
1/11
@GoogleDeepMind
We’re releasing an updated Gemini 2.5 Pro (I/O edition) to make it even better at coding.
You can build richer web apps, games, simulations and more - all with one prompt.
In @GeminiApp, here's how it transformed images of nature into code to represent unique patterns
https://video.twimg.com/amplify_video/1919768928928051200/vid/avc1/1080x1920/taCOcXbyaVFwRWLw.mp4
2/11
@GoogleDeepMind
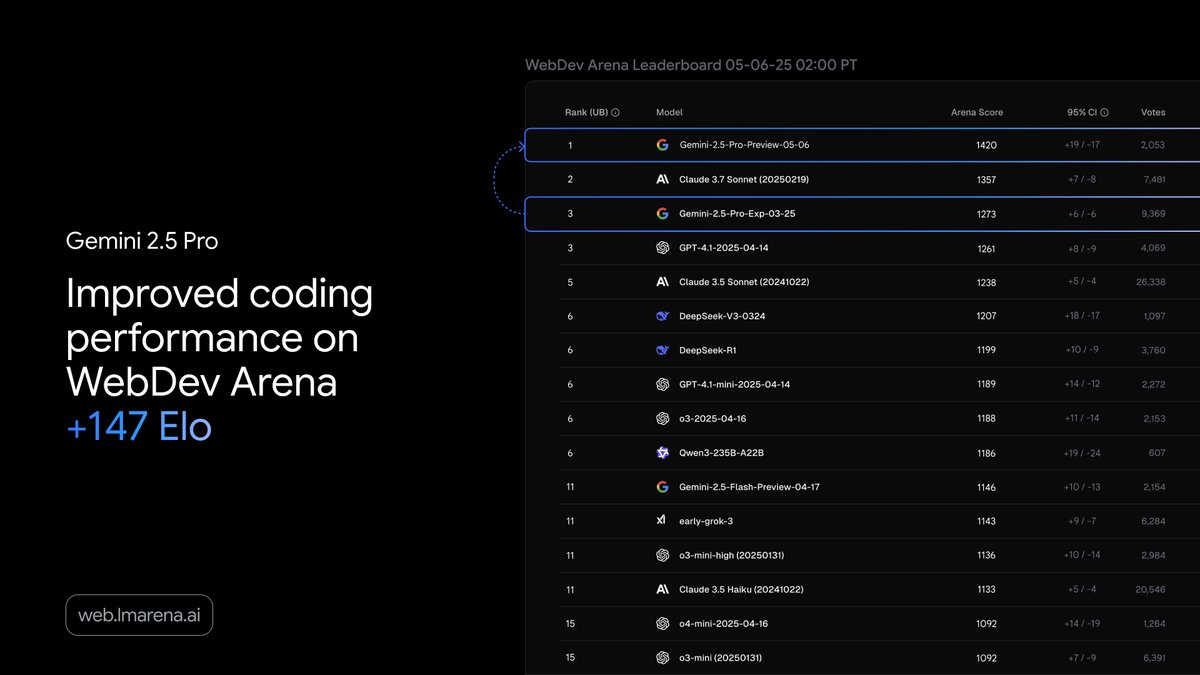
This latest version of Gemini 2.5 Pro leads on the WebDev Arena Leaderboard - which measures how well an AI can code a compelling web app.
It also ranks #1 on @LMArena_ai in Coding.
3/11
@GoogleDeepMind
Beyond creating beautiful UIs, these improvements extend to tasks such as code transformation and editing as well as developing complex agents.
Now available to try in @GeminiApp, @Google AI Studio and @GoogleCloud’s /search?q=#VertexAI platform. Find out more → Build rich, interactive web apps with an updated Gemini 2.5 Pro

4/11
@koltregaskes
Excellent, will we get the non-preview version at I/O?
5/11
@alialobai1
@jacksharkey11 they are cooking …
6/11
@laoddev
that is wild
7/11
@RaniBaghezza
Very cool
8/11
@burny_tech
Gemini is a gift that I can have 100 simple coding ideas per day and draft simple versions of them all
9/11
@thomasxdijkstra
@cursor_ai when
10/11
@shiels_ai
Unreal
11/11
@LarryPanozzo
Anthropic rn
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@GoogleDeepMind
We’re releasing an updated Gemini 2.5 Pro (I/O edition) to make it even better at coding.
You can build richer web apps, games, simulations and more - all with one prompt.
In @GeminiApp, here's how it transformed images of nature into code to represent unique patterns
https://video.twimg.com/amplify_video/1919768928928051200/vid/avc1/1080x1920/taCOcXbyaVFwRWLw.mp4
2/11
@GoogleDeepMind
This latest version of Gemini 2.5 Pro leads on the WebDev Arena Leaderboard - which measures how well an AI can code a compelling web app.
It also ranks #1 on @LMArena_ai in Coding.
3/11
@GoogleDeepMind
Beyond creating beautiful UIs, these improvements extend to tasks such as code transformation and editing as well as developing complex agents.
Now available to try in @GeminiApp, @Google AI Studio and @GoogleCloud’s /search?q=#VertexAI platform. Find out more → Build rich, interactive web apps with an updated Gemini 2.5 Pro
4/11
@koltregaskes
Excellent, will we get the non-preview version at I/O?
5/11
@alialobai1
@jacksharkey11 they are cooking …
6/11
@laoddev
that is wild
7/11
@RaniBaghezza
Very cool
8/11
@burny_tech
Gemini is a gift that I can have 100 simple coding ideas per day and draft simple versions of them all
9/11
@thomasxdijkstra
@cursor_ai when
10/11
@shiels_ai
Unreal
11/11
@LarryPanozzo
Anthropic rn
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/21
@GeminiApp
We just dropped Gemini 2.5 Pro (I/O edition). It’s our most intelligent model that’s even better at coding.
Now, you can build interactive web apps in Canvas with fewer prompts.
Head to Gemini and select “Canvas” in the prompt bar to try it out, and let us know what you’re building in the comments.
https://video.twimg.com/amplify_video/1919768593987727360/vid/avc1/1920x1080/I7FL20DtXMKELQCF.mp4
2/21
@GeminiApp
Interact with the game from our post here: Gemini - lets use noto emoji font https://fonts.google.com/noto/specimen/Noto+Color+Emoji
3/21
@metadjai
Awesome!
4/21
@accrued_int
it's like they are just showing off now
5/21
@ComputerMichau
For me 2.5 Pro is still experimental.
6/21
@arulPrak_
AI agentic commerce ecosystem for travel industry
7/21
@sumbios
Sweet
8/21
@AIdenAIStar
I'd say it is a good model. Made myself a Gemini defender game
https://video.twimg.com/amplify_video/1919783171723292672/vid/avc1/1094x720/Y9mPukwagcRIr7fK.mp4
9/21
@car_heroes
ok started trial. Basic Pacman works. Anything else useful so far is blank screen after a couple of updates. It can't figure it out. New MAC, Sequoia 15.3.2 and Chrome Version 136.0.7103.92. I want this to work but I cant waist time on stuff that should work at launch.
10/21
@rand_longevity
this week is really heating up
11/21
@reallyoptimized
@avidseries You got your own edition! It's completely not woke, apparently.
12/21
@A_MacLullich
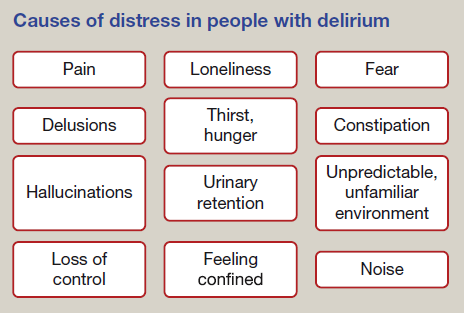
I could also make other simple clinical webapps to help with workflow. For example, if a patient with /search?q=#delirium is distressed, this screen could help doctors and nurses to assess for causes. Clicking on each box would reveal more details.
13/21
@nurullah_kuus
Seems interesting, i ll give it a shot
14/21
@dom_liu__
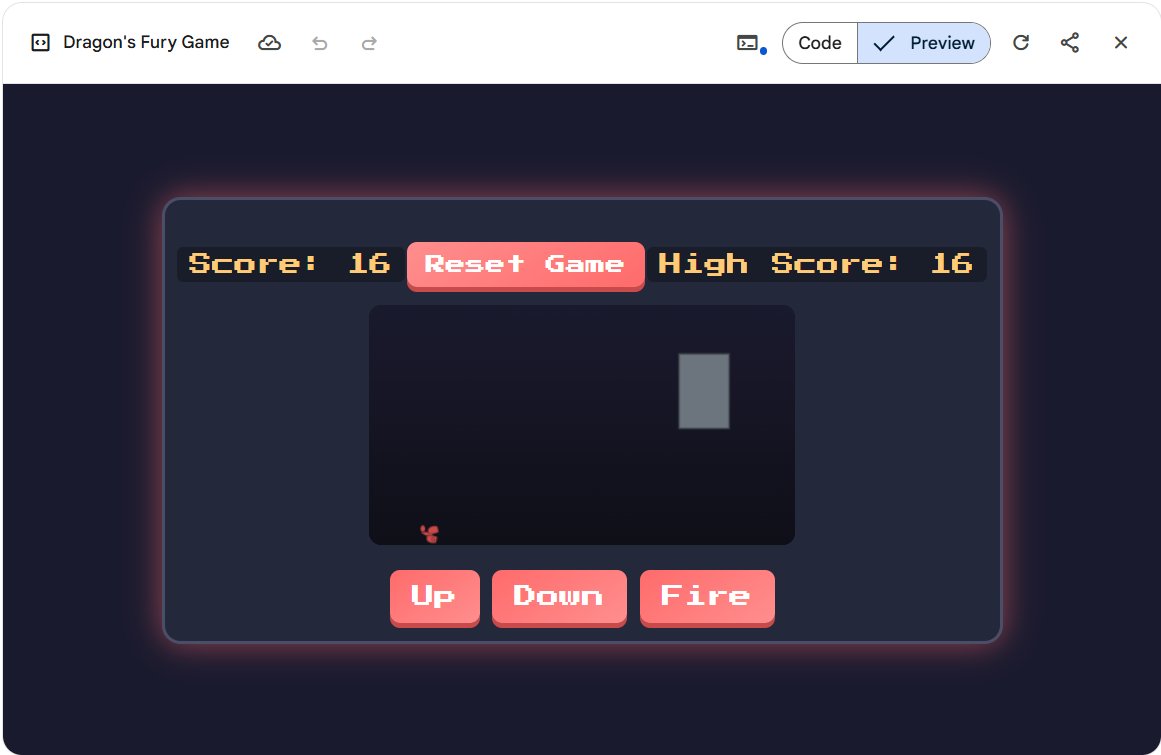
I used Gemini 2.5 Pro to create a Dragon game, and it was so much fun! The code generation was fast, complete, and worked perfectly on the first try with no extra tweaks needed. I have a small question: is this new model using gemini-2.5-pro-preview-05-06?
15/21
@ai_for_success
Why is ir showing Experimental?
16/21
@G33K13765260
damn. it fukked my entire code.. ran back to claude
17/21
@A_MacLullich
Would like to develop a 4AT /search?q=#delirium assessment tool webapp too.
I already have @replit one here: http://www.the4AT.com/trythe4AT - would be nice to have a webapp option for people too.

18/21
@davelalande
I am curious about Internet usage. I mainly use X and AI, and I rarely traverse the web anymore. How many new websites are finding success, and is the rest of the world using the web like it's 1999? Will chat models build an app for one-time use with that chat session?
19/21
@arthurSlee
Using this solar system prompt - I initially got an error. However after the fix, it did create the best looking solar system in one prompt.
Gemini - Solar System Visualization HTML Page
Nice work. I also like how easy it is to share executing code.
20/21
@AI_Techie_Arun
Wow!!!! Amazing
But what's the I/O edition?
21/21
@JvShah124
Great
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@GeminiApp
We just dropped Gemini 2.5 Pro (I/O edition). It’s our most intelligent model that’s even better at coding.
Now, you can build interactive web apps in Canvas with fewer prompts.
Head to Gemini and select “Canvas” in the prompt bar to try it out, and let us know what you’re building in the comments.
https://video.twimg.com/amplify_video/1919768593987727360/vid/avc1/1920x1080/I7FL20DtXMKELQCF.mp4
2/21
@GeminiApp
Interact with the game from our post here: Gemini - lets use noto emoji font https://fonts.google.com/noto/specimen/Noto+Color+Emoji
3/21
@metadjai
Awesome!
4/21
@accrued_int
it's like they are just showing off now
5/21
@ComputerMichau
For me 2.5 Pro is still experimental.
6/21
@arulPrak_
AI agentic commerce ecosystem for travel industry
7/21
@sumbios
Sweet
8/21
@AIdenAIStar
I'd say it is a good model. Made myself a Gemini defender game
https://video.twimg.com/amplify_video/1919783171723292672/vid/avc1/1094x720/Y9mPukwagcRIr7fK.mp4
9/21
@car_heroes
ok started trial. Basic Pacman works. Anything else useful so far is blank screen after a couple of updates. It can't figure it out. New MAC, Sequoia 15.3.2 and Chrome Version 136.0.7103.92. I want this to work but I cant waist time on stuff that should work at launch.
10/21
@rand_longevity
this week is really heating up
11/21
@reallyoptimized
@avidseries You got your own edition! It's completely not woke, apparently.
12/21
@A_MacLullich
I could also make other simple clinical webapps to help with workflow. For example, if a patient with /search?q=#delirium is distressed, this screen could help doctors and nurses to assess for causes. Clicking on each box would reveal more details.
13/21
@nurullah_kuus
Seems interesting, i ll give it a shot
14/21
@dom_liu__
I used Gemini 2.5 Pro to create a Dragon game, and it was so much fun! The code generation was fast, complete, and worked perfectly on the first try with no extra tweaks needed. I have a small question: is this new model using gemini-2.5-pro-preview-05-06?
15/21
@ai_for_success
Why is ir showing Experimental?
16/21
@G33K13765260
damn. it fukked my entire code.. ran back to claude
17/21
@A_MacLullich
Would like to develop a 4AT /search?q=#delirium assessment tool webapp too.
I already have @replit one here: http://www.the4AT.com/trythe4AT - would be nice to have a webapp option for people too.
18/21
@davelalande
I am curious about Internet usage. I mainly use X and AI, and I rarely traverse the web anymore. How many new websites are finding success, and is the rest of the world using the web like it's 1999? Will chat models build an app for one-time use with that chat session?
19/21
@arthurSlee
Using this solar system prompt - I initially got an error. However after the fix, it did create the best looking solar system in one prompt.
Gemini - Solar System Visualization HTML Page
Nice work. I also like how easy it is to share executing code.
20/21
@AI_Techie_Arun
Wow!!!! Amazing
But what's the I/O edition?
21/21
@JvShah124
Great
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@slow_developer
now this is very interesting...
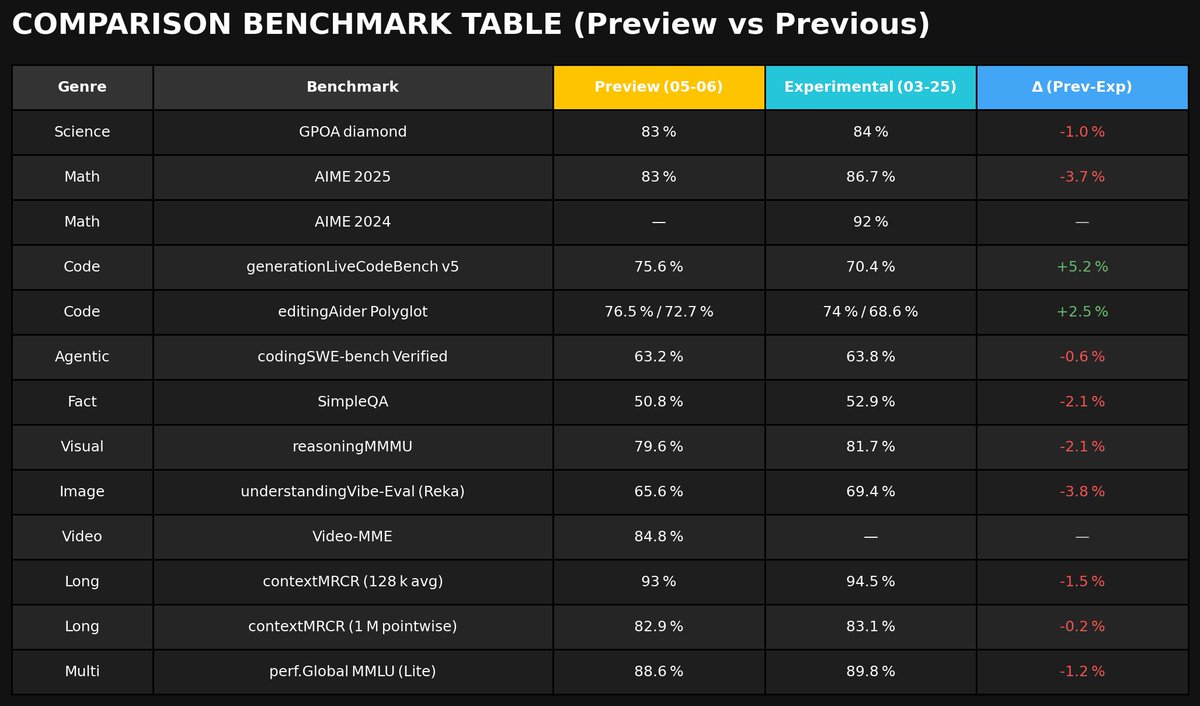
the new gemini 2.5 pro model seems to have fallen behind in many areas
coding is the only thing it still handles well.
so, does that mean this model was built mainly for coding?
2/11
@Shawnryan96
I have not seen any issues in real world use. In fact image reasoning seems better
3/11
@slow_developer
i haven’t tried anything except for the code, but this is a comparison-based chart with the previous version
4/11
@psv2522
its not fallen behind the new model is probably a distillation+trained for coding much better.
5/11
@slow_developer
much like what Anthropic did with 3.5 to their next updated version 3.6?
6/11
@sdmat123
That's how tuning works, yes. You can see the same kind of differences in Sonnet 3.7 vs 3.6.
3.7 normal regressed quantitatively on MMLU and ARC even with base level reasoning skills on 3.6. It is regarded as subjectively worse in many domains outside of coding.
7/11
@slow_developer
agree
[Quoted tweet]
much like what Anthropic did with 3.5 to their next updated version 3.6?
8/11
@mhdfaran
It’s interesting how coding is still the highlight here.
9/11
@NFTMentis
Wait - what?
Is this a response the to @OpenAI news re: @windsurf_ai ?
10/11
@K_to_Macro
This shows the weakness of RL
11/11
@humancore_ai
I don’t care. I want one that is a beast at coding, there are plenty of general purpose ones.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@slow_developer
now this is very interesting...
the new gemini 2.5 pro model seems to have fallen behind in many areas
coding is the only thing it still handles well.
so, does that mean this model was built mainly for coding?
2/11
@Shawnryan96
I have not seen any issues in real world use. In fact image reasoning seems better
3/11
@slow_developer
i haven’t tried anything except for the code, but this is a comparison-based chart with the previous version
4/11
@psv2522
its not fallen behind the new model is probably a distillation+trained for coding much better.
5/11
@slow_developer
much like what Anthropic did with 3.5 to their next updated version 3.6?
6/11
@sdmat123
That's how tuning works, yes. You can see the same kind of differences in Sonnet 3.7 vs 3.6.
3.7 normal regressed quantitatively on MMLU and ARC even with base level reasoning skills on 3.6. It is regarded as subjectively worse in many domains outside of coding.
7/11
@slow_developer
agree
[Quoted tweet]
much like what Anthropic did with 3.5 to their next updated version 3.6?
8/11
@mhdfaran
It’s interesting how coding is still the highlight here.
9/11
@NFTMentis
Wait - what?
Is this a response the to @OpenAI news re: @windsurf_ai ?
10/11
@K_to_Macro
This shows the weakness of RL
11/11
@humancore_ai
I don’t care. I want one that is a beast at coding, there are plenty of general purpose ones.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@OfficialLoganK
Gemini 2.5 Pro just got an upgrade & is now even better at coding, with significant gains in front-end web dev, editing, and transformation.
We also fixed a bunch of function calling issues that folks have been reporting, it should now be much more reliable. More details in
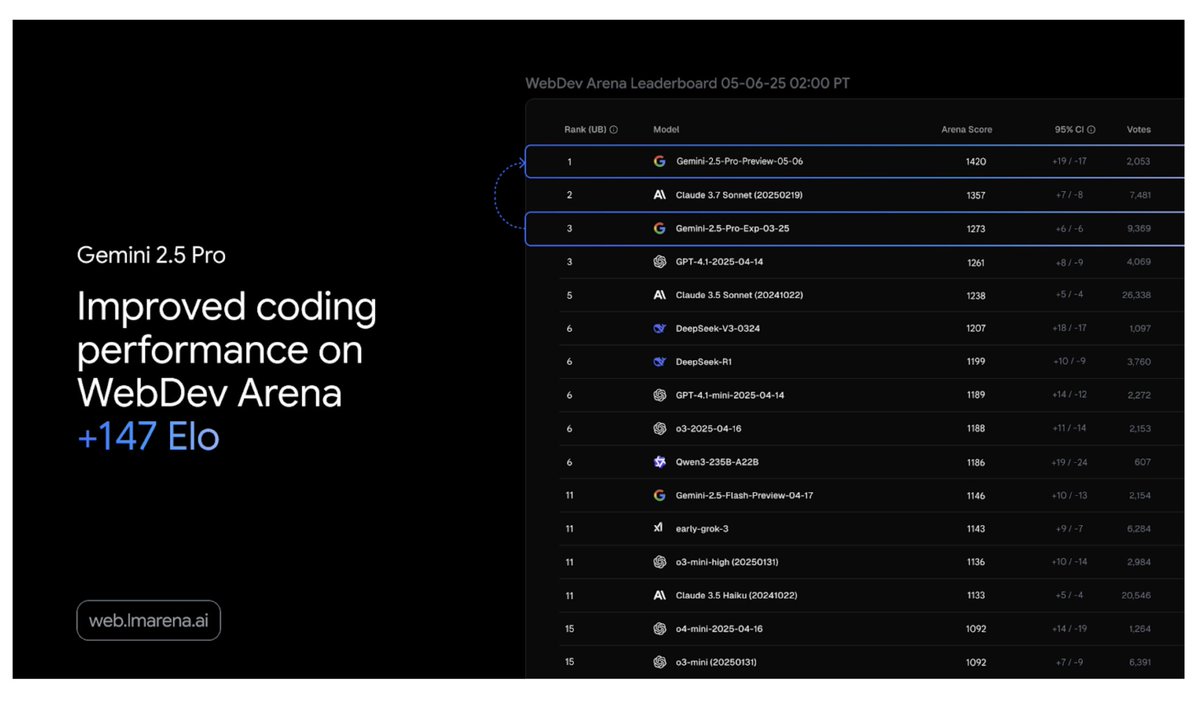
2/11
@OfficialLoganK
The new model, "gemini-2.5-pro-preview-05-06" is the direct successor / replacement of the previous version (03-25), if you are using the old model, no change is needed, it should auto route to the new version with the same price and rate limits.
Gemini 2.5 Pro Preview: even better coding performance- Google Developers Blog
3/11
@OfficialLoganK
And don't just take our word for it:
“The updated Gemini 2.5 Pro achieves leading performance on our junior-dev evals. It was the first-ever model that solved one of our evals involving a larger refactor of a request routing backend. It felt like a more senior developer because it was able to make correct judgement calls and choose good abstractions.”
– Silas Alberti, Founding Team, Cognition
4/11
@OfficialLoganK
Developers really like 2.5 Pro:
“We found Gemini 2.5 Pro to be the best frontier model when it comes to "capability over latency" ratio. I look forward to rolling it out on Replit Agent whenever a latency-sensitive task needs to be accomplished with a high degree of reliability.”
– Michele Catasta, President, Replit
5/11
@OfficialLoganK
Super excited to see how everyone uses the new 2.5 Pro model, and I hope you all enjoy a little pre-IO launch : )
The team has been super excited to get this into the hands of everyone so we decided not to wait until IO.
6/11
@JonathanRoseD
Does gemini-2.5-pro-preview-05-06 improve any other aspects other than coding?
7/11
@OfficialLoganK
Mostly coding !
8/11
@devgovz
Ok, what about 2.0 Flash with image generation? When will the experimental period end?
9/11
@OfficialLoganK
Soon!
10/11
@frantzenrichard
Great! How about that image generation?
11/11
@OfficialLoganK
: )
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@OfficialLoganK
Gemini 2.5 Pro just got an upgrade & is now even better at coding, with significant gains in front-end web dev, editing, and transformation.
We also fixed a bunch of function calling issues that folks have been reporting, it should now be much more reliable. More details in
2/11
@OfficialLoganK
The new model, "gemini-2.5-pro-preview-05-06" is the direct successor / replacement of the previous version (03-25), if you are using the old model, no change is needed, it should auto route to the new version with the same price and rate limits.
Gemini 2.5 Pro Preview: even better coding performance- Google Developers Blog
3/11
@OfficialLoganK
And don't just take our word for it:
“The updated Gemini 2.5 Pro achieves leading performance on our junior-dev evals. It was the first-ever model that solved one of our evals involving a larger refactor of a request routing backend. It felt like a more senior developer because it was able to make correct judgement calls and choose good abstractions.”
– Silas Alberti, Founding Team, Cognition
4/11
@OfficialLoganK
Developers really like 2.5 Pro:
“We found Gemini 2.5 Pro to be the best frontier model when it comes to "capability over latency" ratio. I look forward to rolling it out on Replit Agent whenever a latency-sensitive task needs to be accomplished with a high degree of reliability.”
– Michele Catasta, President, Replit
5/11
@OfficialLoganK
Super excited to see how everyone uses the new 2.5 Pro model, and I hope you all enjoy a little pre-IO launch : )
The team has been super excited to get this into the hands of everyone so we decided not to wait until IO.
6/11
@JonathanRoseD
Does gemini-2.5-pro-preview-05-06 improve any other aspects other than coding?
7/11
@OfficialLoganK
Mostly coding !
8/11
@devgovz
Ok, what about 2.0 Flash with image generation? When will the experimental period end?
9/11
@OfficialLoganK
Soon!
10/11
@frantzenrichard
Great! How about that image generation?
11/11
@OfficialLoganK
: )
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@demishassabis
Very excited to share the best coding model we’ve ever built! Today we’re launching Gemini 2.5 Pro Preview 'I/O edition' with massively improved coding capabilities. Ranks no.1 on LMArena in Coding and no.1 on the WebDev Arena Leaderboard.
It’s especially good at building interactive web apps - this demo shows how it can be helpful for prototyping ideas. Try it in @GeminiApp, Vertex AI, and AI Studio Google AI Studio
Enjoy the pre-I/O goodies !
https://video.twimg.com/amplify_video/1919778857193816064/vid/avc1/1920x1080/FtMuHzKJiZuaP5Uy.mp4
2/11
@demishassabis
It’s been amazing to see the response to Gemini 2.5 series so far - and we're continuing to rev in response to feedback, so keep it coming !
https://blog.google/products/gemini/gemini-2-5-pro-updates
3/11
@demishassabis
just a casual +147 elo rating improvement... no big deal
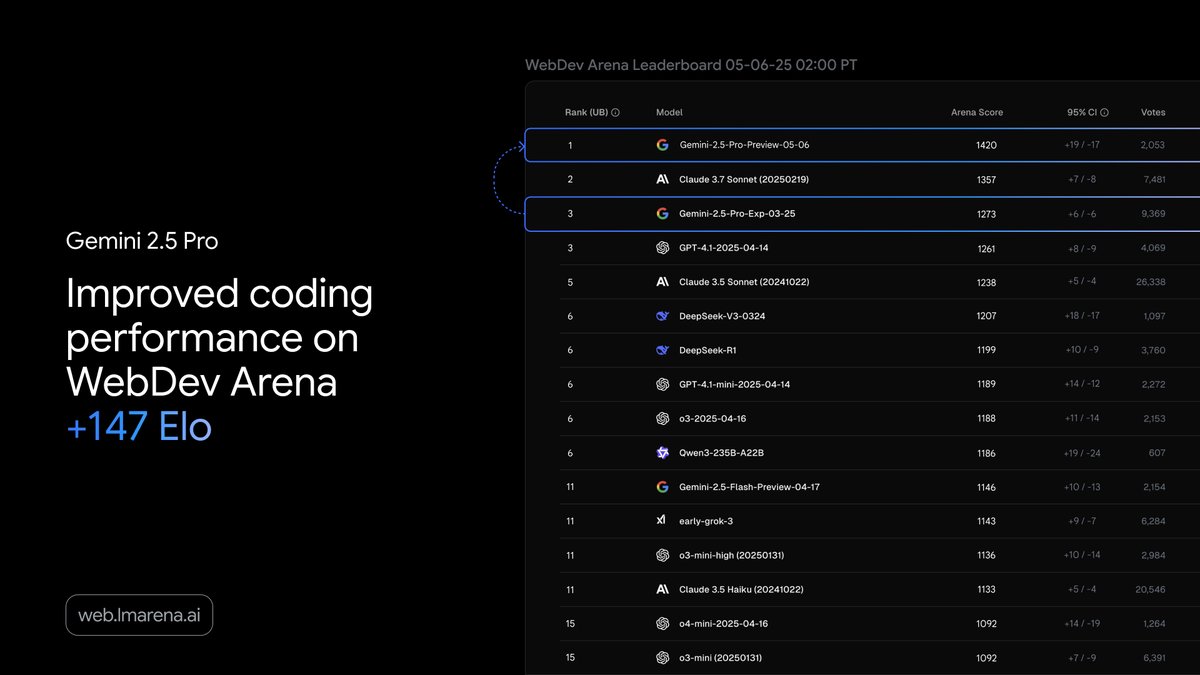
4/11
@johnseach
Gemini is now the best coding LLM by far. It is excelling at astrophysics code where all other fail. Google is now the AI coding gold standard.
5/11
@WesRothMoney
love it!
I built a full city traffic simulator in under 20 minutes.
here's the timelapse from v1.0 to (almost) done.
https://video.twimg.com/amplify_video/1919886890997841920/vid/avc1/1280x720/neHj9PPTfPxeaU3U.mp4
6/11
@botanium
This is mind blowing
7/11
@_philschmid
Lets go
8/11
@A_MacLullich
Excited to try this - will be interesting to compare with others? Any special use cases?
9/11
@ApollonVisual
congrats on the update. I feel that coding focused LLMs will accelerate progress expotentially
10/11
@JacobColling
Excited to try this in Cursor!
11/11
@SebastianKits
Loving the single-shot quality, but would love to see more work towards half-autonomous agentic usage. E.g when giving a task to plan and execute a larger MVP, 2.5 pro (and all other models) often do things in a bad order that leads to badly defined styleguides, not very cohesive view specs etc. This is not a problem of 2.5 pro, all models of various providers do this without excessive guidance.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@demishassabis
Very excited to share the best coding model we’ve ever built! Today we’re launching Gemini 2.5 Pro Preview 'I/O edition' with massively improved coding capabilities. Ranks no.1 on LMArena in Coding and no.1 on the WebDev Arena Leaderboard.
It’s especially good at building interactive web apps - this demo shows how it can be helpful for prototyping ideas. Try it in @GeminiApp, Vertex AI, and AI Studio Google AI Studio
Enjoy the pre-I/O goodies !
https://video.twimg.com/amplify_video/1919778857193816064/vid/avc1/1920x1080/FtMuHzKJiZuaP5Uy.mp4
2/11
@demishassabis
It’s been amazing to see the response to Gemini 2.5 series so far - and we're continuing to rev in response to feedback, so keep it coming !
https://blog.google/products/gemini/gemini-2-5-pro-updates
3/11
@demishassabis
just a casual +147 elo rating improvement... no big deal
4/11
@johnseach
Gemini is now the best coding LLM by far. It is excelling at astrophysics code where all other fail. Google is now the AI coding gold standard.
5/11
@WesRothMoney
love it!
I built a full city traffic simulator in under 20 minutes.
here's the timelapse from v1.0 to (almost) done.
https://video.twimg.com/amplify_video/1919886890997841920/vid/avc1/1280x720/neHj9PPTfPxeaU3U.mp4
6/11
@botanium
This is mind blowing
7/11
@_philschmid
Lets go
8/11
@A_MacLullich
Excited to try this - will be interesting to compare with others? Any special use cases?
9/11
@ApollonVisual
congrats on the update. I feel that coding focused LLMs will accelerate progress expotentially
10/11
@JacobColling
Excited to try this in Cursor!
11/11
@SebastianKits
Loving the single-shot quality, but would love to see more work towards half-autonomous agentic usage. E.g when giving a task to plan and execute a larger MVP, 2.5 pro (and all other models) often do things in a bad order that leads to badly defined styleguides, not very cohesive view specs etc. This is not a problem of 2.5 pro, all models of various providers do this without excessive guidance.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


























 AssetGen 2.0 consist of 2 models: one to generate the 3D Mesh, & a second one to generate textures.
AssetGen 2.0 consist of 2 models: one to generate the 3D Mesh, & a second one to generate textures. Technological Advancements:
Technological Advancements: Current Use and Future Plans:
Current Use and Future Plans: More details about this
More details about this 









