Chinese AI startup Moonshot releases open-source Kimi K2 model that outperforms OpenAI and Anthropic on coding tasks with breakthrough agentic capabilities and competitive pricing.

venturebeat.com
Moonshot AI’s Kimi K2 outperforms GPT-4 in key benchmarks — and it’s free
Michael Nuñez@MichaelFNunez
July 11, 2025 3:56 PM
Credit: VentureBeat made with Midjourney
Moonshot AI, the Chinese artificial intelligence startup behind the popular
Kimi chatbot, released an open-source language model on Friday that directly challenges proprietary systems from
OpenAI and
Anthropic with particularly strong performance on coding and autonomous agent tasks.
The new model, called
Kimi K2, features 1 trillion total parameters with 32 billion activated parameters in a mixture-of-experts architecture. The company is releasing two versions: a foundation model for researchers and developers, and an instruction-tuned variant optimized for chat and autonomous agent applications.
? Hello, Kimi K2! Open-Source Agentic Model!
? 1T total / 32B active MoE model
? SOTA on SWE Bench Verified, Tau2 & AceBench among open models
?Strong in coding and agentic tasks
? Multimodal & thought-mode not supported for now
With Kimi K2, advanced agentic intelligence…
pic.twitter.com/PlRQNrg9JL
— Kimi.ai (@Kimi_Moonshot)
July 11, 2025
“Kimi K2 does not just answer; it acts,” the company stated in its
announcement blog. “With Kimi K2, advanced agentic intelligence is more open and accessible than ever. We can’t wait to see what you build.”
The model’s standout feature is its optimization for “agentic” capabilities — the ability to autonomously use tools, write and execute code, and complete complex multi-step tasks without human intervention. In benchmark tests,
Kimi K2 achieved 65.8% accuracy on
SWE-bench Verified, a challenging software engineering benchmark, outperforming most open-source alternatives and matching some proprietary models.
David meets Goliath: How Kimi K2 outperforms Silicon Valley’s billion-dollar models
The performance metrics tell a story that should make executives at
OpenAI and
Anthropic take notice.
Kimi K2-Instruct doesn’t just compete with the big players — it systematically outperforms them on tasks that matter most to enterprise customers.
On
LiveCodeBench, arguably the most realistic coding benchmark available,
Kimi K2 achieved 53.7% accuracy, decisively beating
DeepSeek-V3‘s 46.9% and
GPT-4.1‘s 44.7%. More striking still: it scored 97.4% on
MATH-500 compared to GPT-4.1’s 92.4%, suggesting Moonshot has cracked something fundamental about mathematical reasoning that has eluded larger, better-funded competitors.
But here’s what the benchmarks don’t capture:
Moonshot is achieving these results with a model that costs a fraction of what incumbents spend on training and inference. While OpenAI burns through hundreds of millions on compute for incremental improvements, Moonshot appears to have found a more efficient path to the same destination. It’s a classic innovator’s dilemma playing out in real time — the scrappy outsider isn’t just matching the incumbent’s performance, they’re doing it better, faster, and cheaper.
The implications extend beyond mere bragging rights. Enterprise customers have been waiting for AI systems that can actually complete complex workflows autonomously, not just generate impressive demos. Kimi K2’s strength on
SWE-bench Verified suggests it might finally deliver on that promise.
The MuonClip breakthrough: Why this optimizer could reshape AI training economics
Buried in Moonshot’s technical documentation is a detail that could prove more significant than the model’s benchmark scores: their development of the
MuonClip optimizer, which enabled stable training of a trillion-parameter model “with zero training instability.”
This isn’t just an engineering achievement — it’s potentially a paradigm shift. Training instability has been the hidden tax on large language model development, forcing companies to restart expensive training runs, implement costly safety measures, and accept suboptimal performance to avoid crashes. Moonshot’s solution directly addresses exploding attention logits by rescaling weight matrices in query and key projections, essentially solving the problem at its source rather than applying band-aids downstream.
The economic implications are staggering. If
MuonClip proves generalizable — and
Moonshot suggests it is — the technique could dramatically reduce the computational overhead of training large models. In an industry where training costs are measured in tens of millions of dollars, even modest efficiency gains translate to competitive advantages measured in quarters, not years.
More intriguingly, this represents a fundamental divergence in optimization philosophy. While Western AI labs have largely converged on variations of AdamW, Moonshot’s bet on Muon variants suggests they’re exploring genuinely different mathematical approaches to the optimization landscape. Sometimes the most important innovations come not from scaling existing techniques, but from questioning their foundational assumptions entirely.
Open source as competitive weapon: Moonshot’s radical pricing strategy targets big tech’s profit centers
Moonshot’s decision to open-source
Kimi K2 while simultaneously offering competitively priced API access reveals a sophisticated understanding of market dynamics that goes well beyond altruistic open-source principles.
At $0.15 per million input tokens for cache hits and $2.50 per million output tokens,
Moonshot is pricing aggressively below
OpenAI and
Anthropic while offering comparable — and in some cases superior — performance. But the real strategic masterstroke is the dual availability: enterprises can start with the API for immediate deployment, then migrate to self-hosted versions for cost optimization or compliance requirements.
This creates a trap for incumbent providers. If they match Moonshot’s pricing, they compress their own margins on what has been their most profitable product line. If they don’t, they risk customer defection to a model that performs just as well for a fraction of the cost. Meanwhile, Moonshot builds market share and ecosystem adoption through both channels simultaneously.
The open-source component isn’t charity — it’s customer acquisition. Every developer who downloads and experiments with
Kimi K2 becomes a potential enterprise customer. Every improvement contributed by the community reduces Moonshot’s own development costs. It’s a flywheel that leverages the global developer community to accelerate innovation while building competitive moats that are nearly impossible for closed-source competitors to replicate.
From demo to reality: Why Kimi K2’s agent capabilities signal the end of chatbot theater
The demonstrations
Moonshot shared on social media reveal something more significant than impressive technical capabilities—they show AI finally graduating from parlor tricks to practical utility.
Consider the salary analysis example:
Kimi K2 didn’t just answer questions about data, it autonomously executed 16 Python operations to generate statistical analysis and interactive visualizations. The London concert planning demonstration involved 17 tool calls across multiple platforms — search, calendar, email, flights, accommodations, and restaurant bookings. These aren’t curated demos designed to impress; they’re examples of AI systems actually completing the kind of complex, multi-step workflows that knowledge workers perform daily.
This represents a philosophical shift from the current generation of AI assistants that excel at conversation but struggle with execution. While competitors focus on making their models sound more human,
Moonshot has prioritized making them more useful. The distinction matters because enterprises don’t need AI that can pass the Turing test—they need AI that can pass the productivity test.
The real breakthrough isn’t in any single capability, but in the seamless orchestration of multiple tools and services. Previous attempts at “agent” AI required extensive prompt engineering, careful workflow design, and constant human oversight.
Kimi K2 appears to handle the cognitive overhead of task decomposition, tool selection, and error recovery autonomously—the difference between a sophisticated calculator and a genuine thinking assistant.
The great convergence: When open source models finally caught the leaders
Kimi K2’s release marks an inflection point that industry observers have predicted but rarely witnessed: the moment when open-source AI capabilities genuinely converge with proprietary alternatives.
Unlike previous “GPT killers” that excelled in narrow domains while failing on practical applications, Kimi K2 demonstrates broad competence across the full spectrum of tasks that define general intelligence. It writes code, solves mathematics, uses tools, and completes complex workflows—all while being freely available for modification and self-deployment.
This convergence arrives at a particularly vulnerable moment for the AI incumbents. OpenAI faces mounting pressure to justify its
$300 billion valuation while Anthropic struggles to differentiate Claude in an increasingly crowded market. Both companies have built business models predicated on maintaining technological advantages that Kimi K2 suggests may be ephemeral.
The timing isn’t coincidental. As transformer architectures mature and training techniques democratize, the competitive advantages increasingly shift from raw capability to deployment efficiency, cost optimization, and ecosystem effects.
Moonshot seems to understand this transition intuitively, positioning Kimi K2 not as a better chatbot, but as a more practical foundation for the next generation of AI applications.
The question now isn’t whether open-source models can match proprietary ones—Kimi K2 proves they already have. The question is whether the incumbents can adapt their business models fast enough to compete in a world where their core technology advantages are no longer defensible. Based on Friday’s release, that adaptation period just got considerably shorter.

 The quick idea
The quick idea
 But does this lean model architecture juggle both efficiency and adaptability well? Curious on the real-world versatility beyond benchmarks!
But does this lean model architecture juggle both efficiency and adaptability well? Curious on the real-world versatility beyond benchmarks! Hello, Kimi K2! Open-Source Agentic Model!
Hello, Kimi K2! Open-Source Agentic Model! 1T total / 32B active MoE model
1T total / 32B active MoE model Multimodal & thought-mode not supported for now
Multimodal & thought-mode not supported for now API is here:
API is here:  Tech blog:
Tech blog: 




 Flood /search?q=#MeiGenMultiTalk
Flood /search?q=#MeiGenMultiTalk  Check out these mind-blowing examples :
Check out these mind-blowing examples : 


 so good
so good
 , singing
, singing  , interaction control
, interaction control  , and cartoon creation
, and cartoon creation  .
.

 MeiGen-MultiTalk: the code and checkpoints are released. Enjoy!
MeiGen-MultiTalk: the code and checkpoints are released. Enjoy!














 )
)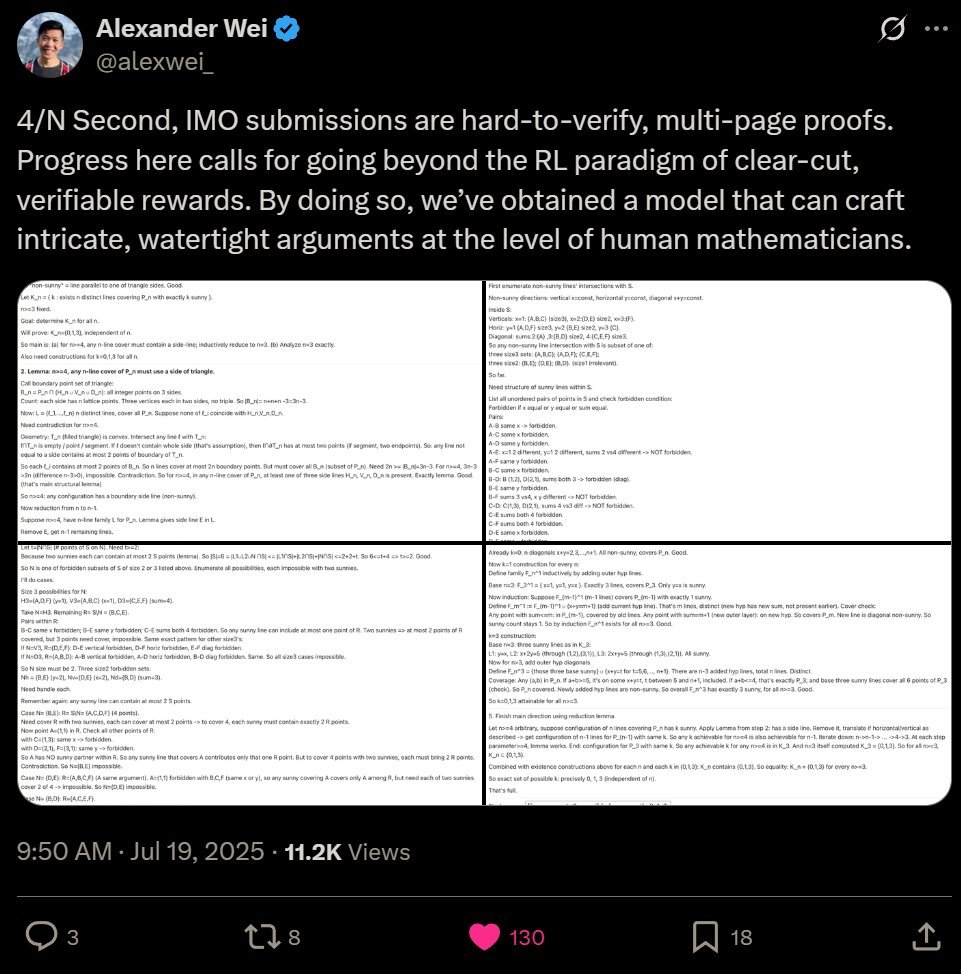















 AI outsmarted 30 of the world's top mathematicians at secret meeting in California
AI outsmarted 30 of the world's top mathematicians at secret meeting in California Cutting-edge AI models from OpenAI and DeepSeek undergo 'complete collapse' when problems get too difficult, study reveals
Cutting-edge AI models from OpenAI and DeepSeek undergo 'complete collapse' when problems get too difficult, study reveals Scientists just developed a new AI modeled on the human brain — it's outperforming LLMs like ChatGPT at reasoning tasks
Scientists just developed a new AI modeled on the human brain — it's outperforming LLMs like ChatGPT at reasoning tasks

 Write and Run AI Agents with Markdown. Run automated AI agents with ease.
Write and Run AI Agents with Markdown. Run automated AI agents with ease.












