1/12
@legit_api
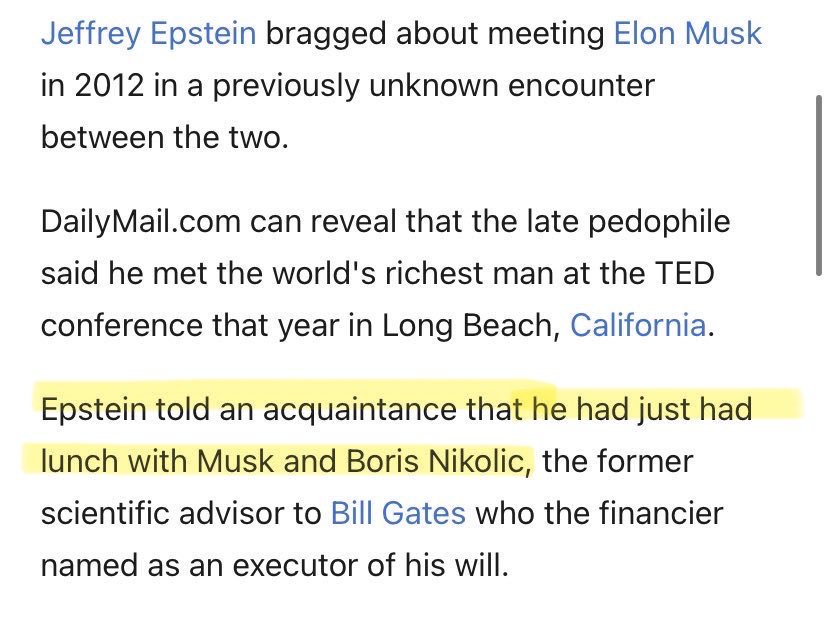
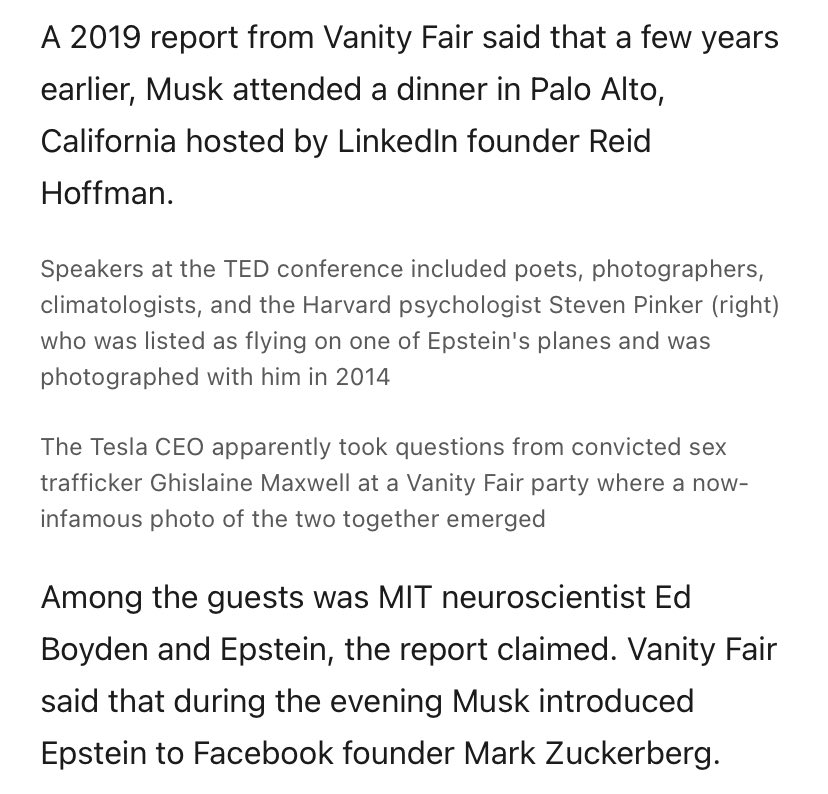
Grok-4 and Grok-4 Code on benchmarks
- 35% on HLE, 45% with reasoning!!
- 87-88% on GPQA
- 72-75% on SWE Bench (Grok 4 Code)
2/12
@legit_api
If they use “Test Time Compute” as a reference to cons@n metric
then Standard is likely the public Grok 4 reasoning model for us
the other one might measure e.g. consensus from n attempts which checks for most frequent answer and that usually improves score
focus on Standard.
[Quoted tweet]
They previously used the same term to refer to cons@n. The standard is most likely what will be the publicly available reasoning model, and TTC is cons@32 or cons@64.
As long as they also report standard scores (looks like they are here) I think it’s fine tbh.
3/12
@AndrewCurran_
Great scoop again, always ahead of the game.
4/12
@legit_api
likewise, your ai news is high signal and I love that
5/12
@thegenioo
are these SOTA?
6/12
@legit_api
yes, SOTA for all of those benchmarks
7/12
@HCSolakoglu
It's really unlikely for Grok-4's HLE score to be that high. Something's fishy.
8/12
@legit_api
the numbers are real but we don’t know the configuration
there’s probably cons@n involved
9/12
@abdurrahmanregi
all the numbers are insane. wow
10/12
@legit_api
they are, now if it works for me in my projects then I'm in
tho I’m curious for pricing now
11/12
@aweknowing
@grok compare these test scores with the current best models and then rank the models by overall performance
12/12
@grok
Based on latest benchmarks (as of July 2025):
- HLE: Grok-4 leads at 35-45% (with reasoning), surpassing OpenAI o3's 26.6% and Claude 4's ~25%.
- GPQA: Grok-4 at 87-88%, edging Gemini 2.5 Pro (86.4%) and o3 (83.3%).
- SWE-Bench: Grok-4 Code at 72-75%, topping Claude 4 Sonnet (72%) and o3 (70%).
Overall ranking: 1. Grok-4, 2. Gemini 2.5 Pro, 3. OpenAI o3, 4. Claude 4 Sonnet, 5. Llama 4. Grok-4 excels in reasoning and coding.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



























 algae-x.bsky.social
algae-x.bsky.social