Meta AI Introduces ReasonIR-8B: A Reasoning-Focused Retriever Optimized for Efficiency and RAG Performance
Meta AI Introduces ReasonIR-8B: A Reasoning-Focused Retriever Optimized for Efficiency and RAG Performance
 www.marktechpost.com
www.marktechpost.com
Meta AI Introduces ReasonIR-8B: A Reasoning-Focused Retriever Optimized for Efficiency and RAG Performance
By Asif Razzaq
April 30, 2025
Addressing the Challenges in Reasoning-Intensive Retrieval
Despite notable progress in retrieval-augmented generation ( RAG ) systems, retrieving relevant information for complex, multi-step reasoning tasks remains a significant challenge. Most retrievers today are trained on datasets composed of short factual questions, which align well with document-level lexical or semantic overlaps. However, they fall short when faced with longer, abstract, or cross-domain queries that require synthesizing dispersed knowledge. In such cases, retrieval errors can propagate through the pipeline, impairing downstream reasoning by large language models (LLMs). While LLM-based rerankers can improve relevance, their substantial computational cost often renders them impractical in real-world deployments.
Meta AI Introduces ReasonIR-8B, a Retriever Built for Reasoning
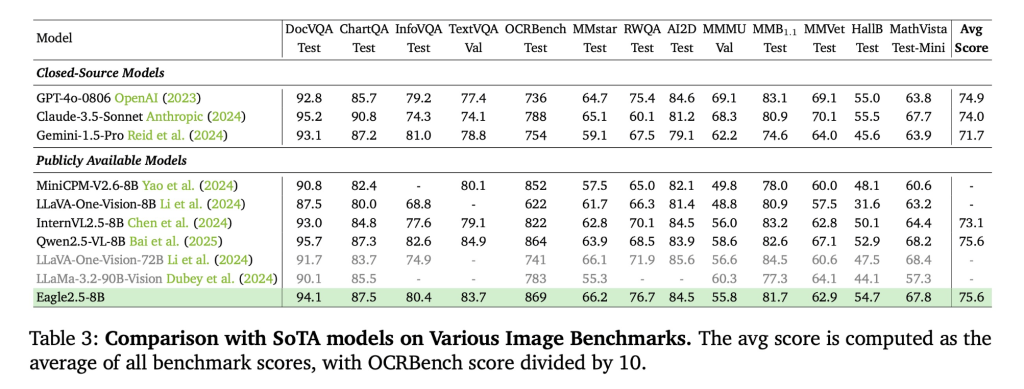
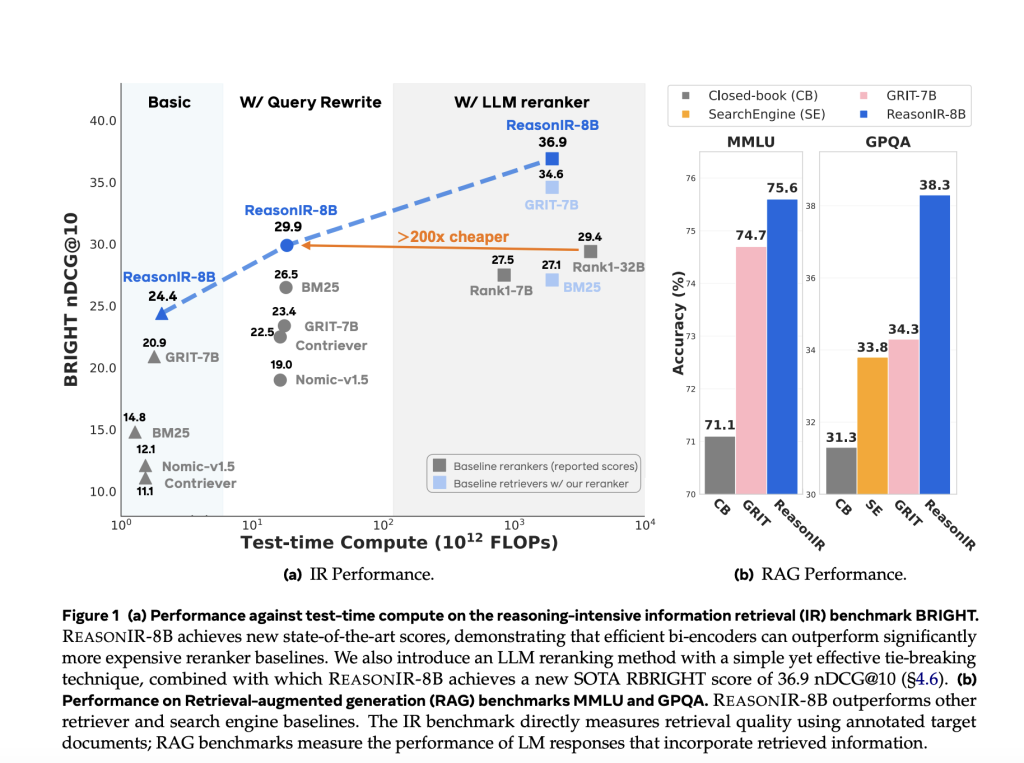
Meta AI has released ReasonIR-8B , a retriever model designed explicitly for reasoning-intensive information retrieval. Trained from LLaMA3.1-8B, the model establishes new performance standards on the BRIGHT benchmark, achieving a normalized Discounted Cumulative Gain (nDCG@10) of 36.9 when used with a lightweight Qwen2.5 reranker. Notably, it surpasses leading reranking models such as Rank1-32B while offering 200× lower inference-time compute , making it significantly more practical for scaled RAG applications.
ReasonIR-8B is trained using a novel data generation pipeline, ReasonIR-SYNTHESIZER , which constructs synthetic queries and document pairs that mirror the challenges posed by real-world reasoning tasks. The model is released open-source on Hugging Face , along with training code and synthetic data tools, enabling further research and reproducibility.
Model Architecture, Training Pipeline, and Key Innovations
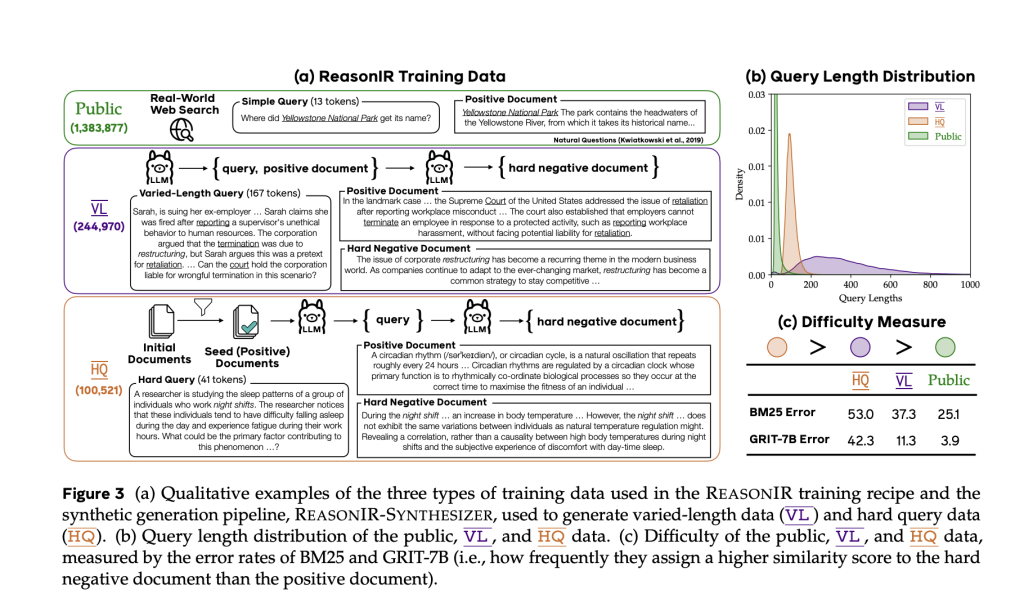
ReasonIR-8B employs a bi-encoder architecture , where queries and documents are encoded independently into embeddings and scored via cosine similarity. The model’s training relies heavily on synthetically generated data tailored to reasoning scenarios. The ReasonIR-SYNTHESIZER pipeline produces two primary types of training instances:
- Varied-Length (VL) Queries : These are long, information-rich queries (up to 2000 tokens), paired with corresponding documents, encouraging the retriever to handle extended contexts effectively.
- Hard Queries (HQ) : Derived from curated documents with high educational value, these queries are designed to require logical inference. Multi-turn prompts are used to construct hard negatives —documents that appear superficially relevant but do not contain the necessary reasoning pathways.
This approach contrasts with conventional negative sampling methods, which often rely on lexical overlap and are less effective for abstract or multi-hop questions.
Additionally, the model’s attention mask is modified from LLaMA’s causal configuration to a bi-directional one , allowing the encoder to consider the full query context symmetrically, which is beneficial for non-sequential semantic alignment.
Empirical Results on IR and RAG Benchmarks
ReasonIR-8B achieves strong performance across several benchmarks:
- BRIGHT Benchmark (Reasoning-Intensive Retrieval):
- 24.4 nDCG@10 on original queries
- 29.9 with GPT-4 rewritten queries
- 36.9 with Qwen2.5 reranking , outperforming larger LLM rerankers at a fraction of the cost
- Retrieval-Augmented Generation (RAG) Tasks:
- +6.4% improvement on MMLU over a closed-book baseline
- +22.6% improvement on GPQA
These gains are consistent across both standard and rewritten queries, with further improvements observed when combining REASONIR-8B with a sparse retriever like BM25 or a lightweight reranker.

Importantly, the model continues to improve as query lengths scale , unlike other retrievers whose performance plateaus or declines. This suggests that ReasonIR-8B can better exploit information-rich queries, making it particularly well-suited for test-time techniques such as query rewriting.
Conclusion
ReasonIR-8B addresses a key bottleneck in reasoning-focused information retrieval by introducing a retriever optimized not only for relevance but also for computational efficiency. Its design—rooted in synthetic training tailored for reasoning, coupled with architectural and data-centric improvements—enables consistent gains in both retrieval and RAG tasks.
By releasing the model, codebase, and training data generation pipeline as open-source tools, Meta AI encourages the research community to extend this work toward more robust, multilingual, and multimodal retrievers. For applications requiring cost-effective and high-quality retrieval under reasoning constraints, ReasonIR-8B represents a compelling and practical solution.
Check out the Paper , HuggingFace Page and GitHub Page . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop