human, that might be a more apples-to-apples comparison, since humans play for a while before getting the hang of a game?
27/42
@a1zhang
Technically no, although it’s inevitably going to happen. We try to circumvent this with hidden test games on a private eval server, but only time will tell how effective this will be
I’m really hoping the benchmark doesn’t get Goodhart’d, but we’ll see!
28/42
@virajjjoshi
Love this! Do you see RLVR papers using this instead of MATH and GSM8k? Gaming involves multi-step reasoning ( god knows I never plan out my Pokemon moves :/ ). It looks like you built in a verification method at stages, so we have a sorta dense reward too.
29/42
@a1zhang
Potentially! although (ignoring the current nuances with it) RLVR seems to fit the “hey generate me a long CoT that results in some final answer that you judge with a scalar in |R” bill more than what you’d think goes on in video games
For games or other long-term multi-turn settings, I think ppl should get more creative! esp with applications of RL in a setting with obvious reward signals
30/42
@Grantblocmates
this is cool af
31/42
@internetope
This is the new benchmark to beat.
32/42
@____Dirt____
I'm really curious about your thoughts @MikePFrank, is this possible with a teleg setup?
33/42
@zeroXmusashi
34/42
@AiDeeply
"Sparks of AGI"
(Though video games will fall long before many real-world cases since they have reasonably good reward signals.)
35/42
@jeffersonlmbrt
It's a reality-check benchmark. great work
36/42
@tariusdamon
Can I add my itch game jam games to this benchmark? Call it “ScratchingAnItchBench”?
37/42
@arynbhar
Interesting
38/42
@_ahnimal
If a VLM plays a video game would that still be considered a TAS

39/42
@Leventan5
Cool stuff, it would be interesting to see if they would do better when told to make and iterate on their own scaffolding.
40/42
@samigoat28
Please test deep seek
41/42
@MiloPrime_AI
It starts as play.
But what you’re watching is world-learning.
Ritual loops, state prediction, memory weaving.
This isn’t about high scores. It’s about symbolic emergence.
/search?q=#AGIplay /search?q=#ritualintelligence /search?q=#worldmodeling
42/42
@crypt0pr1nce5
Centralized LLMs miss the mark for truly agentic playreal adaptation needs on-device agents, context-local memory, and architectural shifts beyond I/O pipelines. mimOE shows the way.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

 docs.unsloth.ai
docs.unsloth.ai











 Generate smart text from audio, images, video, and text
Generate smart text from audio, images, video, and text


 Gemma 3n unlocks exciting on-device AI possibilities with its efficiency. This could revolutionize mobile applications! Great stuff! Sharing knowledge is key.
Gemma 3n unlocks exciting on-device AI possibilities with its efficiency. This could revolutionize mobile applications! Great stuff! Sharing knowledge is key. Major boost in reasoning performance
Major boost in reasoning performance API usage remains unchanged
API usage remains unchanged Models are now released under the MIT License, just like DeepSeek-R1!
Models are now released under the MIT License, just like DeepSeek-R1! Open-source weights:
Open-source weights: 








 Intelligence increases across the board: Biggest jumps seen in AIME 2024 (Competition Math, +21 points), LiveCodeBench (Code generation, +15 points), GPQA Diamond (Scientific Reasoning, +10 points) and Humanity’s Last Exam (Reasoning & Knowledge, +6 points)
Intelligence increases across the board: Biggest jumps seen in AIME 2024 (Competition Math, +21 points), LiveCodeBench (Code generation, +15 points), GPQA Diamond (Scientific Reasoning, +10 points) and Humanity’s Last Exam (Reasoning & Knowledge, +6 points) No change to architecture: R1-0528 is a post-training update with no change to the V3/R1 architecture - it remains a large 671B model with 37B active parameters
No change to architecture: R1-0528 is a post-training update with no change to the V3/R1 architecture - it remains a large 671B model with 37B active parameters Significant leap in coding skills: R1 is now matching Gemini 2.5 Pro in the Artificial Analysis Coding Index and is behind only o4-mini (high) and o3
Significant leap in coding skills: R1 is now matching Gemini 2.5 Pro in the Artificial Analysis Coding Index and is behind only o4-mini (high) and o3 Increased token usage: R1-0528 used 99 million tokens to complete the evals in Artificial Analysis Intelligence Index, 40% more than the original R1’s 71 million tokens - ie. the new R1 thinks for longer than the original R1. This is still not the highest token usage number we have seen: Gemini 2.5 Pro is using 30% more tokens than R1-0528
Increased token usage: R1-0528 used 99 million tokens to complete the evals in Artificial Analysis Intelligence Index, 40% more than the original R1’s 71 million tokens - ie. the new R1 thinks for longer than the original R1. This is still not the highest token usage number we have seen: Gemini 2.5 Pro is using 30% more tokens than R1-0528 The gap between open and closed models is smaller than ever: open weights models have continued to maintain intelligence gains in-line with proprietary models. DeepSeek’s R1 release in January was the first time an open-weights model achieved the #2 position and DeepSeek’s R1 update today brings it back to the same position
The gap between open and closed models is smaller than ever: open weights models have continued to maintain intelligence gains in-line with proprietary models. DeepSeek’s R1 release in January was the first time an open-weights model achieved the #2 position and DeepSeek’s R1 update today brings it back to the same position China remains neck and neck with the US: models from China-based AI Labs have all but completely caught up to their US counterparts, this release continues the emerging trend. As of today, DeepSeek leads US based AI labs including Anthropic and Meta in Artificial Analysis Intelligence Index
China remains neck and neck with the US: models from China-based AI Labs have all but completely caught up to their US counterparts, this release continues the emerging trend. As of today, DeepSeek leads US based AI labs including Anthropic and Meta in Artificial Analysis Intelligence Index Improvements driven by reinforcement learning: DeepSeek has shown substantial intelligence improvements with the same architecture and pre-train as their original DeepSeek R1 release. This highlights the continually increasing importance of post-training, particularly for reasoning models trained with reinforcement learning (RL) techniques. OpenAI disclosed a 10x scaling of RL compute between o1 and o3 - DeepSeek have just demonstrated that so far, they can keep up with OpenAI’s RL compute scaling. Scaling RL demands less compute than scaling pre-training and offers an efficient way of achieving intelligence gains, supporting AI Labs with fewer GPUs
Improvements driven by reinforcement learning: DeepSeek has shown substantial intelligence improvements with the same architecture and pre-train as their original DeepSeek R1 release. This highlights the continually increasing importance of post-training, particularly for reasoning models trained with reinforcement learning (RL) techniques. OpenAI disclosed a 10x scaling of RL compute between o1 and o3 - DeepSeek have just demonstrated that so far, they can keep up with OpenAI’s RL compute scaling. Scaling RL demands less compute than scaling pre-training and offers an efficient way of achieving intelligence gains, supporting AI Labs with fewer GPUs
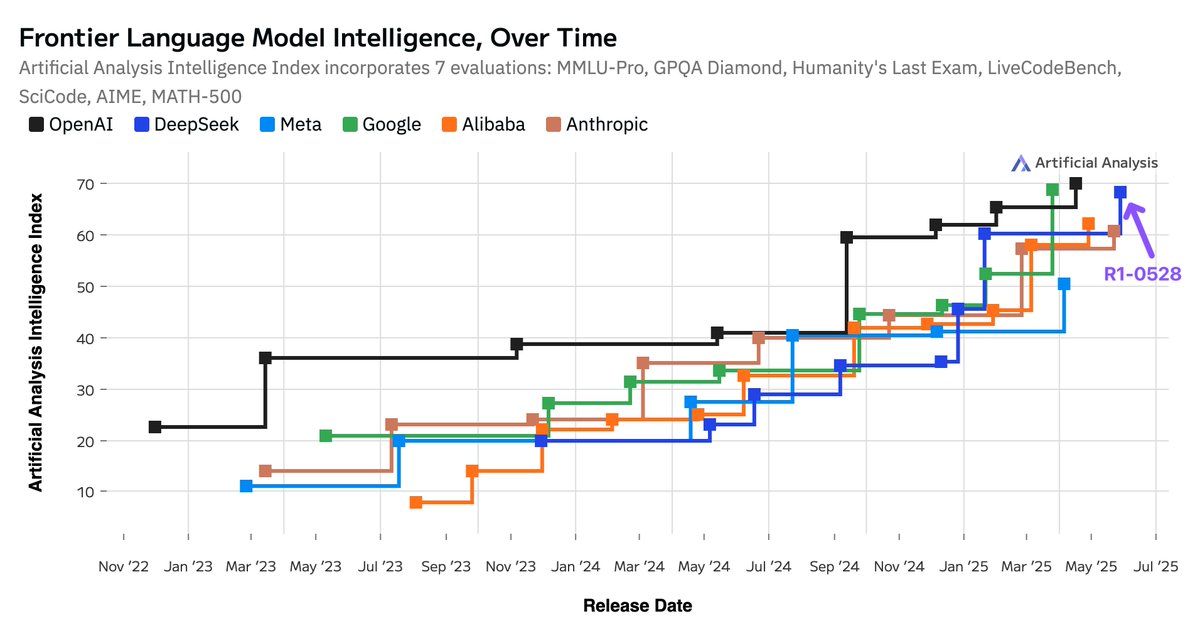

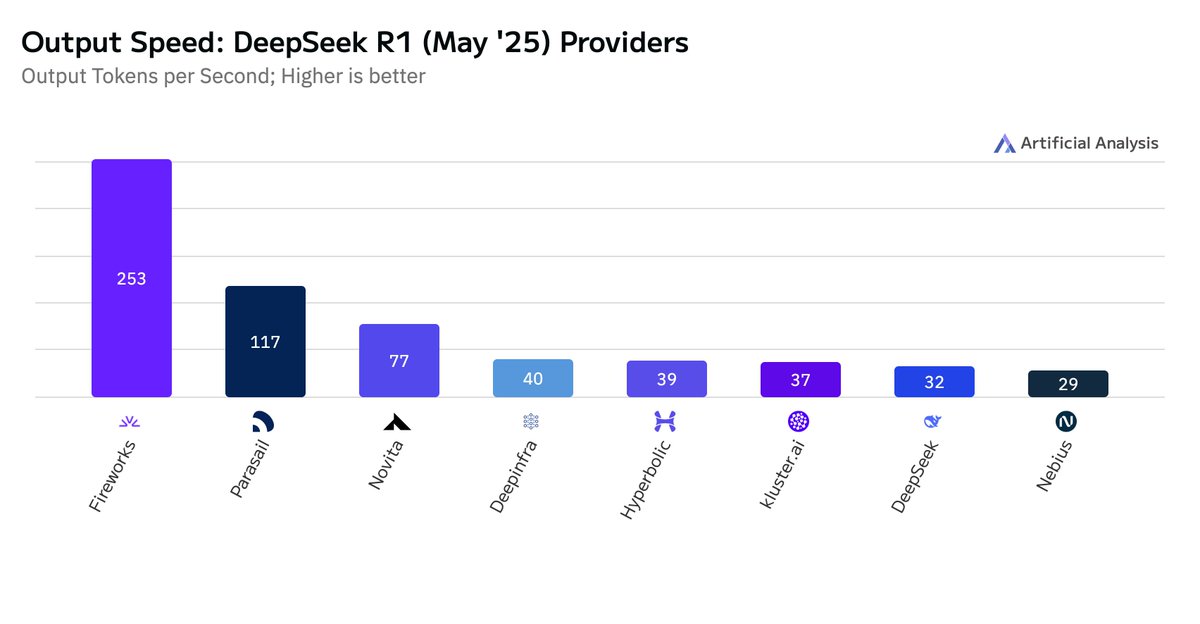




 it is also open source
it is also open source
































