1/2
I guess you might have tried the demo (Qwen1.5 110B Chat Demo - a Hugging Face Space by Qwen). Now the weights of Qwen1.5-110B are out! Temporarily only the base and chat models, AWQ and GGUF quantized models are about to be released very soon!
Blog: Qwen1.5-110B: The First 100B+ Model of the Qwen1.5 Series
Hugging Face: Qwen/Qwen1.5-110B · Hugging Face (base); Qwen/Qwen1.5-110B-Chat · Hugging Face (chat)
How is it compared with Llama-3-70B? For starters, Qwen1.5-110B at least has several unique features:
- Context length of 32K tokens
- Multilingual support, including English, Chinese, French, Spanish, Japanese, Korean, Vietnamese, etc.
This model is still based on the same architecture of Qwen1.5, and it is a dense model instead of MoE. It has the support of GQA like Qwen1.5-32B.
How many tokens have we trained? Essentially, it is built with very similar pretraining and posttraining recipes and thus it is still far from being sufficiently pretrained.
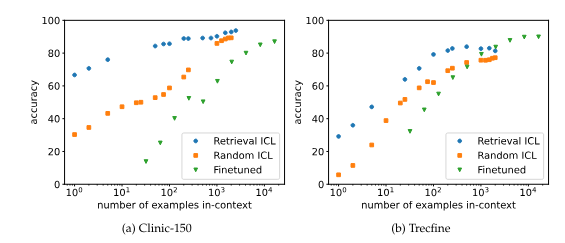
We find that its performance on benchmarks for base language models and we are confident in the base model quality. For the chat model, we have comparable performance in MT-Bench, but we also find some drawbacks in coding, math, logical reasoning. Honestly, we need your testing and feedback to help us better understand the capabilities and limitations of our models.
OK that's it. Get back to work for Qwen2!

 qwenlm.github.io
qwenlm.github.io
2/2
Tmr I'll publish the GGUF
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
I guess you might have tried the demo (Qwen1.5 110B Chat Demo - a Hugging Face Space by Qwen). Now the weights of Qwen1.5-110B are out! Temporarily only the base and chat models, AWQ and GGUF quantized models are about to be released very soon!
Blog: Qwen1.5-110B: The First 100B+ Model of the Qwen1.5 Series
Hugging Face: Qwen/Qwen1.5-110B · Hugging Face (base); Qwen/Qwen1.5-110B-Chat · Hugging Face (chat)
How is it compared with Llama-3-70B? For starters, Qwen1.5-110B at least has several unique features:
- Context length of 32K tokens
- Multilingual support, including English, Chinese, French, Spanish, Japanese, Korean, Vietnamese, etc.
This model is still based on the same architecture of Qwen1.5, and it is a dense model instead of MoE. It has the support of GQA like Qwen1.5-32B.
How many tokens have we trained? Essentially, it is built with very similar pretraining and posttraining recipes and thus it is still far from being sufficiently pretrained.
We find that its performance on benchmarks for base language models and we are confident in the base model quality. For the chat model, we have comparable performance in MT-Bench, but we also find some drawbacks in coding, math, logical reasoning. Honestly, we need your testing and feedback to help us better understand the capabilities and limitations of our models.
OK that's it. Get back to work for Qwen2!
Qwen1.5-110B: The First 100B+ Model of the Qwen1.5 Series
GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction Recently we have witnessed a burst of large-scale models with over 100 billion parameters in the opensource community. These models have demonstrated remarkable performance in both benchmark evaluation and chatbot arena. Today, we release...
2/2
Tmr I'll publish the GGUF
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/2
Qwen1.5-110B running on
@replicate
First pass implementation done with vllm
Try it out!
2/2
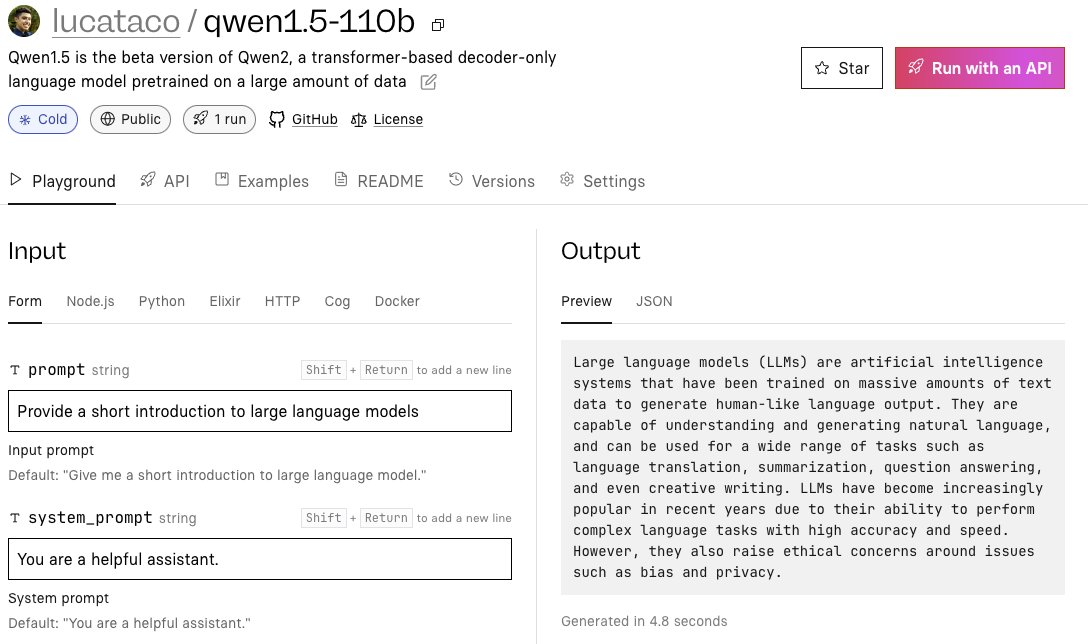
Qwen1.5-110b

 replicate.com
replicate.com
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Qwen1.5-110B running on
@replicate
First pass implementation done with vllm
Try it out!
2/2
Qwen1.5-110b
lucataco/qwen1.5-110b – Run with an API on Replicate
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
Qwen1.5-110B weights are out - run it on your own infra with SkyPilot!
From our AI gallery - a guide to host
@Alibaba_Qwen on your own infra: Serving Qwen1.5 on Your Own Cloud — SkyPilot documentation
Comparison with Llama 3: Qwen1.5-110B: The First 100B+ Model of the Qwen1.5 Series
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Qwen1.5-110B weights are out - run it on your own infra with SkyPilot!
From our AI gallery - a guide to host
@Alibaba_Qwen on your own infra: Serving Qwen1.5 on Your Own Cloud — SkyPilot documentation
Comparison with Llama 3: Qwen1.5-110B: The First 100B+ Model of the Qwen1.5 Series
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/5
Feel free to try this Qwen1.5-110B model preview! I hope you enjoy it! We will release the model weights soon!

2/5
This should be the last episode of the 1.5. No encore probably. Time to say goodbye to the old days and move on to the new series.
3/5
Yes we are going to release it next week. Need some days for the final preparation. Still 32K.
4/5
Wow! your words are so encouraging to us!
5/5
Yeah we will!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Feel free to try this Qwen1.5-110B model preview! I hope you enjoy it! We will release the model weights soon!
Qwen1.5 110B Chat Demo - a Hugging Face Space by Qwen
Discover amazing ML apps made by the community
huggingface.co
2/5
This should be the last episode of the 1.5. No encore probably. Time to say goodbye to the old days and move on to the new series.
3/5
Yes we are going to release it next week. Need some days for the final preparation. Still 32K.
4/5
Wow! your words are so encouraging to us!
5/5
Yeah we will!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196






















 Gorilla: Large Language Model Connected with Massive APIs
Gorilla: Large Language Model Connected with Massive APIs




 :
:  from UC Berkeley
from UC Berkeley




 OCRBench Leaderboard
OCRBench Leaderboard