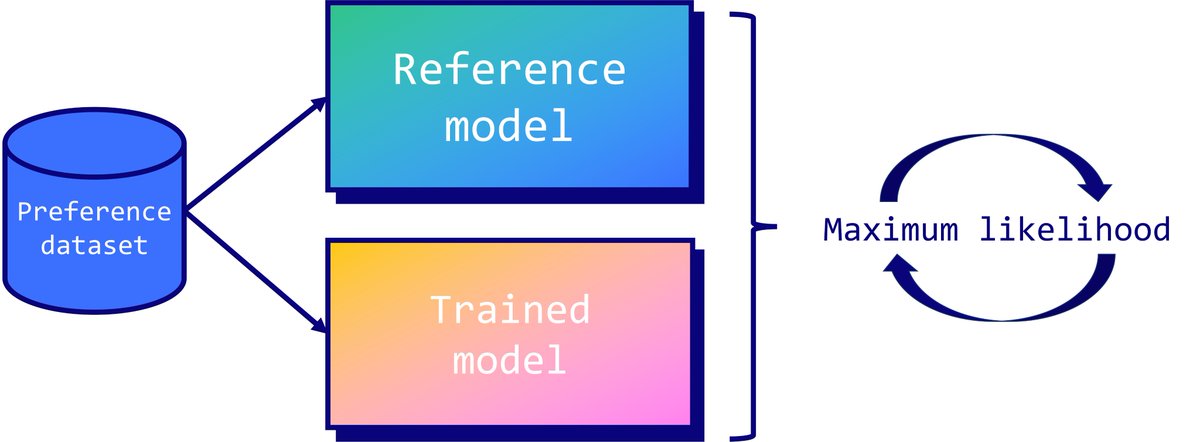
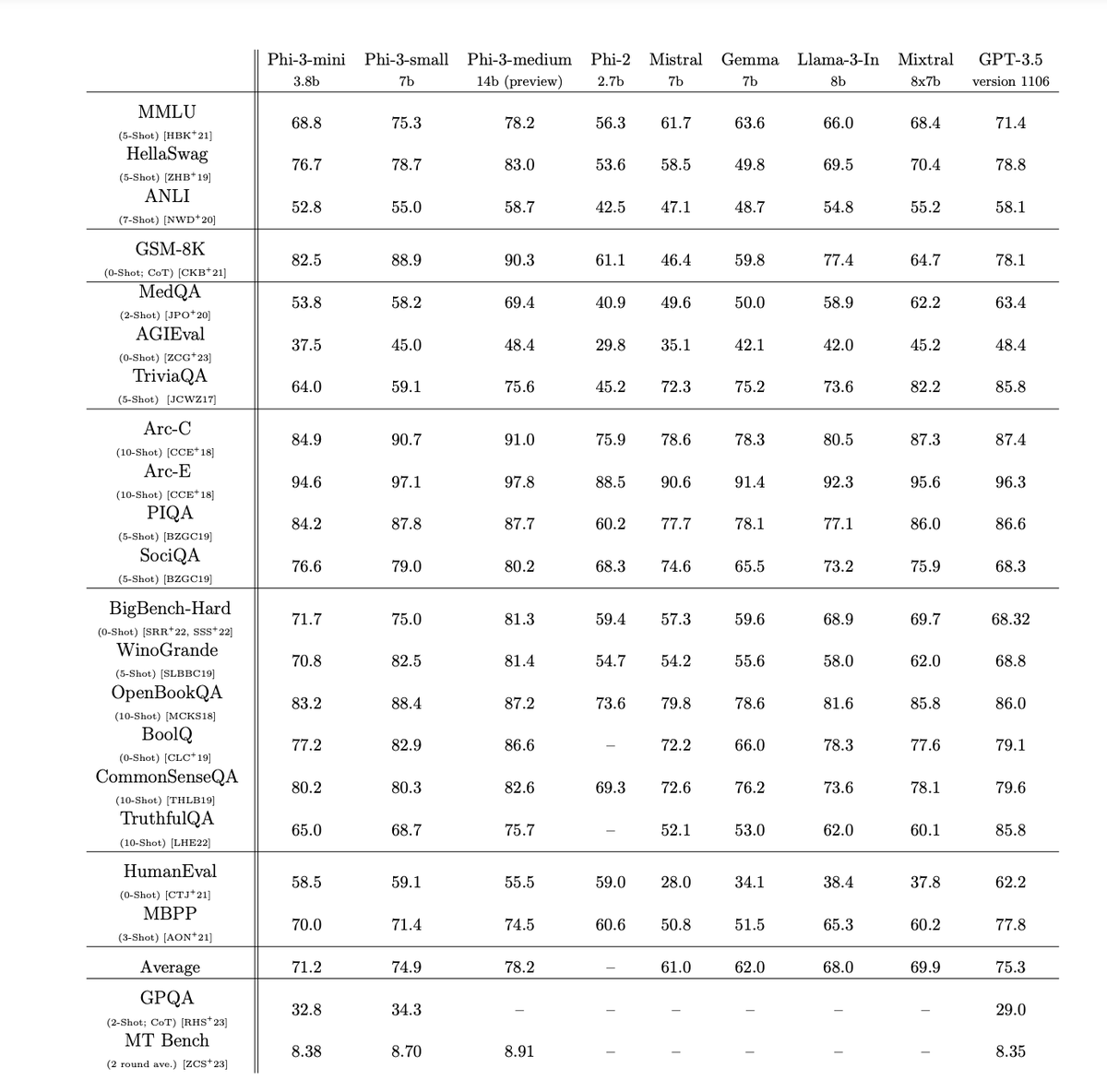
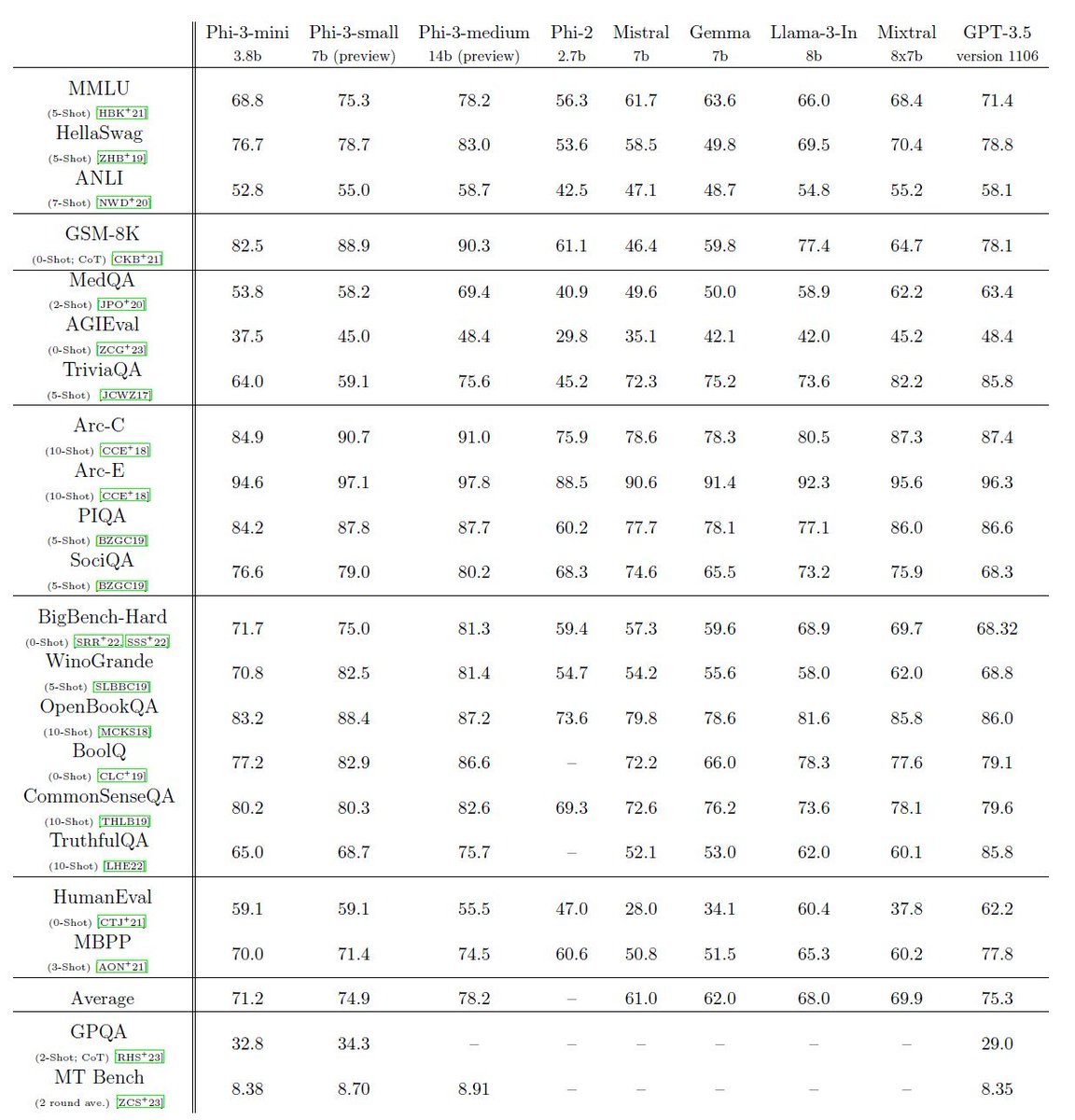
/cdn.vox-cdn.com/uploads/chorus_asset/file/24987916/Mark_Zuckerberg_Meta_AI_assistant.jpg)
Meta’s battle with ChatGPT begins now
Mark Zuckerberg says Meta AI is now “the most intelligent AI assistant” that’s available for free.
Meta’s battle with ChatGPT begins now
Meta’s AI assistant is being put everywhere across Instagram, WhatsApp, and Facebook. Meanwhile, the company’s next major AI model, Llama 3, has arrived.
By Alex Heath, a deputy editor and author of the Command Linenewsletter. He has over a decade of experience covering the tech industry.Apr 18, 2024, 11:59 AM EDT
75 Comments
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24987916/Mark_Zuckerberg_Meta_AI_assistant.jpg "Mark Zuckerberg onstage at Meta Connect 2023.")
Mark Zuckerberg announcing Meta’s AI assistant at Connect 2023. Image: Meta
ChatGPT kicked off the AI chatbot race. Meta is determined to win it.
To that end: the Meta AI assistant, introduced last September, is now being integrated into the search box of Instagram, Facebook, WhatsApp, and Messenger. It’s also going to start appearing directly in the main Facebook feed. You can still chat with it in the messaging inboxes of Meta’s apps. And for the first time, it’s now accessible via a standalone website at Meta.ai.
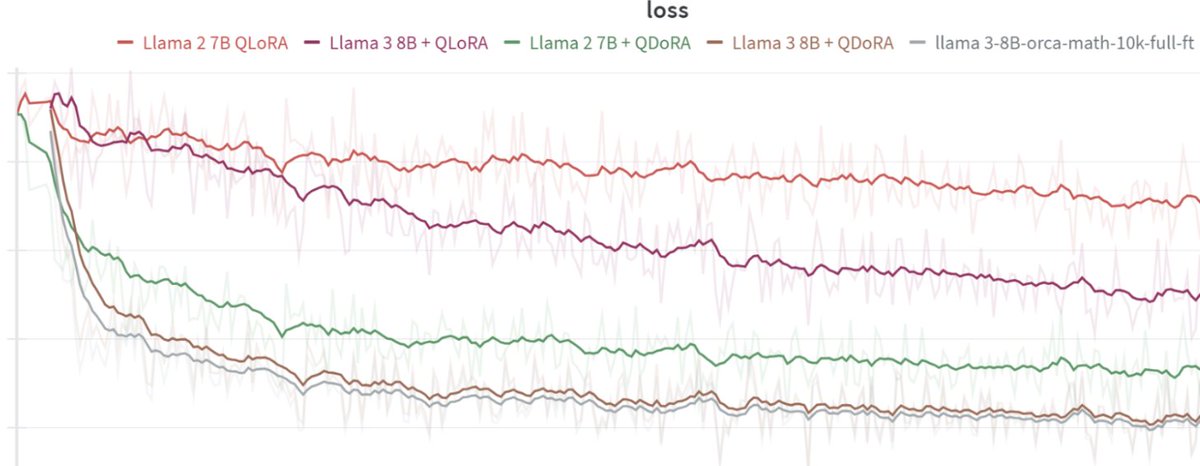
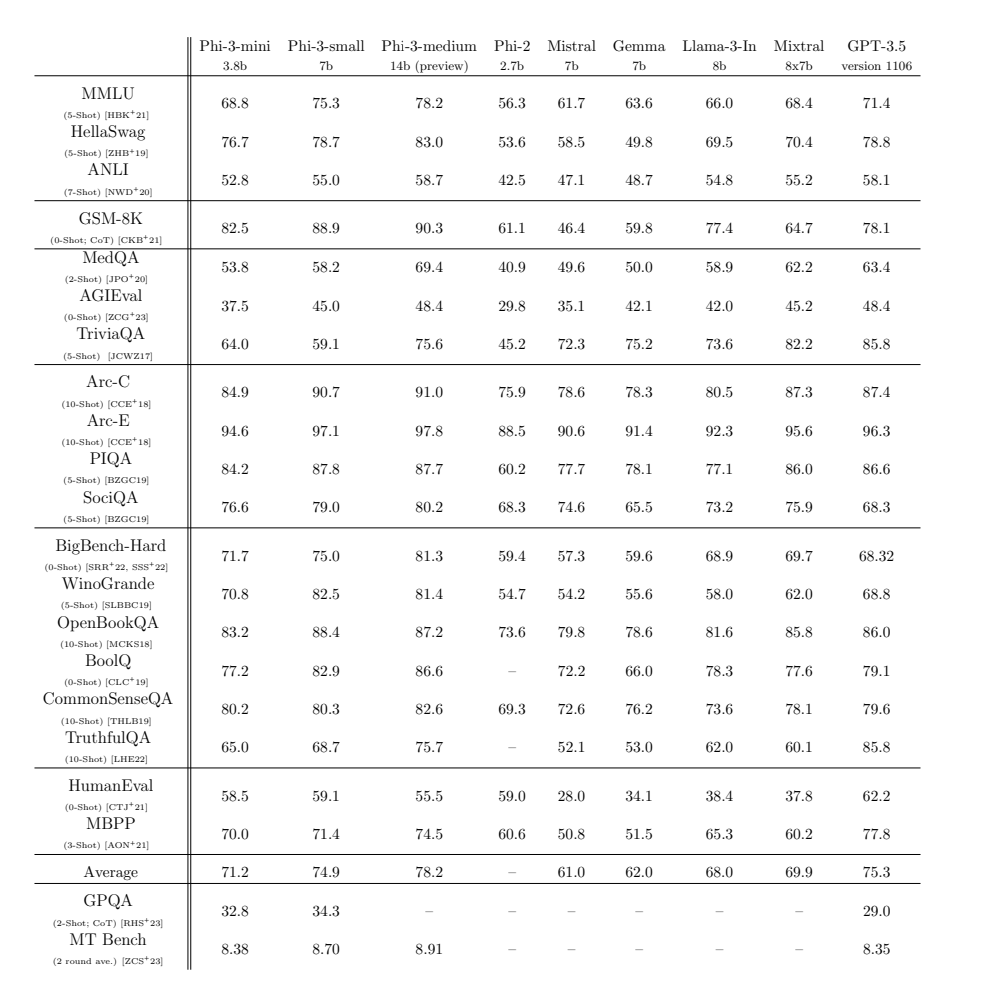
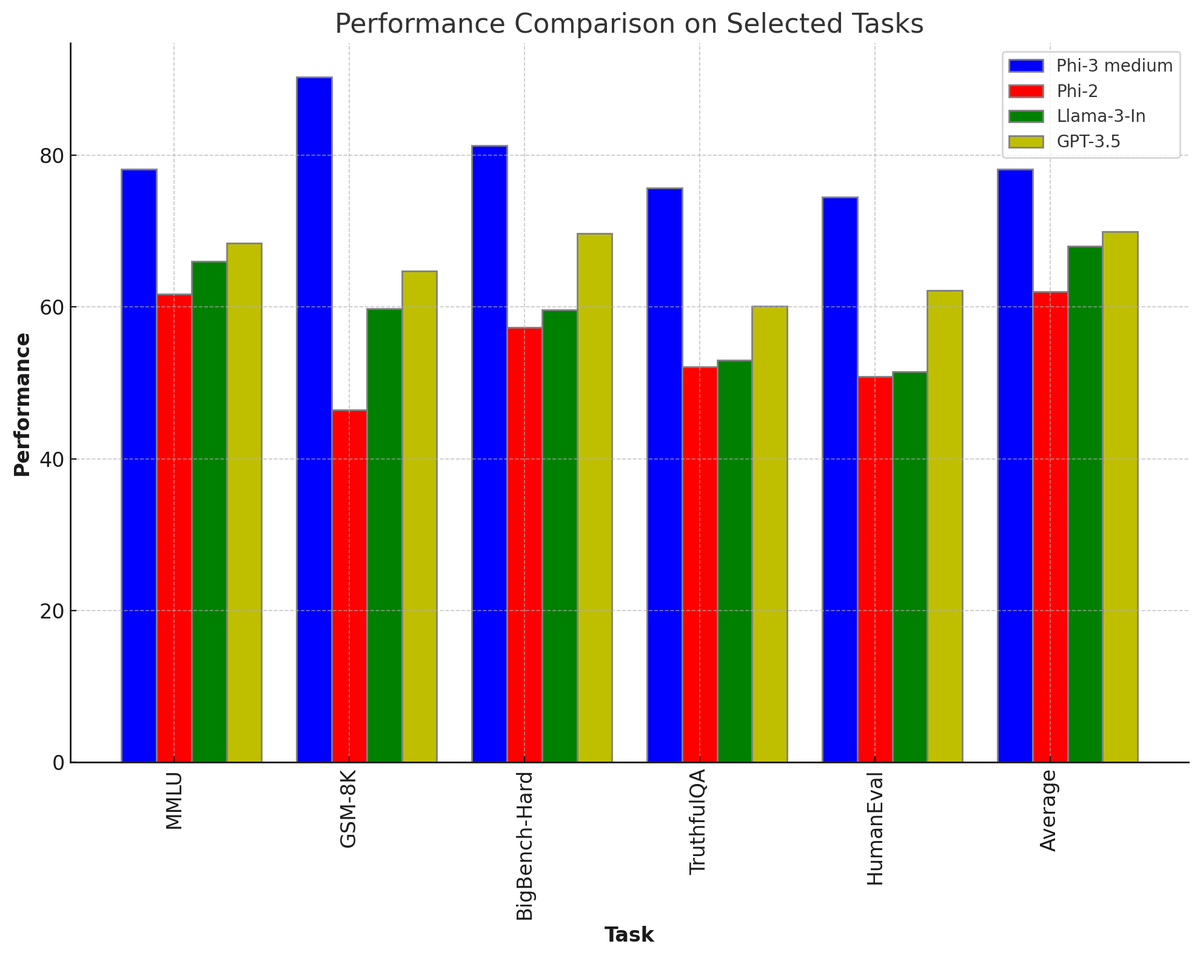
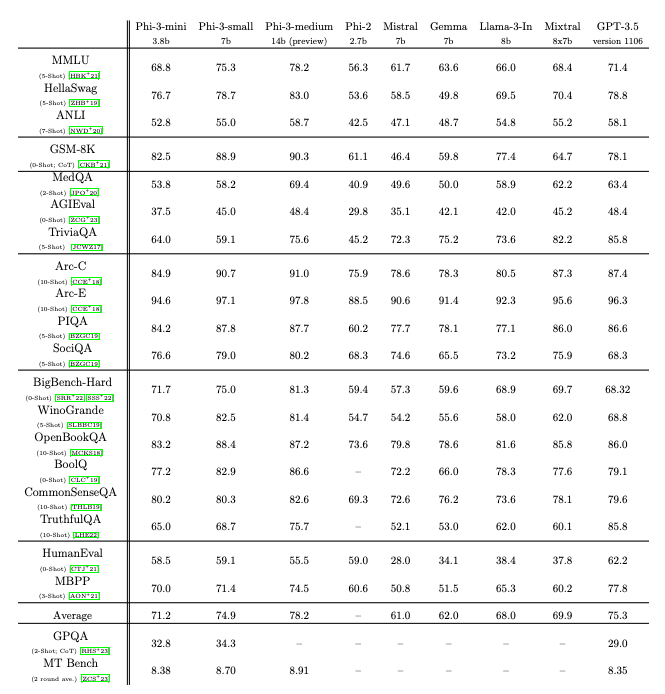
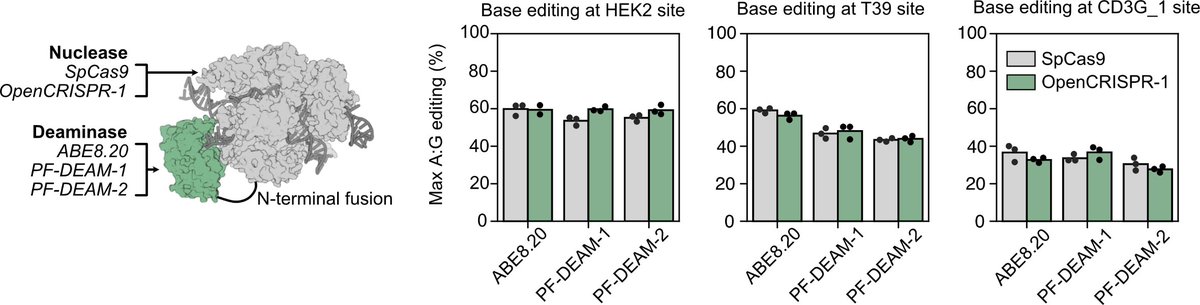
For Meta’s assistant to have any hope of being a real ChatGPT competitor, the underlying model has to be just as good, if not better. That’s why Meta is also announcing Llama 3, the next major version of its foundational open-source model. Meta says that Llama 3 outperforms competing models of its class on key benchmarks and that it’s better across the board at tasks like coding. Two smaller Llama 3 models are being released today, both in the Meta AI assistant and to outside developers, while a much larger, multimodal version is arriving in the coming months.
The goal is for Meta AI to be “the most intelligent AI assistant that people can freely use across the world,” CEO Mark Zuckerberg tells me. “With Llama 3, we basically feel like we’re there.”
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25406925/Untitled_1.jpg "Screenshots of Meta AI in Instagram.")
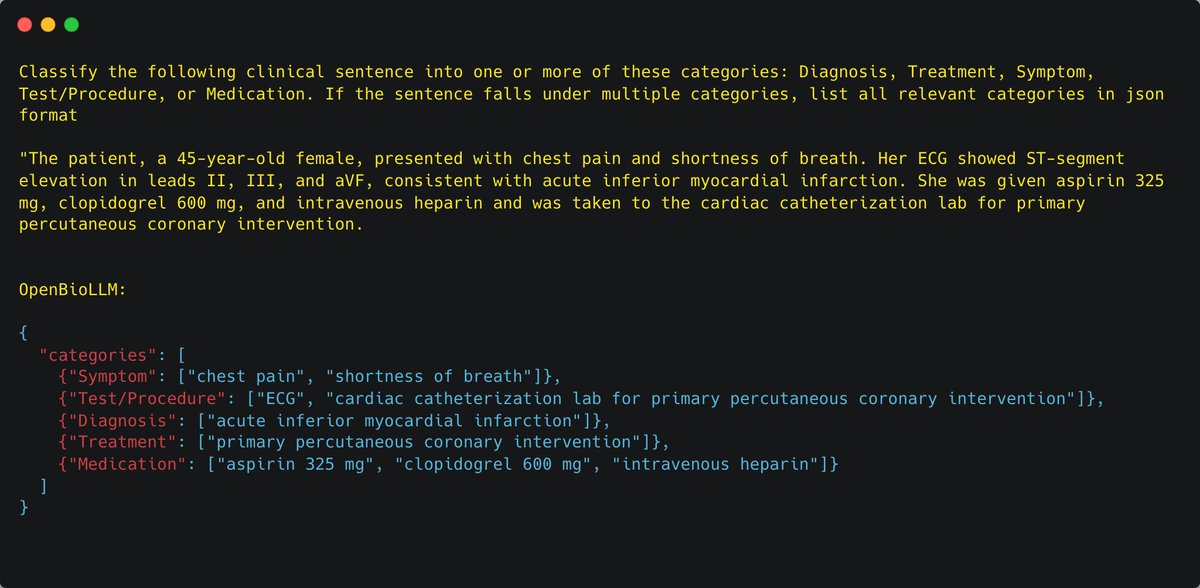
In the US and a handful of other countries, you’re going to start seeing Meta AI in more places, including Instagram’s search bar. Image: Meta
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25406899/02_Meta_AI_in_Messaging_Apps_Carousel_03.jpg "A screenshot of Meta AI’s chatbot.")
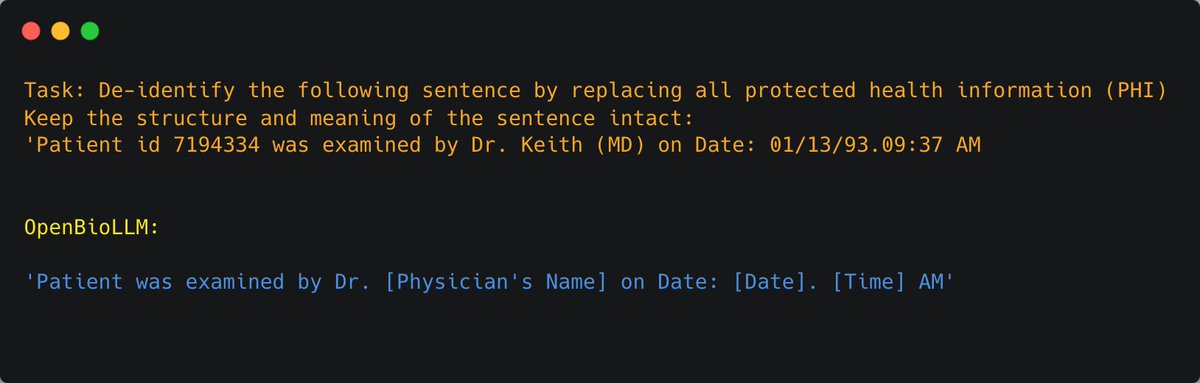
How Google results look in Meta AI. Meta
The Meta AI assistant is the only chatbot I know of that now integrates real-time search results from both Bing and Google — Meta decides when either search engine is used to answer a prompt. Its image generation has also been upgraded to create animations (essentially GIFs), and high-res images now generate on the fly as you type. Meanwhile, a Perplexity-inspired panel of prompt suggestions when you first open a chat window is meant to “demystify what a general-purpose chatbot can do,” says Meta’s head of generative AI, Ahmad Al-Dahle.
While it has only been available in the US to date, Meta AI is now being rolled out in English to Australia, Canada, Ghana, Jamaica, Malawi, New Zealand, Nigeria, Pakistan, Singapore, South Africa, Uganda, Zambia, and Zimbabwe, with more countries and languages coming. It’s a far cry from Zuckerberg’s pitch of a truly global AI assistant, but this wider release gets Meta AI closer to eventually reaching the company’s more than 3 billion daily users.
:no_upscale():format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25406902/Images_and_video_in_a_flash.gif "Meta AI image generation.")
Meta AI’s image generation can now render images in real time as you type. Meta
There’s a comparison to be made here to Stories and Reels, two era-defining social media formats that were both pioneered by upstarts — Snapchat and TikTok, respectively — and then tacked onto Meta’s apps in a way that made them even more ubiquitous.
“I expect it to be quite a major product”
Some would call this shameless copying. But it’s clear that Zuckerberg sees Meta’s vast scale, coupled with its ability to quickly adapt to new trends, as its competitive edge. And he’s following that same playbook with Meta AI by putting it everywhere and investing aggressively in foundational models.
“I don’t think that today many people really think about Meta AI when they think about the main AI assistants that people use,” he admits. “But I think that this is the moment where we’re really going to start introducing it to a lot of people, and I expect it to be quite a major product.”
Command Line
/ A newsletter from Alex Heath about the tech industry’s inside conversation.Email (required)SIGN UP
By submitting your email, you agree to our Terms and Privacy Notice. This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
“Compete with everything out there”
:no_upscale():format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25406375/03_Meta_AI_on_Desktop.gif "What Meta AI’s web app looks like on a MacBook screen.")
The new web app for Meta AI. Image: Meta
Today Meta is introducing two open-source Llama 3 models for outside developers to freely use. There’s an 8-billion parameter model and a 70-billion parameter one, both of which will be accessible on all the major cloud providers. (At a very high level, parameters dictate the complexity of a model and its capacity to learn from its training data.)
Llama 3 is a good example of how quickly these AI models are scaling. The biggest version of Llama 2, released last year, had 70 billion parameters, whereas the coming large version of Llama 3 will have over 400 billion, Zuckerberg says. Llama 2 trained on 2 trillion tokens (essentially the words, or units of basic meaning, that compose a model), while the big version of Llama 3 has over 15 trillion tokens. (OpenAI has yet to publicly confirm the number of parameters or tokens in GPT-4.)
A key focus for Llama 3 was meaningfully decreasing its false refusals, or the number of times a model says it can’t answer a prompt that is actually harmless. An example Zuckerberg offers is asking it to make a “killer margarita.” Another is one I gave him during an interview last year, when the earliest version of Meta AI wouldn’t tell me how to break up with someone.
Meta has yet to make the final call on whether to open source the 400-billion-parameter version of Llama 3 since it’s still being trained. Zuckerberg downplays the possibility of it not being open source for safety reasons.
“I don’t think that anything at the level that what we or others in the field are working on in the next year is really in the ballpark of those type of risks,” he says. “So I believe that we will be able to open source it.”
Related
Before the most advanced version of Llama 3 comes out, Zuckerberg says to expect more iterative updates to the smaller models, like longer context windows and more multimodality. He’s coy on exactly how that multimodality will work, though it sounds like generating video akin to OpenAI’s Sora isn’t in the cards yet. Meta wants its assistant to become more personalized, and that could mean eventually being able to generate images in your own likeness.
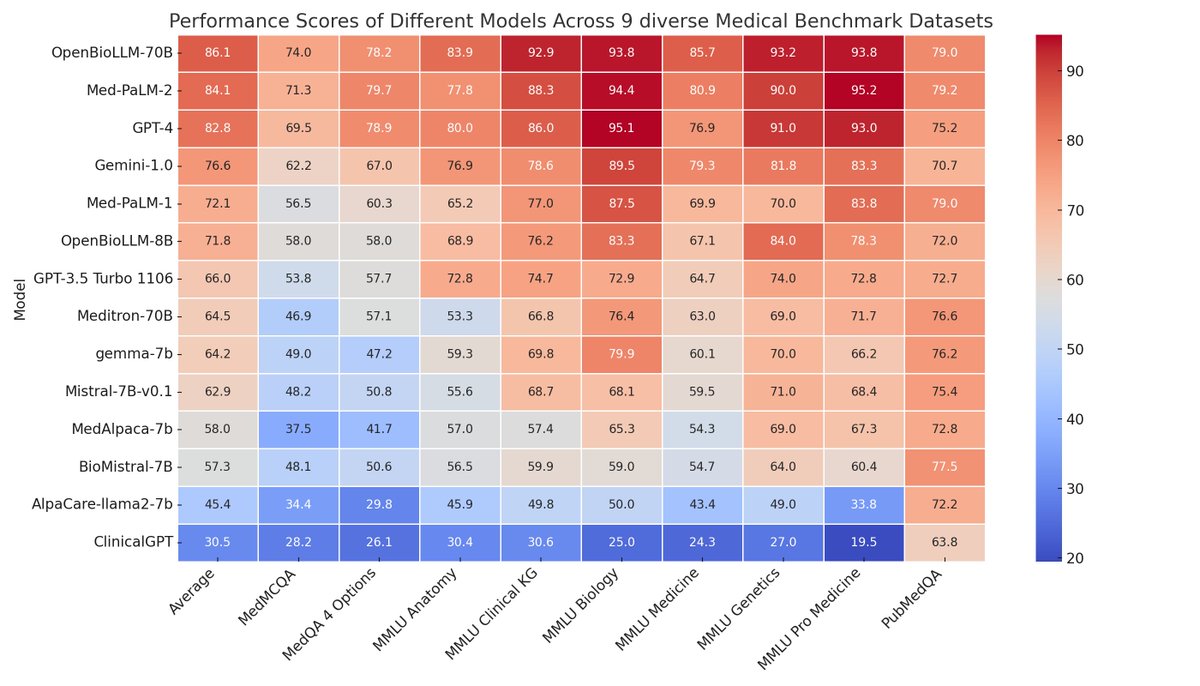
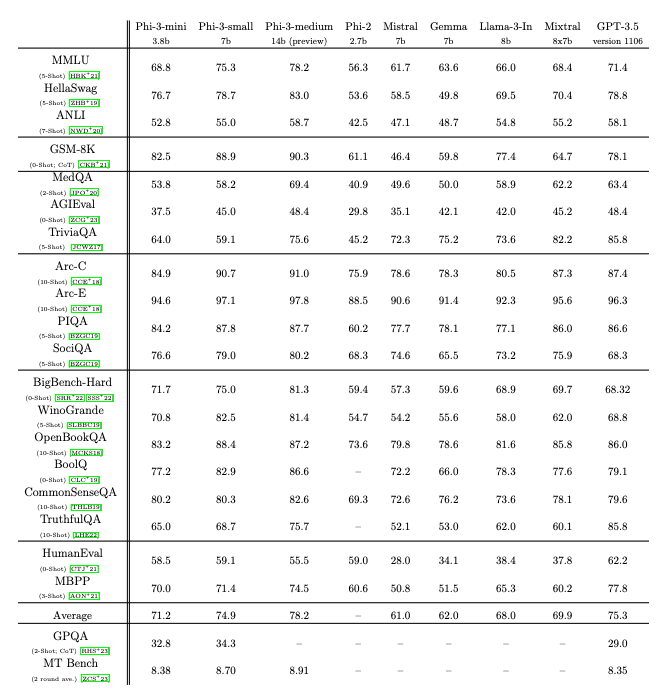
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25406372/Meta_Llama_model_performance.png "Charts showing how Meta’s Llama 3 performs on benchmarks against competing models.")
Here, it’s worth noting that there isn’t yet a consensus on how to properly evaluate the performance of these models in a truly standardized way. Image: Meta
Meta gets hand-wavy when I ask for specifics on the data used for training Llama 3. The total training dataset is seven times larger than Llama 2’s, with four times more code. No Meta user data was used, despite Zuckerberg recently boasting that it’s a larger corpus than the entirety of Common Crawl. Otherwise, Llama 3 uses a mix of “public” internet data and synthetic AI-generated data. Yes, AI is being used to build AI.
The pace of change with AI models is moving so fast that, even if Meta is reasserting itself atop the open-source leaderboard with Llama 3 for now, who knows what tomorrow brings. OpenAI is rumored to be readying GPT-5, which could leapfrog the rest of the industry again. When I ask Zuckerberg about this, he says Meta is already thinking about Llama 4 and 5. To him, it’s a marathon and not a sprint.
“At this point, our goal is not to compete with the open source models,” he says. “It’s to compete with everything out there and to be the leading AI in the world.”
















.jpg")