AI Agents Now Write Code in Parallel: OpenAI Introduces Codex, a Cloud-Based Coding Agent Inside ChatGPT

www.marktechpost.com
AI Agents Now Write Code in Parallel: OpenAI Introduces Codex, a Cloud-Based Coding Agent Inside ChatGPT
By
Asif Razzaq
May 16, 2025
OpenAI has introduced
Codex , a cloud-native software engineering agent integrated into ChatGPT, signaling a new era in AI-assisted software development. Unlike traditional coding assistants, Codex is not just a tool for autocompletion—it acts as a cloud-based agent capable of autonomously performing a wide range of programming tasks, from writing and debugging code to running tests and generating pull requests.
A Shift Toward Parallel, Agent-Driven Development
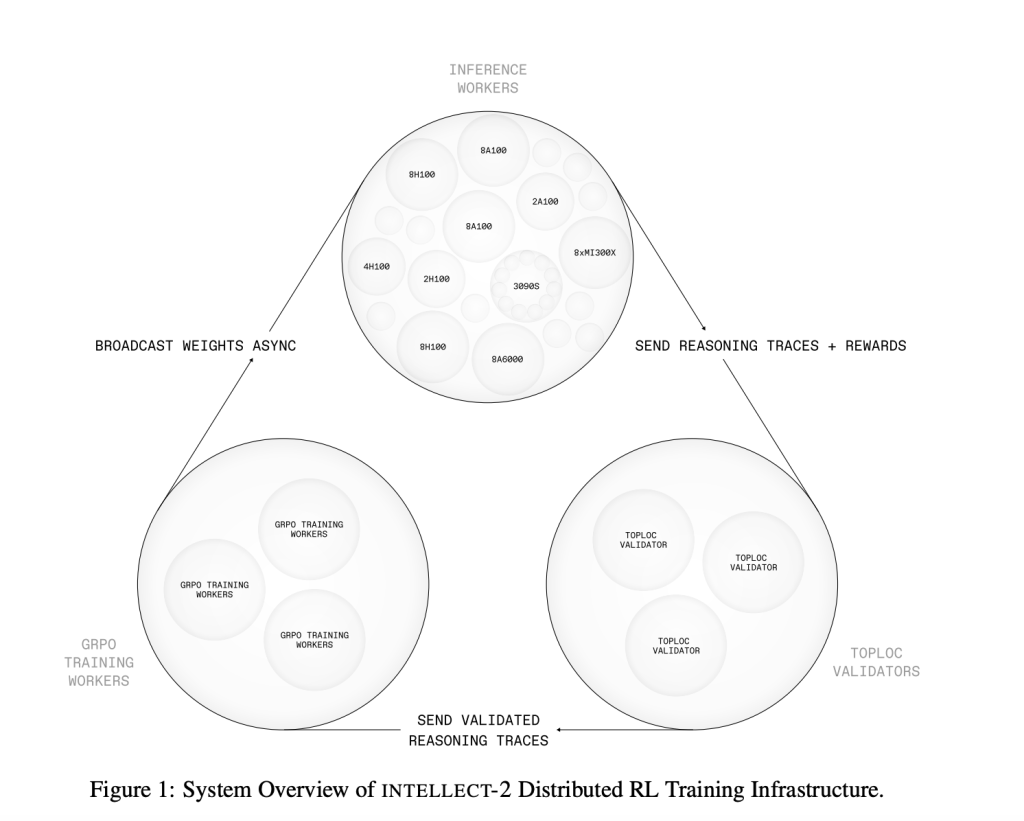
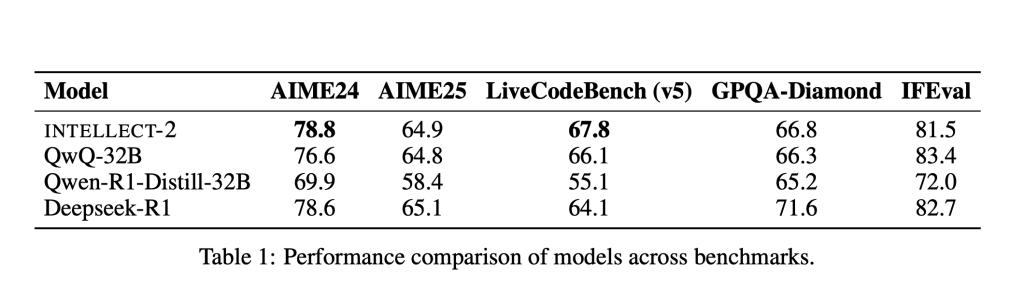
At the core of Codex is
codex-1 , a fine-tuned version of OpenAI’s reasoning model, optimized specifically for software engineering workflows. Codex can handle multiple tasks simultaneously, operating inside isolated cloud sandboxes that are preloaded with the user’s codebase. Each request is handled in its own environment, allowing users to delegate different coding operations in parallel without disrupting their local development environment.
This architecture introduces a fundamentally new approach to software engineering—developers now interact with an agent that behaves more like a collaborative teammate than a static code tool. You can ask Codex to “fix a bug,” “add logging,” or “refactor this module,” and it will return a verifiable response, including diffs, terminal logs, and test results. If the output looks good, you can copy the patch directly into your repository—or ask for revisions.
Embedded Within ChatGPT, Accessible to Teams
Codex lives in the ChatGPT interface, currently available to
Pro, Team, and Enterprise users , with broader access expected soon. The interface includes a dedicated sidebar where developers can describe what they want in natural language. Codex then interprets the intent and handles the coding behind the scenes, surfacing results for review and feedback.
This integration offers a significant boost to developer productivity. As OpenAI notes, Codex is designed to take on many of the repetitive or boilerplate-heavy aspects of coding—allowing developers to focus on architecture, design, and higher-order problem solving. In one case, an OpenAI staffer even “checked in two bug fixes written entirely by Codex,” all while working on unrelated tasks.
Codex Understands Your Codebase
What makes Codex more than just a smart code generator is its context-awareness. Each instance runs with full access to your project’s file structure, coding conventions, and style. This allows it to write code that aligns with your team’s standards—whether you’re using Flask or FastAPI, React or Vue, or a custom internal framework.
Codex’s ability to adapt to a codebase makes it particularly useful for large-scale enterprise teams and open-source maintainers. It supports workflows like branch-based pull request generation, test suite execution, and static analysis—all initiated by simple English prompts. Over time, it learns the nuances of the repository it works in, leading to better suggestions and more accurate code synthesis.
Broader Implications: Lowering the Barrier to Software Creation
OpenAI frames Codex as a research preview, but its long-term vision is clear: AI will increasingly take over much of the routine work involved in building software. The aim isn’t to replace developers but to
democratize software creation , allowing more people—especially non-traditional developers—to build working applications using natural language alone.
In this light, Codex is not just a coding tool, but a stepping stone toward a world where software development is collaborative between humans and machines. It brings software creation closer to the realm of design and ideation, and further away from syntax and implementation details.
What’s Next?
Codex is rolling out gradually, with usage limits in place during the preview phase. OpenAI is gathering feedback to refine the agent’s capabilities, improve safety, and optimize its performance across different environments and languages.
Whether you’re a solo developer, part of a DevOps team, or leading an enterprise platform, Codex represents a significant shift in how code is written, tested, and shipped. As AI agents continue to mature, the future of software engineering will be less about writing every line yourself—and more about knowing what to build, and asking the right questions.
Check out the
Details here . All credit for this research goes to the researchers of this project. Also, feel free to follow us on
Twitter and don’t forget to join our
90k+ ML SubReddit .

 It’s here: sub-10 second video generation is now real with LTX-Video-13B-distilled!
It’s here: sub-10 second video generation is now real with LTX-Video-13B-distilled! Try it now on Hugging Face
Try it now on Hugging Face





 Open Molecules 2025 (OMol25): A dataset for molecular discovery with simulations of large atomic systems.
Open Molecules 2025 (OMol25): A dataset for molecular discovery with simulations of large atomic systems. Adjoint Sampling: A scalable algorithm for training generative models based on scalar rewards.
Adjoint Sampling: A scalable algorithm for training generative models based on scalar rewards. FAIR and the Rothschild Foundation Hospital partnered on a large-scale study that reveals striking parallels between language development in humans and LLMs.
FAIR and the Rothschild Foundation Hospital partnered on a large-scale study that reveals striking parallels between language development in humans and LLMs.