1/12
@rohanpaul_ai
I'm playing with Kimi-Researcher from
/Kimi_Moonshot , and its delivering an unexpectedly excellent report!

Its a multi-turn search and reasoning AI Agent from China competing head-to-head with OpenAI's Deep Research. And its free.

Checks more than 200 URLs for each task.

Context-aware, very long-horizon reasoning

Runs on an internal Kimi k-series backbone

Learns entirely through end-to-end agentic RL
Averages about 23 reasoning steps per query
Overall, what I really like is that it turns it all into a clean, visual report that actually makes sense. Smart, solid, reliable.
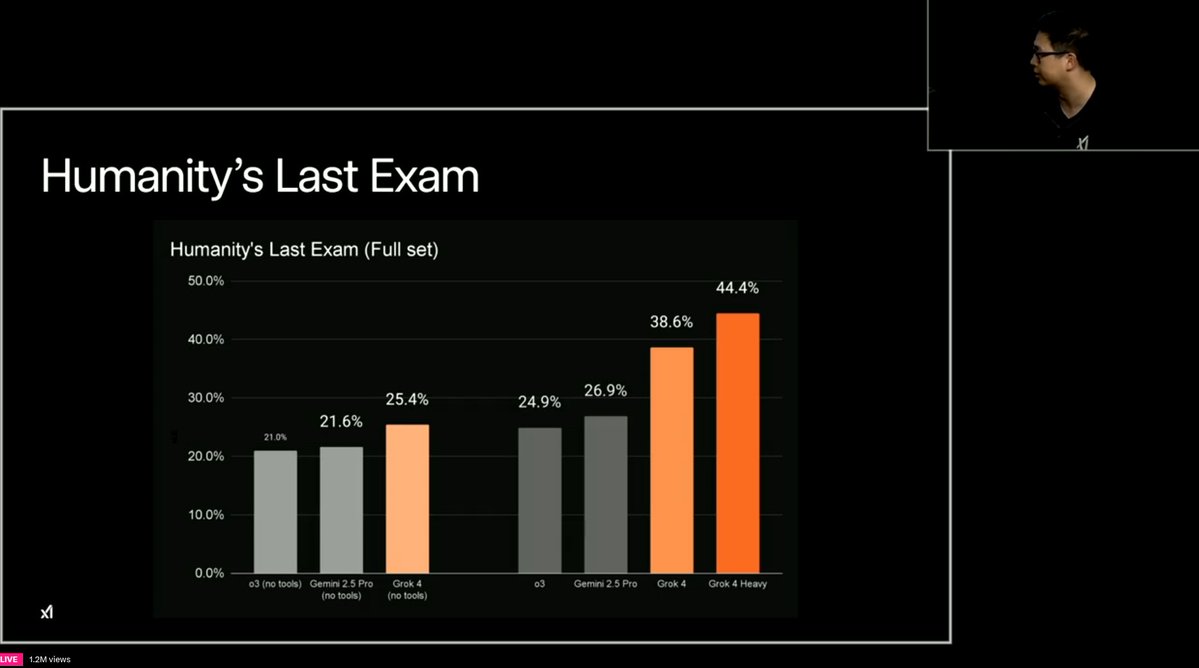
It has proven that an LLM can train itself with reinforcement learning to plan, search, and code, reaching 26.9% pass@1 on Humanity’s Last Exam after starting at 8.6%, beating many supervised‑finetuned models.
Benchmarks:

Achieves 26.9% pass@1 on Humanity’s Last Exam, top of the board

Scores 69% pass@1 on xbench-DeepSearch, edging past o3 with tools

Delivers solid results on FRAMES, Seal-0, and SimpleQA
Key takeaway

Shows that self-rewarded training can mature planning, search, and coding in one loop

High‑quality agent datasets are rare, so the team generated their own.
They built tool‑centric challenges that force real tool use and hard reasoning prompts that need iterative search. An automated pipeline synthesized question‑answer pairs, verified ground truth, and filtered out trivial or noisy examples to scale data without manual labeling.

Context spills were a major pain point. A learned memory policy keeps only useful snippets and discards the rest, letting a single conversation run 50+ turns without hitting context limits.

Training stays on‑policy. Tool‑call format guards are switched off, so every trajectory truly reflects model probabilities.
Some negative samples are dropped to prevent probability collapse, and the agent keeps improving for longer runs.
What that means is that, If the trainer kept every badly scored run, the learning rule could shove the odds of many actions all the way to 0, and the model would stop exploring. To avoid that freeze, the pipeline drops a slice of the worst runs. The model still sees plenty of errors, but not enough to wipe out whole branches of its search space.
These tweaks keep the feedback loop stable across long tasks, so the agent keeps improving even when a single job takes dozens of steps.

1/n Read on
2/12
@rohanpaul_ai
2/n Link to try:
Kimi - 会推理解析,能深度思考的AI助手
Running the agent is straightforward. A user opens
Kimi - 会推理解析,能深度思考的AI助手, logs in, and toggles the “Researcher” mode
Enters a research query, clarifies any follow-up questions, and the agent works for roughly 20-25 minutes.
When the report appears, the text can be copied directly or shared via a link; a download button is not yet available. All usage is free during the public preview, and no hard quota has been announced.
– 200+ URLs
– inline citations
– tool-calling (search + browser + code)
https://video.twimg.com/amplify_video/1942960617314521088/vid/avc1/1920x1080/V9AbUXDkTtEUPYrX.mp4
3/12
@rohanpaul_ai
3/n
Kimi‑Researcher proves that an agent can learn planning, perception, and precise tool use in one loop.

After RL, the model averages 23 reasoning steps and checks about 200 URLs per task, reaches 69% pass@1 on xbench‑DeepSearch, and shows habits like cross‑verifying conflicting sources before answering.
4/12
@rohanpaul_ai
4/n
Kimi-Researcher relies on 3 built-in tools: a fast parallel search engine, a text-only browser for interactive sites, and a coding sandbox for data wrangling or analysis.
Together they let the model fetch evidence, run code, and compose structured reports that mix prose, tables, and simple charts inside an interactive page.
5/12
@rohanpaul_ai
5/n Performance on key research benchmarks
Kimi hits:
– 26.9% pass@1 on Humanity’s Last Exam (vs OpenAI’s ~8%)
– 69% pass@1 on xBench DeepSearch
– Top scores on Seal-0, Frames, SimpleQA
And yes.. it’s all done by one model. No agents and tricks.
6/12
@rohanpaul_ai
6/n Here are some creative and great use cases or running deep research task with it.
Prompt - “Provide an in-depth and comprehensive analysis of the Golden State Warriors’ salary cap situation for the 2025–2026 NBA season. This should include detailed projections of guaranteed contracts, player options, potential free agents, and dead money on the books. Evaluate the team’s flexibility regarding potential trades, including possible targets, movable contracts, and draft assets. Break down the composition of the roster in terms of strengths, weaknesses, positional depth, age profile, and development potential of young players. Finally, assess the realistic probability of the Warriors mounting a successful championship run in light of their financial constraints, roster construction, and the competitive landscape of the league”
https://www.kimi.com/preview/197bf0e2-e001-861c-96ef-688ebe0005de
https://video.twimg.com/amplify_video/1942962571042000896/vid/avc1/1280x720/TBeFIZ8CPV_EsKXu.mp4
7/12
@rohanpaul_ai
7/n
Another deep research task
Prompt - “Make a deep research about CoreWeave’s infrastructure expansion and competitive positioning in the GPU-as-a-Service (GPUaaS) market, including key clients, partnerships, and scalability roadmap.”
Kimi - 会推理解析,能深度思考的AI助手
https://video.twimg.com/amplify_video/1942962695642435584/vid/avc1/1280x720/hzt4YGa21OSPs14e.mp4
8/12
@rohanpaul_ai
8/n Another use case of running deep research task
Prompt - “Make a deep research about Circle’s post-IPO stock surge and volatility—750% rally, recent pullback, analyst sentiment including Ark trim, and comparison to Coinbase movement.”
https://video.twimg.com/amplify_video/1942962873308696577/vid/avc1/1280x720/Ya2RlrsZgBCwvCrk.mp4
9/12
@rohanpaul_ai
9/n
Another use case
Prompt - “Analyze Tesla’s recent executive shake‑up—including the firing of regional head Omead Afshar—under the strain of Q2 sales decline, European market share drop, and internal ‘Tesla Takedown’ protests.”
Kimi - 会推理解析,能深度思考的AI助手
https://video.twimg.com/amplify_video/1942962963905679360/vid/avc1/1280x720/ERPuC3_Hgti0fQzK.mp4
10/12
@rohanpaul_ai
10/n
Another use case
Prompt - “Core PCE hits lowest level since 2020 — implications for inflation"
https://www.kimi.com/preview/d1h2smef5ku9dv185g40?blockId=46
https://video.twimg.com/amplify_video/1942963994001850368/vid/avc1/1920x1080/i2qnExBs5Ug-9nhd.mp4
11/12
@rohanpaul_ai
Link to try:
Kimi - 会推理解析,能深度思考的AI助手
Kimi-Researcher is beginning its gradual rollout. Join the waitlist here.
Apply for Kimi Researcher

Blog:
https://moonshotai.github.io/Kimi-Researcher/
12/12
@ApollonVisual
The results of the research are solid content wise and accuracy wise. But it was very slow (o3 pro deep research with extended research prompt, fetched results nearly 7 minutes earlier) for the same exact topic /promot. But it’s free and an interesting alternative to established deep research agents
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196







 Mistral launches Devstral Small 1.1 (53.6% SWE-Bench) and Devstral Medium (61.6%), tuned for coding agents.
Mistral launches Devstral Small 1.1 (53.6% SWE-Bench) and Devstral Medium (61.6%), tuned for coding agents. Token prices sit between $0.1 and $2 per 1M, with Medium roughly 75% below GPT4-class rates.
Token prices sit between $0.1 and $2 per 1M, with Medium roughly 75% below GPT4-class rates. 



 /huggingface teams with Pollen Robotics to launch Reachy Mini, a 28 cm desktop robot priced at $299 and ready for vision, speech, and text models.
/huggingface teams with Pollen Robotics to launch Reachy Mini, a 28 cm desktop robot priced at $299 and ready for vision, speech, and text models. Builders can instantly run 15+ preset behaviors or upload new ones through the community hub.
Builders can instantly run 15+ preset behaviors or upload new ones through the community hub.


 What a MemCube holds
What a MemCube holds

 Scheduler keeps memories fresh
Scheduler keeps memories fresh
 Numbers that prove the point
Numbers that prove the point
 KV tricks to cut wait time
KV tricks to cut wait time

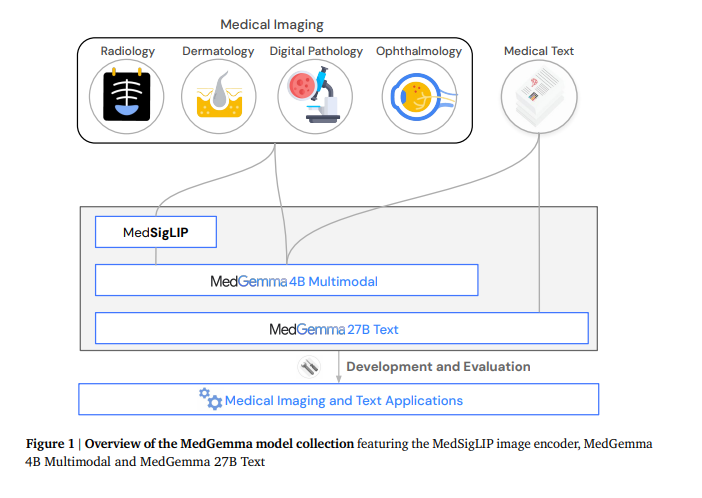
 Google Research release MedGemma 27B, multimodal health-AI models that run on 1 GPU
Google Research release MedGemma 27B, multimodal health-AI models that run on 1 GPU 






















 The quick idea
The quick idea
