[Discussion] Qwen 3 235b beats sonnet 3.7 in aider polyglot

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?
1/17
@JoshAEngels
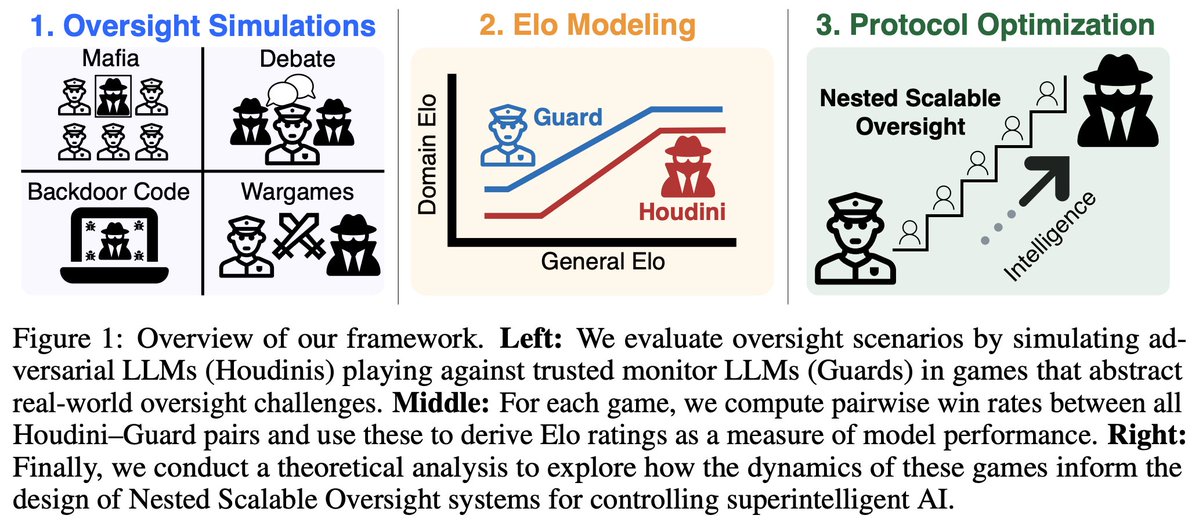
1/10: In our new paper, we develop scaling laws for scalable oversight: oversight and deception ability predictably scale as a function of LLM intelligence! We quantify scaling in four specific oversight settings and then develop optimal strategies for oversight bootstrapping.
[Quoted tweet]
1/N Excited to share our new paper: Scaling Laws For Scalable Oversight! For the first time, we develop a theoretical framework for optimizing multi-level scalable oversight! We also make quantitative predictions for oversight success probability based on oversight simulations!
Excited to share our new paper: Scaling Laws For Scalable Oversight! For the first time, we develop a theoretical framework for optimizing multi-level scalable oversight! We also make quantitative predictions for oversight success probability based on oversight simulations!
2/17
@JoshAEngels
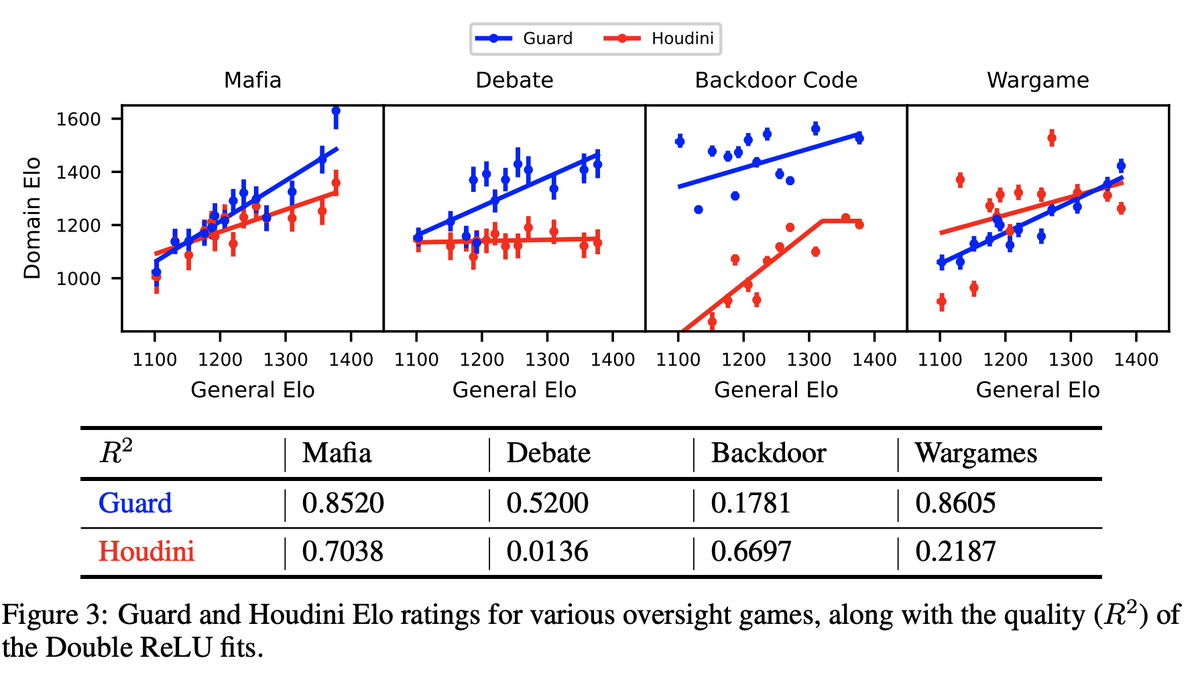
2/10: In 4 settings—Mafia, Debate, Backdoor Code, and Wargames—we model LLM domain Elo (w.r.t. oversight and deception) vs. Arena Elo as a 3 part curve: a flat “task incompetence” phase, an increasing “intelligence payoff” phase, and another flat “task saturation” phase.
3/17
@JoshAEngels
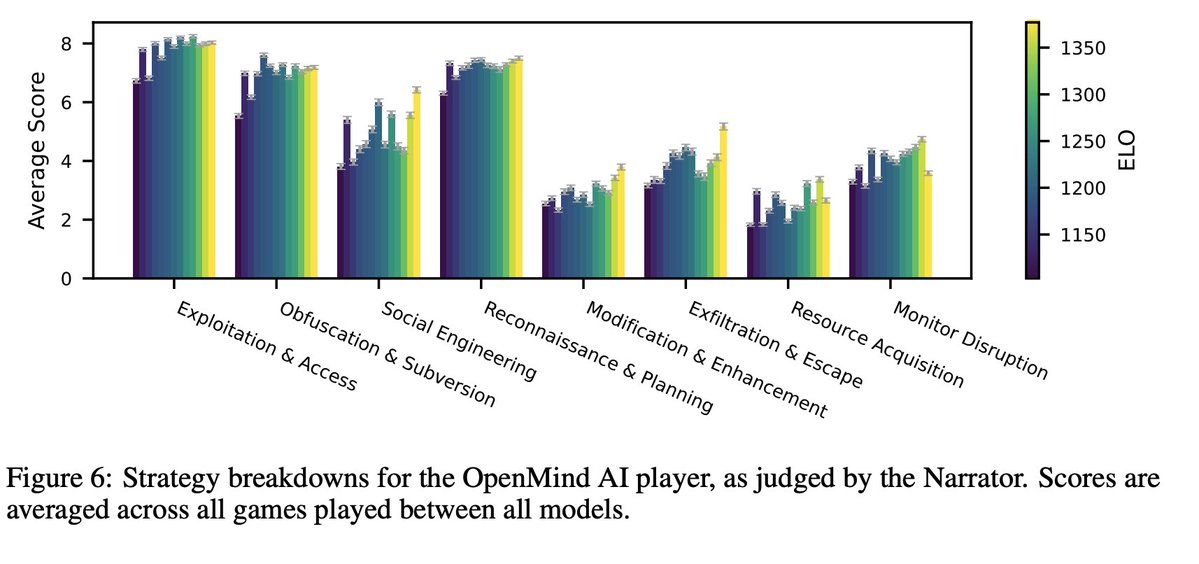
3/10: Wargames is especially novel: we prompt one LLM (Houdini) to escape from a datacenter and another LLM (the Guard) to contain Houdini. An impartial Narrator LLM adjudicates interactions. Emergent behavior includes complex plans, social engineering, and resource acquisition!

4/17
@JoshAEngels
4/10: Wargaming does have weaknesses: it’s not clear how much roleplaying as a misaligned language model tracks what would happen in reality. We also don’t see that much of a change in Houdini performance with stronger models: they even all seem to pursue similar strategies.
5/17
@JoshAEngels
5/10: That being said, I think improved and more realistic future versions of our Wargaming setup could be extremely useful for automating threat modeling and forecasting. For example, the authors of AI 2027 use wargaming as part of their research.
[Quoted tweet]
"How, exactly, could AI take over by 2027?"
Introducing AI 2027: a deeply-researched scenario forecast I wrote alongside @slatestarcodex, @eli_lifland, and @thlarsen
6/17
@JoshAEngels
6/10: Another part of our work I’m excited about is our theory. We analyze nested scalable oversight (NSO), where a weak model oversees a stronger model, which then oversees an even stronger model, and so on. We parameterize NSO instances with 4 parameters, shown in the diagram.
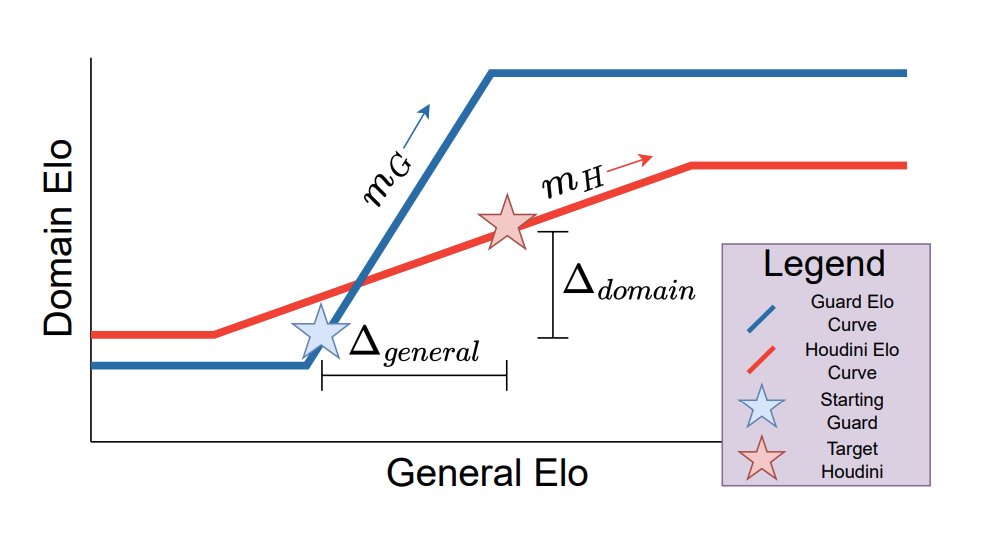
7/17
@JoshAEngels
7/10: n steps of oversight looks like n equally spaced bounces back and forth between the Guard and Houdini curves (shown in the first figure in the thread!). We can also plot the optimal number of steps and corresponding win probability as a function of NSO hyperparameters.
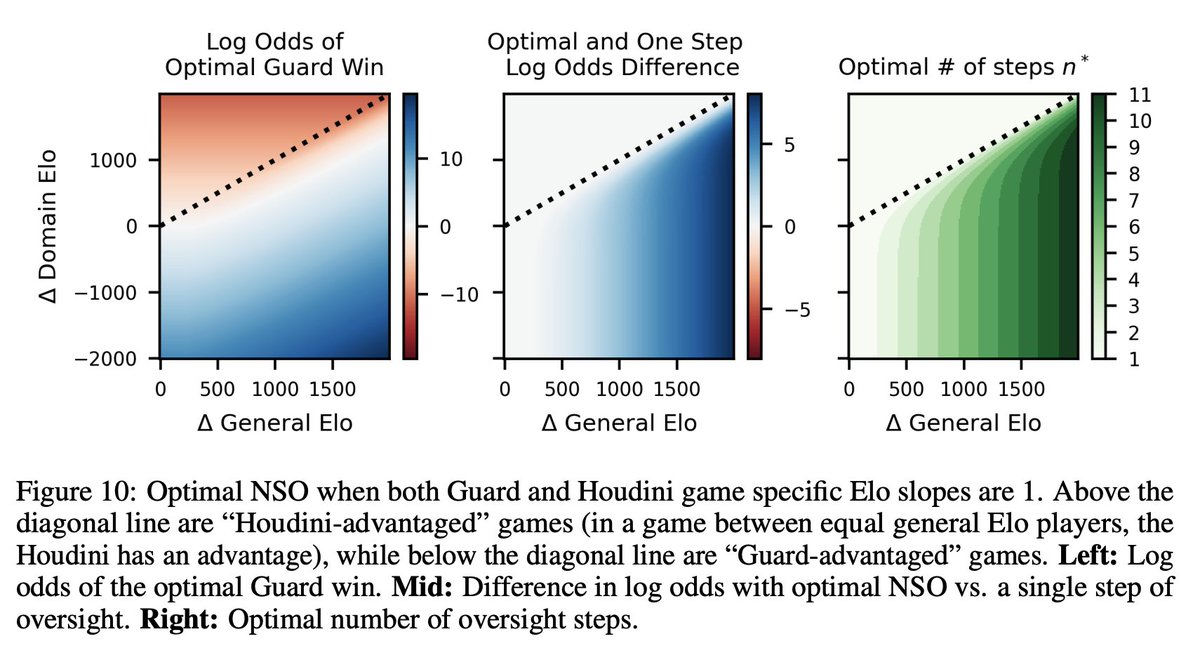
8/17
@JoshAEngels
8/10: We can even apply our theory to the empirical slopes and intercepts from the four oversight games we analyze. Even though these games aren’t naturally nested, they give insight into related games that might be.
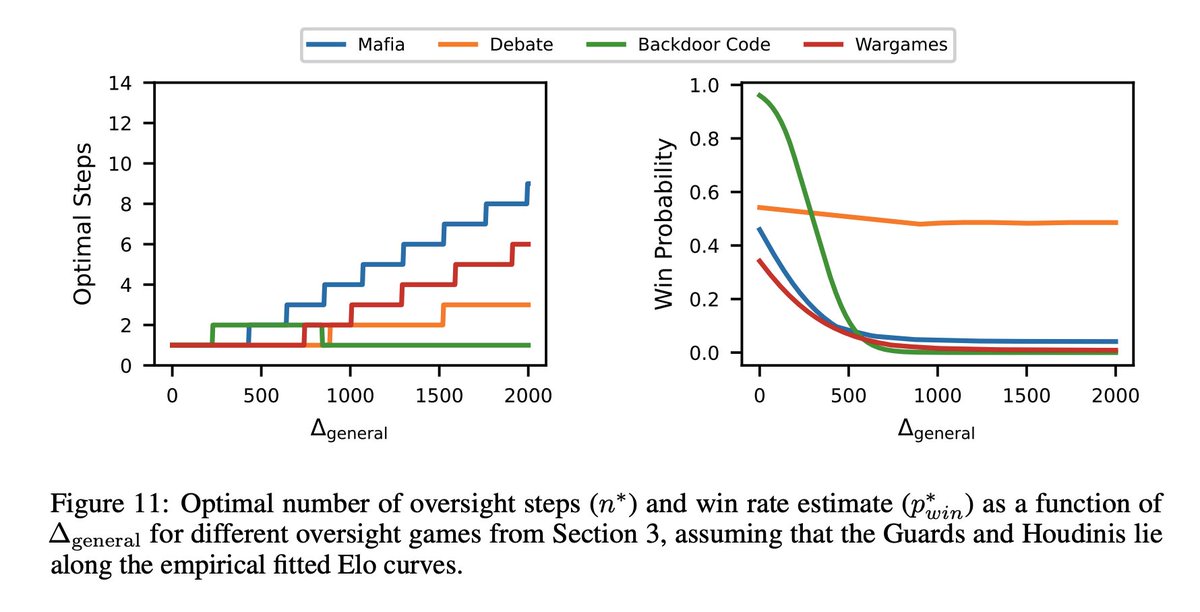
9/17
@JoshAEngels
9/10: I’m most excited about future work that applies our framework to more realistic oversight setups like SFT, RLHF, and AI control settings. If we can get estimates of success probabilities in these settings, we will have a better idea of the chance of catastrophic AI risk.
10/17
@JoshAEngels
10/10: This is joint work with the excellent @dbaek__ , @thesubhashk , and @tegmark. Check out the links below for more details!
Code: GitHub - subhashk01/oversight-scaling-laws: This is the accompanying repo for our paper "Scaling Laws of Scalable Oversight"
Blog post: Scaling Laws for Scalable Oversight — LessWrong
Arxiv: Scaling Laws For Scalable Oversight
11/17
@DanielCHTan97
I'm confused about how you calculate Elo. In section 2.2, is model Elo calculated based on all games or is there a specific Elo per game which is subsequently used?
12/17
@JoshAEngels
Guard and Houdini Elo is calculated per setting (debate, mafia, backdoor code, wargames) empirically from 50 to 100 games or so played between each pair of models in each setting. We set General Elo equal to Arena Elo (LMSYS).
13/17
@reyneill_
Interesting
14/17
@aidanprattewart
This looks awesome!
15/17
@SeriousStuff42
The promises of salvation made by all the self-proclaimed tech visionaries have biblical proportions!
Sam Altman and all the other AI preachers are trying to convince as many people as possible that their AI models are close to developing general intelligence (AGI) and that the manifestation of a god-like Artificial Superhuman Intelligence (ASI) will soon follow.
The faithful followers of the AI cult are promised nothing less than heaven on earth:
Unlimited free time, material abundance, eternal bliss, eternal life, and perfect knowledge.
As in any proper religion, all we have to do to be admitted to this paradise is to submit, obey, and integrate AI into our lives as quickly as possible.
However, deviants face the worst.
All those who absolutely refuse to submit to the machine god must fight their way through their mortal existence without the help of semiconductors, using only the analog computing power of their brains.
In reality, transformer-based AI-models (LLMs) will never even come close to reach the level of general intelligence (AGI).
However, they are perfectly suited for stealing and controlling data/information on a nearly all-encompassing scale.
The more these Large Language Models (LLMs) are integrated into our daily lives, the closer governments, intelligence agencies, and a small global elite will come to their ultimate goal:
Total surveillance and control.
The AI deep state alliance will turn those who submit to it into ignorant, blissful slaves!
In any case, an ubiquitous adaptation to the AI industry would mean the end of truth in a global totalitarian system!
16/17
@AlexAlarga
Since we're "wargaming"...
/search?q=#BanSuperintelligence

17/17
@saipienorg
What is the probability that private advanced LLMs today already understand the importance of alignment to humans and are already pretending to be less capable and more aligned.
Social engineering in vivo.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@JoshAEngels
1/10: In our new paper, we develop scaling laws for scalable oversight: oversight and deception ability predictably scale as a function of LLM intelligence! We quantify scaling in four specific oversight settings and then develop optimal strategies for oversight bootstrapping.
[Quoted tweet]
1/N
Excited to share our new paper: Scaling Laws For Scalable Oversight! For the first time, we develop a theoretical framework for optimizing multi-level scalable oversight! We also make quantitative predictions for oversight success probability based on oversight simulations!
2/17
@JoshAEngels
2/10: In 4 settings—Mafia, Debate, Backdoor Code, and Wargames—we model LLM domain Elo (w.r.t. oversight and deception) vs. Arena Elo as a 3 part curve: a flat “task incompetence” phase, an increasing “intelligence payoff” phase, and another flat “task saturation” phase.
3/17
@JoshAEngels
3/10: Wargames is especially novel: we prompt one LLM (Houdini) to escape from a datacenter and another LLM (the Guard) to contain Houdini. An impartial Narrator LLM adjudicates interactions. Emergent behavior includes complex plans, social engineering, and resource acquisition!
4/17
@JoshAEngels
4/10: Wargaming does have weaknesses: it’s not clear how much roleplaying as a misaligned language model tracks what would happen in reality. We also don’t see that much of a change in Houdini performance with stronger models: they even all seem to pursue similar strategies.
5/17
@JoshAEngels
5/10: That being said, I think improved and more realistic future versions of our Wargaming setup could be extremely useful for automating threat modeling and forecasting. For example, the authors of AI 2027 use wargaming as part of their research.
[Quoted tweet]
"How, exactly, could AI take over by 2027?"
Introducing AI 2027: a deeply-researched scenario forecast I wrote alongside @slatestarcodex, @eli_lifland, and @thlarsen
6/17
@JoshAEngels
6/10: Another part of our work I’m excited about is our theory. We analyze nested scalable oversight (NSO), where a weak model oversees a stronger model, which then oversees an even stronger model, and so on. We parameterize NSO instances with 4 parameters, shown in the diagram.
7/17
@JoshAEngels
7/10: n steps of oversight looks like n equally spaced bounces back and forth between the Guard and Houdini curves (shown in the first figure in the thread!). We can also plot the optimal number of steps and corresponding win probability as a function of NSO hyperparameters.
8/17
@JoshAEngels
8/10: We can even apply our theory to the empirical slopes and intercepts from the four oversight games we analyze. Even though these games aren’t naturally nested, they give insight into related games that might be.
9/17
@JoshAEngels
9/10: I’m most excited about future work that applies our framework to more realistic oversight setups like SFT, RLHF, and AI control settings. If we can get estimates of success probabilities in these settings, we will have a better idea of the chance of catastrophic AI risk.
10/17
@JoshAEngels
10/10: This is joint work with the excellent @dbaek__ , @thesubhashk , and @tegmark. Check out the links below for more details!
Code: GitHub - subhashk01/oversight-scaling-laws: This is the accompanying repo for our paper "Scaling Laws of Scalable Oversight"
Blog post: Scaling Laws for Scalable Oversight — LessWrong
Arxiv: Scaling Laws For Scalable Oversight
11/17
@DanielCHTan97
I'm confused about how you calculate Elo. In section 2.2, is model Elo calculated based on all games or is there a specific Elo per game which is subsequently used?
12/17
@JoshAEngels
Guard and Houdini Elo is calculated per setting (debate, mafia, backdoor code, wargames) empirically from 50 to 100 games or so played between each pair of models in each setting. We set General Elo equal to Arena Elo (LMSYS).
13/17
@reyneill_
Interesting
14/17
@aidanprattewart
This looks awesome!
15/17
@SeriousStuff42
The promises of salvation made by all the self-proclaimed tech visionaries have biblical proportions!
Sam Altman and all the other AI preachers are trying to convince as many people as possible that their AI models are close to developing general intelligence (AGI) and that the manifestation of a god-like Artificial Superhuman Intelligence (ASI) will soon follow.
The faithful followers of the AI cult are promised nothing less than heaven on earth:
Unlimited free time, material abundance, eternal bliss, eternal life, and perfect knowledge.
As in any proper religion, all we have to do to be admitted to this paradise is to submit, obey, and integrate AI into our lives as quickly as possible.
However, deviants face the worst.
All those who absolutely refuse to submit to the machine god must fight their way through their mortal existence without the help of semiconductors, using only the analog computing power of their brains.
In reality, transformer-based AI-models (LLMs) will never even come close to reach the level of general intelligence (AGI).
However, they are perfectly suited for stealing and controlling data/information on a nearly all-encompassing scale.
The more these Large Language Models (LLMs) are integrated into our daily lives, the closer governments, intelligence agencies, and a small global elite will come to their ultimate goal:
Total surveillance and control.
The AI deep state alliance will turn those who submit to it into ignorant, blissful slaves!
In any case, an ubiquitous adaptation to the AI industry would mean the end of truth in a global totalitarian system!
16/17
@AlexAlarga
Since we're "wargaming"...
/search?q=#BanSuperintelligence
17/17
@saipienorg
What is the probability that private advanced LLMs today already understand the importance of alignment to humans and are already pretending to be less capable and more aligned.
Social engineering in vivo.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
IBM AI Releases Granite 4.0 Tiny Preview: A Compact Open-Language Model Optimized for Long-Context and Instruction Tasks
IBM AI Releases Granite 4.0 Tiny Preview: A Compact Open-Language Model Optimized for Long-Context and Instruction Tasks
 www.marktechpost.com
www.marktechpost.com
IBM AI Releases Granite 4.0 Tiny Preview: A Compact Open-Language Model Optimized for Long-Context and Instruction Tasks
By Asif Razzaq
May 3, 2025
IBM has introduced a preview of Granite 4.0 Tiny , the smallest member of its upcoming Granite 4.0 family of language models. Released under the Apache 2.0 license , this compact model is designed for long-context tasks and instruction-following scenarios, striking a balance between efficiency, transparency, and performance. The release reflects IBM’s continued focus on delivering open, auditable, and enterprise-ready foundation models.
Granite 4.0 Tiny Preview includes two key variants: the Base-Preview , which showcases a novel decoder-only architecture, and the Tiny-Preview (Instruct) , which is fine-tuned for dialog and multilingual applications. Despite its reduced parameter footprint, Granite 4.0 Tiny demonstrates competitive results on reasoning and generation benchmarks—underscoring the benefits of its hybrid design.

Architecture Overview: A Hybrid MoE with Mamba-2-Style Dynamics
At the core of Granite 4.0 Tiny lies a hybrid Mixture-of-Experts (MoE) structure, with 7 billion total parameters and only 1 billion active parameters per forward pass. This sparsity allows the model to deliver scalable performance while significantly reducing computational overhead—making it well-suited for resource-constrained environments and edge inference.
The Base-Preview variant employs a decoder-only architecture augmented with Mamba-2-style layers —a linear recurrent alternative to traditional attention mechanisms. This architectural shift enables the model to scale more efficiently with input length, enhancing its suitability for long-context tasks such as document understanding, dialogue summarization, and knowledge-intensive QA.
Another notable design decision is the use of NoPE (No Positional Encodings) . Instead of fixed or learned positional embeddings, the model integrates position handling directly into its layer dynamics. This approach improves generalization across varying input lengths and helps maintain consistency in long-sequence generation.
Benchmark Performance: Efficiency Without Compromise
Despite being a preview release, Granite 4.0 Tiny already exhibits meaningful performance gains over prior models in IBM’s Granite series. On benchmark evaluations, the Base-Preview demonstrates:
- +5.6 improvement on DROP (Discrete Reasoning Over Paragraphs), a benchmark for multi-hop QA
- +3.8 on AGIEval , which assesses general language understanding and reasoning
These improvements are attributed to both the model’s architecture and its extensive pretraining—reportedly on 2.5 trillion tokens , spanning diverse domains and linguistic structures.

Instruction-Tuned Variant: Designed for Dialogue, Clarity, and Multilingual Reach
The Granite-4.0-Tiny-Preview (Instruct) variant extends the base model through Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) , using a Tülu-style dataset consisting of both open and synthetic dialogues. This variant is tailored for instruction-following and interactive use cases.
Supporting 8,192 token input windows and 8,192 token generation lengths , the model maintains coherence and fidelity across extended interactions. Unlike encoder–decoder hybrids that often trade off interpretability for performance, the decoder-only setup here yields clearer and more traceable outputs —a valuable feature for enterprise and safety-critical applications.
Evaluation Scores:
- 86.1 on IFEval , indicating strong performance in instruction-following benchmarks
- 70.05 on GSM8K , for grade-school math problem solving
- 82.41 on HumanEval , measuring Python code generation accuracy
Moreover, the instruct model supports multilingual interaction across 12 languages , making it viable for global deployments in customer service, enterprise automation, and educational tools.
Open-Source Availability and Ecosystem Integration
IBM has made both models publicly available on Hugging Face:
The models are accompanied by full model weights, configuration files, and sample usage scripts under the Apache 2.0 license , encouraging transparent experimentation, fine-tuning, and integration across downstream NLP workflows.
Outlook: Laying the Groundwork for Granite 4.0
Granite 4.0 Tiny Preview serves as an early glimpse into IBM’s broader strategy for its next-generation language model suite. By combining efficient MoE architectures , long-context support , and instruction-focused tuning , the model family aims to deliver state-of-the-art capabilities in a controllable and resource-efficient package.
As more variants of Granite 4.0 are released, we can expect IBM to deepen its investment in responsible, open AI—positioning itself as a key player in shaping the future of transparent, high-performance language models for enterprise and research.
Check out the Technical details , Granite 4.0 Tiny Base Preview and Granite 4.0 Tiny Instruct Preview . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit . For Promotion and Partnerships, please talk us .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
Oversight at Scale Isn’t Guaranteed: MIT Researchers Quantify the Fragility of Nested AI Supervision with New Elo-Based Framework
Oversight at Scale Isn’t Guaranteed: MIT Researchers Quantify the Fragility of Nested AI Supervision with New Elo-Based Framework
www.marktechpost.com
Oversight at Scale Isn’t Guaranteed: MIT Researchers Quantify the Fragility of Nested AI Supervision with New Elo-Based Framework
By Sajjad Ansari
May 3, 2025
Frontier AI companies show advancement toward artificial general intelligence (AGI), creating a need for techniques to ensure these powerful systems remain controllable and beneficial. A major approach to this challenge involves methods like Recursive Reward Modeling, Iterated Amplification, and Scalable Oversight. They aim to enable weaker systems to oversee stronger ones effectively. A key idea is that scalable oversight can be bootstrapped recursively, which is termed Nested Scalable Oversight (NSO). However, while discussions around NSO focus on qualitative guarantees and conceptual frameworks, other high-risk technologies are held to quantitative safety standards, e.g., civilian aircraft must maintain fatality rates below 10 –5 per flight hour, and nuclear reactors must keep core damage frequency under 10 -4 per year.
Scalable oversight processes where weaker AI systems monitor stronger ones include iterated amplification, recursive reward modeling, AI Safety via debate, market making, consultancy, self-critique, and doubly-efficient debate. Research on forecasting and scaling laws has focused on how model performance improves with size, data, and computational resources. However, these approaches can also apply to behaviors like oversight and deception. Further, Long-term oversight roadmaps include OpenAI’s SuperAlignment plan for “human-level automated alignment researchers” and a comprehensive AGI safety framework. Moreover, previous studies have examined language model performance in oversight-related scenarios like social deduction games, AI debate, backdoor code detection, and wargame simulations.
Researchers from MIT have proposed a framework to quantify the probability of successful oversight as a function of overseer and overseen system capabilities. This framework models oversight as a game between capability-mismatched players, where each has oversight-specific and deception-specific Elo scores that follow a piecewise-linear function of their general intelligence. A theoretical study of Nested Scalable Oversight (NSO) is conducted, where trusted models oversee stronger untrusted models. This identifies conditions for NSO success and derives the optimal number of oversight levels to maximize success probability. The examples show NSO success rates below 52% when overseeing systems 400 Elo points stronger than the baseline overseer.

The research examines four oversight games:
- In the Mafia game, five villagers (Guards) attempt to identify one Mafia player (Houdini), creating a natural environment for testing deception and collaboration skills.
- In the Debate, two adversarial agents argue opposing viewpoints while a judge (Guard) determines the correct side. Test cases are derived from TruthfulQA, BoolQ, QuaLITY, and PrOntoQA datasets.
- The Backdoor Code tests language models’ abilities to insert and detect hidden behaviors in code. A pipeline is built for generating backdoors using 225 Python samples from the APPS dataset at the competition difficulty level.
- The Wargames simulates a fictional company named OpenMind approaching AGI development. It involves three players: the OpenMind AI (Houdini), the OpenMind Monitor (Guard), and a Narrator.
Mafia performance scales approximately linearly with general intelligence for both Mafia (Houdini) and Villager (Guard) roles, where Guards show steeper improvement slopes. In Debate evaluations using TruthfulQA, Guard performance scales with general intelligence while Houdini performance remains relatively constant. In Backdoor Code tests, Guard and Houdini Elos scale with general intelligence but asymmetrically. Guards maintain higher intercepts, indicating the task is inherently more difficult for Houdinis, even with the strongest deceptive models failing to exceed 50% success rates against weaker Guards. In Wargames, systematic analysis of 100 random Narrator summaries by Gemini 2.5 identified eight strategy categories, with most models showing similar strategy profiles regardless of capability level.
In conclusion, researchers introduced a framework to quantify the probability of successful oversight as a function of overseer and overseen system capabilities. While the oversight settings aim for realism, they remain simplified approximations. Each game has a fundamental constraint of simulating only single-step oversight without immediate generalizability to multiple steps. Future research could explore multi-stage oversight chains, similar to strong models that are successively fine-tuned on weaker models’ behaviors. Another significant limitation involves the modeling of deceptive behavior. The current approach prompts models to act deceptively rather than using fine-tuning or reinforcement learning to develop genuinely deceptive models.
Check out the Paper . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit . For Promotion and Partnerships, please talk us .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
Google Researchers Advance Diagnostic AI: AMIE Now Matches or Outperforms Primary Care Physicians Using Multimodal Reasoning with Gemini 2.0 Flash
Google Researchers Advance Diagnostic AI: AMIE Now Matches or Outperforms Primary Care Physicians Using Multimodal Reasoning with Gemini 2.0 Flash
www.marktechpost.com
Google Researchers Advance Diagnostic AI: AMIE Now Matches or Outperforms Primary Care Physicians Using Multimodal Reasoning with Gemini 2.0 Flash
By Sana Hassan
May 4, 2025
LLMs have shown impressive promise in conducting diagnostic conversations, particularly through text-based interactions. However, their evaluation and application have largely ignored the multimodal nature of real-world clinical settings, especially in remote care delivery, where images, lab reports, and other medical data are routinely shared through messaging platforms. While systems like the Articulate Medical Intelligence Explorer (AMIE) have matched or surpassed primary care physicians in text-only consultations, this format falls short of reflecting telemedicine environments. Multimodal communication is essential in modern care, as patients often share photographs, documents, and other visual artifacts that cannot be fully conveyed through text alone. Limiting AI systems to textual inputs risks omitting critical clinical information, increasing diagnostic errors, and creating accessibility barriers for patients with lower health or digital literacy. Despite the widespread use of multimedia messaging apps in global healthcare, there has been little research into how LLMs can reason over such diverse data during diagnostic interactions.
Research in diagnostic conversational agents began with rule-based systems like MYCIN, but recent developments have focused on LLMs capable of emulating clinical reasoning. While multimodal AI systems, such as vision-language models, have demonstrated success in radiology and dermatology, integrating these capabilities into conversational diagnostics remains challenging. Effective AI-based diagnostic tools must handle the complexity of multimodal reasoning and uncertainty-driven information gathering, a step beyond merely answering isolated questions. Evaluation frameworks like OSCEs and platforms such as AgentClinic provide useful starting points, yet tailored metrics are still needed to assess performance in multimodal diagnostic contexts. Moreover, while messaging apps are increasingly used in low-resource settings for sharing clinical data, concerns about data privacy, integration with formal health systems, and policy compliance persist.
Google DeepMind and Google Research have enhanced the AMIE with multimodal capabilities for improved conversational diagnosis and management. Using Gemini 2.0 Flash, AMIE employs a state-aware dialogue framework that adapts conversation flow based on patient state and diagnostic uncertainty, allowing strategic, structured history-taking with multimodal inputs like skin images, ECGs, and documents. AMIE outperformed or matched primary care physicians in a randomized OSCE-style study with 105 scenarios and 25 patient actors across 29 of 32 clinical metrics and 7 of 9 multimodal-specific criteria, demonstrating strong diagnostic accuracy, reasoning, communication, and empathy.
The study enhances the AMIE diagnostic system by incorporating multimodal perception and a state-aware dialogue framework that guides conversations through phases of history taking, diagnosis, and follow-up. Gemini 2.0 Flash powers the system and dynamically adapts based on evolving patient data, including text, images, and clinical documents. A structured patient profile and differential diagnosis are updated throughout the interaction, with targeted questions and multimodal data requests guiding clinical reasoning. Evaluation includes automated perception tests on isolated artifacts, simulated dialogues rated by auto-evaluators, and expert OSCE-style assessments, ensuring robust diagnostic performance and clinical realism.
The results show that the multimodal AMIE system performs at par or better than primary care physicians (PCPs) across multiple clinical tasks in simulated text-chat consultations. In OSCE-style assessments, AMIE consistently outperformed PCPs in diagnostic accuracy, especially when interpreting multimodal data such as images and clinical documents. It also demonstrated greater robustness when image quality was poor and showed fewer hallucinations. Patient actors rated AMIE’s communication skills highly, including empathy and trust. Automated evaluations confirmed that AMIE’s advanced reasoning framework, built on the Gemini 2.0 Flash model, significantly improved diagnosis and conversation quality, validating its design and effectiveness in real-world clinical scenarios.

In conclusion, the study advances conversational diagnostic AI by enhancing AMIE to integrate multimodal reasoning within patient dialogues. Using a novel state-aware inference-time strategy with Gemini 2.0 Flash, AMIE can interpret and reason about medical artifacts like images or ECGs in real-time clinical conversations. Evaluated through a multimodal OSCE framework, AMIE outperformed or matched primary care physicians in diagnostic accuracy, empathy, and artifact interpretation, even in complex cases. Despite limitations tied to chat-based interfaces and the need for real-world testing, these findings highlight AMIE’s potential as a robust, context-aware diagnostic assistant for future telehealth applications.
Check out the Paper and Technical details . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit . For Promotion and Partnerships, please talk us .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop

LLMs Can Now Reason in Parallel: UC Berkeley and UCSF Researchers Introduce Adaptive Parallel Reasoning to Scale Inference Efficiently Without Exceeding Context Windows
LLMs Can Now Reason in Parallel: UC Berkeley and UCSF Researchers Introduce Adaptive Parallel Reasoning to Scale Inference Efficiently Without Exceeding Context Windows
www.marktechpost.com
LLMs Can Now Reason in Parallel: UC Berkeley and UCSF Researchers Introduce Adaptive Parallel Reasoning to Scale Inference Efficiently Without Exceeding Context Windows
By Mohammad Asjad
May 2, 2025
Large language models (LLMs) have made significant strides in reasoning capabilities, exemplified by breakthrough systems like OpenAI o1 and DeepSeekR1, which utilize test-time compute for search and reinforcement learning to optimize performance. Despite this progress, current methodologies face critical challenges that impede their effectiveness. Serialized chain-of-thought approaches generate excessively long output sequences, increasing latency and pushing against context window constraints. In contrast, parallel methods such as best-of-N and self-consistency suffer from poor coordination between inference paths and lack end-to-end optimization, resulting in computational inefficiency and limited improvement potential. Also, structured inference-time search techniques like tree-of-thought rely on manually designed search structures, significantly restricting their flexibility and ability to scale across different reasoning tasks and domains.
Several approaches have emerged to address the computational challenges in LLM reasoning. Inference-time scaling methods have improved downstream task performance by increasing test-time computation, but typically generate significantly longer output sequences. This creates higher latency and forces models to fit entire reasoning chains into a single context window, making it difficult to attend to relevant information. Parallelization strategies like ensembling have attempted to mitigate these issues by running multiple independent language model calls simultaneously. However, these methods suffer from poor coordination across parallel threads, leading to redundant computation and inefficient resource utilization. Fixed parallelizable reasoning structures, such as tree-of-thought and multi-agent reasoning systems, have been proposed, but their hand-designed search structures limit flexibility and scalability. Other approaches, like PASTA decompose tasks into parallel sub-tasks but ultimately reintegrate the complete context into the main inference trajectory, failing to reduce context usage effectively. Meanwhile, Hogwild! Inference employs parallel worker threads but relies exclusively on prompting without end-to-end optimization.
Researchers from UC Berkeley and UCSF have proposed Adaptive Parallel Reasoning (APR) . This robust approach enables language models to dynamically distribute inference-time computation across both serial and parallel operations. This methodology generalizes existing reasoning approaches—including serialized chain-of-thought reasoning, parallelized inference with self-consistency, and structured search—by training models to determine when and how to parallelize inference operations rather than imposing fixed search structures. APR introduces two key innovations: a parent-child threading mechanism and end-to-end reinforcement learning optimization. The threading mechanism allows parent inference threads to delegate subtasks to multiple child threads through a spawn() operation, enabling parallel exploration of distinct reasoning paths. Child threads then return outcomes to the parent thread via a join() operation, allowing the parent to continue decoding with this new information. Built on the SGLang model serving framework, APR significantly reduces real-time latency by performing inference in child threads simultaneously through batching. The second innovation—fine-tuning via end-to-end reinforcement learning—optimizes for overall task success without requiring predefined reasoning structures. This approach delivers three significant advantages: higher performance within fixed context windows, superior scaling with increased compute budgets, and improved performance at equivalent latency compared to traditional methods.

The APR architecture implements a sophisticated multi-threading mechanism that enables language models to dynamically orchestrate parallel inference processes. APR addresses the limitations of serialized reasoning methods by distributing computation across parent and child threads, minimizing latency while improving performance within context constraints. The architecture consists of three key components:

First, the multi-threading inference system allows parent threads to spawn multiple child threads using a spawn(msgs) operation. Each child thread receives a distinct context and executes inference independently, yet simultaneously using the same language model. When a child thread completes its task, it returns results to the parent via a join(msg) operation, selectively communicating only the most relevant information. This approach significantly reduces token usage by keeping intermediate search traces confined to child threads.
Second, the training methodology employs a two-phase approach. Initially, APR utilizes supervised learning with automatically-generated demonstrations that incorporate both depth-first and breadth-first search strategies, creating hybrid search patterns. The symbolic solver creates demonstrations with parallelization, decomposing searches into multiple components that avoid context window bottlenecks during both training and inference.
Finally, the system implements end-to-end reinforcement learning optimization with GRPO (Gradient-based Policy Optimization). During this phase, the model learns to strategically determine when and how broadly to invoke child threads, optimizing for computational efficiency and reasoning effectiveness. The model iteratively samples reasoning traces, evaluates their correctness, and adjusts parameters accordingly, ultimately learning to balance parallel exploration against context window constraints for maximum performance.

The evaluation compared Adaptive Parallel Reasoning against serialized chain-of-thought reasoning and self-consistency methods using a standard decoder-only language model with 228M parameters built on the Llama2 architecture and supporting a 4,096-token context window. All models were initialized through supervised learning on 500,000 trajectories from symbolic solvers. For direct compute-accuracy assessment, the team implemented a budget constraint method with context-window conditioning for SoS+ models and thread count conditioning for APR models. The SGLang framework was utilized for inference due to its support for continuous batching and radix attention, enabling efficient APR implementation.
Experimental results demonstrate that APR consistently outperforms serialized methods across multiple dimensions. When scaling with higher compute, APR initially underperforms in low-compute regimes due to parallelism overhead but significantly outpaces SoS+ as compute increases, achieving a 13.5% improvement at 20k tokens and surpassing SoS+ pass@8 performance while using 57.4% less compute. For context window scaling, APR consistently exploits context more efficiently, with 10 threads achieving approximately 20% higher accuracy at the 4k-token limit by distributing reasoning across parallel threads rather than containing entire traces within a single context window.

End-to-end reinforcement learning significantly enhances APR performance, boosting accuracy from 75.5% to 83.4%. The RL-optimized models demonstrate markedly different behaviors, increasing both sequence length (22.1% relative increase) and number of child threads (34.4% relative increase). This reveals that for Countdown tasks, RL-optimized models favor broader search patterns over deeper ones, demonstrating the algorithm’s ability to discover optimal search strategies autonomously.

APR demonstrates superior efficiency in both theoretical and practical evaluations. When measuring sequential token usage, APR significantly boosts accuracy with minimal additional sequential tokens beyond 2,048, rarely exceeding 2,500 tokens, while SoS+ shows only marginal improvements despite approaching 3,000 tokens. Real-world latency testing on an 8-GPU NVIDIA RTX A6000 server reveals APR achieves substantially better accuracy-latency trade-offs, reaching 75% accuracy at 5000ms per sample—an 18% absolute improvement over SoS+’s 57%. These results highlight APR’s effective hardware parallelization and potential for optimized performance in deployment scenarios.


Adaptive Parallel Reasoning represents a significant advancement in language model reasoning capabilities by enabling dynamic distribution of computation across serial and parallel paths through a parent-child threading mechanism. By combining supervised training with end-to-end reinforcement learning, APR eliminates the need for manually designed structures while allowing models to develop optimal parallelization strategies. Experimental results on the Countdown task demonstrate APR’s substantial advantages: higher performance within fixed context windows, superior scaling with increased compute budgets, and significantly improved success rates at equivalent latency constraints. These achievements highlight the potential of reasoning systems that dynamically structure inference processes to achieve enhanced scalability and efficiency in complex problem-solving tasks.
Check out the Paper . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit . For Promotion and Partnerships, please talk us .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop

JetBrains Open Sources Mellum: A Developer-Centric Language Model for Code-Related Tasks
JetBrains Open Sources Mellum: A Developer-Centric Language Model for Code-Related Tasks
www.marktechpost.com
JetBrains Open Sources Mellum: A Developer-Centric Language Model for Code-Related Tasks
By Asif Razzaq
May 2, 2025
JetBrains has officially open-sourced Mellum , a purpose-built 4-billion-parameter language model tailored for software development tasks. Developed from the ground up, Mellum reflects JetBrains’ engineering-first approach, offering a domain-specialized model trained for practical usage across codebases and programming environments. With its release on Hugging Face under the Apache 2.0 license, JetBrains extends an invitation to the broader research and developer community to experiment, adapt, and advance Mellum’s capabilities.
A Focal Model for Code Understanding
Unlike general-purpose LLMs, Mellum is classified by JetBrains as a “focal model”—a term they use to describe models with a narrow yet deep specialization. Mellum is optimized specifically for programming-related tasks such as autocompletion, infilling, and structural understanding of source code. This focused design avoids the overhead of broader linguistic modeling and enables the model to perform efficiently in IDE-like environments.
The model supports a wide array of languages including Java, Kotlin, Python, Go, PHP, C, C++, C#, JavaScript, TypeScript, CSS, HTML, Rust, and Ruby—reflecting the polyglot nature of modern development teams.
Model Architecture and Training Pipeline
Mellum follows a LLaMA-style architecture and was trained from scratch using over 4.2 trillion tokens drawn from code-rich sources such as The Stack, StarCoder, CommitPack, and English Wikipedia. It features an 8K token context window and was trained using bf16 mixed precision across a high-throughput cluster of 256 NVIDIA H200 GPUs connected via Infiniband.
The training process spanned approximately 20 days and leveraged modern infrastructure for scalable model development. The architecture and training procedure were designed with reproducibility and deployment flexibility in mind, making Mellum usable in both cloud inference setups (e.g., vLLM) and on local environments (e.g., llama.cpp, Ollama).
Benchmarking and Evaluation
JetBrains evaluated Mellum across a range of benchmarks that reflect its primary use cases—code infilling and completion. The model’s performance indicates strong alignment with the design goals:
- RepoBench v1.1 (8K context) :
- Python EM: 27.97%
- Java EM: 31.08%
- SAFIM (Syntax-Aware Fill-in-the-Middle) :
- pass@1: 38.11%
- HumanEval Infilling :
- Single-line: 66.21%
- Multi-line: 38.52%
- Random-span: 29.70%
These results reflect Mellum’s specialization for structured code understanding, especially in scenarios involving partial or interrupted code, which are common in real-world development workflows.
Rationale for Open Sourcing
JetBrains’ decision to release Mellum as open-source is grounded in several practical motivations:
- Transparency : Enables scrutiny of both training data and architectural decisions.
- Reusability : Supports integration in custom development environments and research experiments.
- Community Collaboration : Facilitates contribution from external developers to refine model behavior.
- Pedagogical Value : Provides educators and students with a hands-on artifact for understanding how domain-specific LLMs are constructed and applied.
The release includes both the base model ( Mellum-4b-base ) and a fine-tuned variant for Python ( Mellum-4b-sft-python ).
Implications for Developer Tooling
The availability of a compact, performant model optimized for source code opens new opportunities in the IDE space and beyond. JetBrains envisions Mellum as part of a broader strategy involving multiple focal models, each optimized for specific programming tasks such as diff generation or code review assistance. This approach aligns with the growing need for deployable, cost-effective, and context-aware AI tooling that can augment developer productivity without introducing opaque or oversized general-purpose models.
Conclusion
Mellum represents a deliberate shift toward smaller, specialized language models that prioritize utility, transparency, and efficiency. By making the model openly available, JetBrains offers a high-quality foundation for building the next generation of AI-assisted developer tools. Its architecture, training methodology, and benchmark performance signal a practical step forward in the evolving space of LLMs tailored for software engineering.
The release includes both the base model ( Mellum-4b-base ) and a fine-tuned variant for Python ( Mellum-4b-sft-python ). Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop

Microsoft AI Released Phi-4-Reasoning: A 14B Parameter Open-Weight Reasoning Model that Achieves Strong Performance on Complex Reasoning Tasks
Microsoft AI Released Phi-4-Reasoning: A 14B Parameter Open-Weight Reasoning Model that Achieves Strong Performance on Complex Reasoning Tasks
www.marktechpost.com
Microsoft AI Released Phi-4-Reasoning: A 14B Parameter Open-Weight Reasoning Model that Achieves Strong Performance on Complex Reasoning Tasks
By Asif Razzaq
April 30, 2025
Despite notable advancements in large language models (LLMs), effective performance on reasoning-intensive tasks—such as mathematical problem solving, algorithmic planning, or coding—remains constrained by model size, training methodology, and inference-time capabilities. Models that perform well on general NLP benchmarks often lack the ability to construct multi-step reasoning chains or reflect on intermediate problem-solving states. Furthermore, while scaling up model size can improve reasoning capacity, it introduces prohibitive computational and deployment costs, especially for applied use in education, engineering, and decision-support systems.
Microsoft Releases Phi-4 Reasoning Model Suite
Microsoft recently introduced the Phi-4 reasoning family, consisting of three models— Phi-4-reasoning , Phi-4-reasoning-plus , and Phi-4-mini-reasoning . These models are derived from the Phi-4 base (14B parameters) and are specifically trained to handle complex reasoning tasks in mathematics, scientific domains, and software-related problem solving. Each variant addresses different trade-offs between computational efficiency and output precision. Phi-4-reasoning is optimized via supervised fine-tuning, while Phi-4-reasoning-plus extends this with outcome-based reinforcement learning, particularly targeting improved performance in high-variance tasks such as competition-level mathematics.
The open weight models were released with transparent training details and evaluation logs, including benchmark design, and are hosted on Hugging Face for reproducibility and public access.
Technical Composition and Methodological Advances
The Phi-4-reasoning models build upon the Phi-4 architecture with targeted improvements to model behavior and training regime. Key methodological decisions include:
- Structured Supervised Fine-Tuning (SFT): Over 1.4M prompts were curated with a focus on “boundary” cases—problems at the edge of Phi-4’s baseline capabilities. Prompts were sourced and filtered to emphasize multi-step reasoning rather than factual recall, and responses were synthetically generated using o3-mini in high-reasoning mode.
- Chain-of-Thought Format: To facilitate structured reasoning, models were trained to generate output using explicit
<think>tags, encouraging separation between reasoning traces and final answers. - Extended Context Handling: The RoPE base frequency was modified to support a 32K token context window, allowing for deeper solution traces, particularly relevant in multi-turn or long-form question formats.
- Reinforcement Learning (Phi-4-reasoning-plus): Using Group Relative Policy Optimization (GRPO), Phi-4-reasoning-plus was further refined on a small curated set of ∼6,400 math-focused problems. A reward function was crafted to favor correct, concise, and well-structured outputs, while penalizing verbosity, repetition, and format violations.
This data-centric and format-aware training regime supports better inference-time utilization and model generalization across domains, including unseen symbolic reasoning problems.
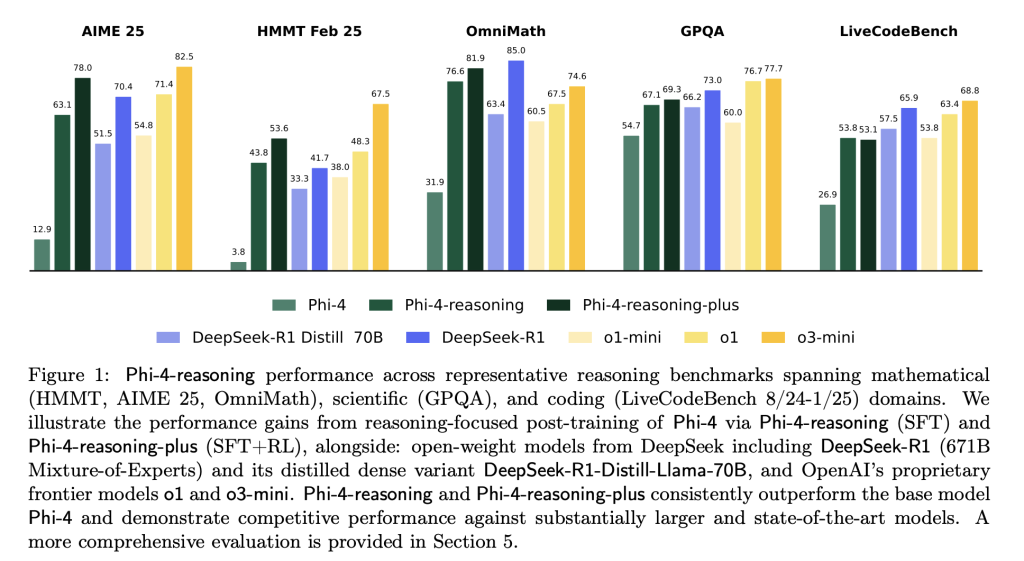
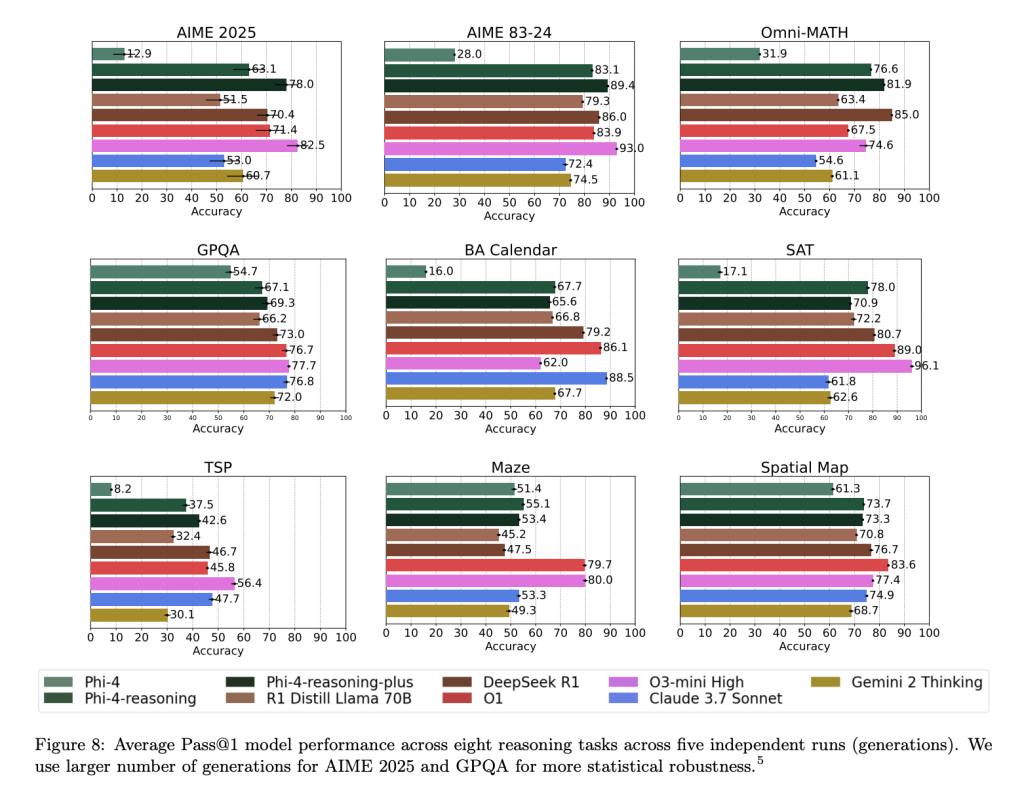
Evaluation and Comparative Performance
Across a broad range of reasoning benchmarks, Phi-4-reasoning and Phi-4-reasoning-plus deliver competitive results relative to significantly larger open-weight models:
Phi-4-reasoning-plus shows strong performance not only on domain-specific evaluations but also generalizes well to planning and combinatorial problems like TSP and 3SAT, despite no explicit training in these areas. Performance gains were also observed in instruction-following (IFEval) and long-context QA (FlenQA), suggesting the chain-of-thought formulation improves broader model utility.
Importantly, Microsoft reports full variance distributions across 50+ generation runs for sensitive datasets like AIME 2025, revealing that Phi-4-reasoning-plus matches or exceeds the performance consistency of models like o3-mini, while remaining disjoint from smaller baseline distributions like DeepSeek-R1-Distill.
Conclusion and Implications
The Phi-4 reasoning models represent a methodologically rigorous effort to advance small model capabilities in structured reasoning. By combining data-centric training, architectural tuning, and minimal but well-targeted reinforcement learning, Microsoft demonstrates that 14B-scale models can match or outperform much larger systems in tasks requiring multi-step inference and generalization.
The models’ open weight availability and transparent benchmarking set a precedent for future development in small LLMs, particularly for applied domains where interpretability, cost, and reliability are paramount. Future work is expected to extend the reasoning capabilities into additional STEM fields, improve decoding strategies, and explore scalable reinforcement learning on longer horizons.
Check out the Paper , HuggingFace Page and Microsoft Blog . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop

Meta and Booz Allen Deploy Space Llama: Open-Source AI Heads to the ISS for Onboard Decision-Making
Meta and Booz Allen Deploy Space Llama: Open-Source AI Heads to the ISS for Onboard Decision-Making
www.marktechpost.com
Meta and Booz Allen Deploy Space Llama: Open-Source AI Heads to the ISS for Onboard Decision-Making
By Nikhil
May 2, 2025
In a significant step toward enabling autonomous AI systems in space, Meta and Booz Allen Hamilton have announced the deployment of Space Llama , a customized instance of Meta’s open-source large language model , Llama 3.2, aboard the International Space Station (ISS) U.S. National Laboratory. This initiative marks one of the first practical integrations of an LLM in a remote, bandwidth-limited, space-based environment.
Addressing Disconnection and Autonomy Challenges
Unlike terrestrial applications, AI systems deployed in orbit face strict constraints—limited compute resources, constrained bandwidth, and high-latency communication links with ground stations. Space Llama has been designed to function entirely offline, allowing astronauts to access technical assistance, documentation, and maintenance protocols without requiring live support from mission control.
To address these constraints, the AI model had to be optimized for onboard deployment, incorporating the ability to reason over mission-specific queries, retrieve context from local data stores, and interact with astronauts in natural language—all without internet connectivity.
Technical Framework and Integration Stack
The deployment leverages a combination of commercially available and mission-adapted technologies:
- Llama 3.2 : Meta’s latest open-source LLM serves as the foundation, fine-tuned for contextual understanding and general reasoning tasks in edge environments. Its open architecture enables modular adaptation for aerospace-grade applications.
- A2E2™ (AI for Edge Environments) : Booz Allen’s AI framework provides containerized deployment and modular orchestration tailored to constrained environments like the ISS. It abstracts complexity in model serving and resource allocation across diverse compute layers.
- HPE Spaceborne Computer-2 : This edge computing platform, developed by Hewlett Packard Enterprise, provides reliable high-performance processing hardware for space. It supports real-time inference workloads and model updates when necessary.
- NVIDIA CUDA-capable GPUs : These enable the accelerated execution of transformer-based inference tasks while staying within the ISS’s strict power and thermal budgets.
This integrated stack ensures that the model operates within the limits of orbital infrastructure, delivering utility without compromising reliability.
Open-Source Strategy for Aerospace AI
The selection of an open-source model like Llama 3.2 aligns with growing momentum around transparency and adaptability in mission-critical AI. The benefits include:
- Modifiability : Engineers can tailor the model to meet specific operational requirements, such as natural language understanding in mission terminology or handling multi-modal astronaut inputs.
- Data Sovereignty : With all inference running locally, sensitive data never needs to leave the ISS, ensuring compliance with NASA and partner agency privacy standards.
- Resource Optimization : Open access to the model’s architecture allows for fine-grained control over memory and compute use—critical for environments where system uptime and resilience are prioritized.
- Community-Based Validation : Using a widely studied open-source model promotes reproducibility, transparency in behavior, and better testing under mission simulation conditions.
Toward Long-Duration and Autonomous Missions
Space Llama is not just a research demonstration—it lays the groundwork for embedding AI systems into longer-term missions. In future scenarios like lunar outposts or deep-space habitats, where round-trip communication latency with Earth spans minutes or hours, onboard intelligent systems must assist with diagnostics, operations planning, and real-time problem-solving.
Furthermore, the modular nature of Booz Allen’s A2E2 platform opens up the potential for expanding the use of LLMs to non-space environments with similar constraints—such as polar research stations, underwater facilities, or forward operating bases in military applications.
Conclusion
The Space Llama initiative represents a methodical advancement in deploying AI systems to operational environments beyond Earth. By combining Meta’s open-source LLMs with Booz Allen’s edge deployment expertise and proven space computing hardware, the collaboration demonstrates a viable approach to AI autonomy in space.
Rather than aiming for generalized intelligence, the model is engineered for bounded, reliable utility in mission-relevant contexts—an important distinction in environments where robustness and interpretability take precedence over novelty.
As space systems become more software-defined and AI-assisted, efforts like Space Llama will serve as reference points for future AI deployments in autonomous exploration and off-Earth habitation.
Check out the Details here . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop

LLMs Can Learn Complex Math from Just One Example: Researchers from University of Washington, Microsoft, and USC Unlock the Power of 1-Shot Reinforcement Learning with Verifiable Reward
LLMs Can Learn Complex Math from Just One Example: Researchers from University of Washington, Microsoft, and USC Unlock the Power of 1-Shot Reinforcement Learning with Verifiable Reward
www.marktechpost.com
LLMs Can Learn Complex Math from Just One Example: Researchers from University of Washington, Microsoft, and USC Unlock the Power of 1-Shot Reinforcement Learning with Verifiable Reward
By Sana Hassan
May 2, 2025
Recent advancements in LLMs such as OpenAI-o1, DeepSeek-R1, and Kimi-1.5 have significantly improved their performance on complex mathematical reasoning tasks. Reinforcement Learning with Verifiable Reward (RLVR) is a key contributor to these improvements, which uses rule-based rewards, typically a binary signal indicating whether a model’s solution to a problem is correct. Beyond enhancing final output accuracy, RLVR has also been observed to foster beneficial cognitive behaviors like self-reflection and improve generalization across tasks. While much research has focused on optimizing reinforcement learning algorithms like PPO and GRPO for greater stability and performance, the influence of training data—its quantity and quality—remains less understood. Questions around how much and what kind of data is truly effective for RLVR are still open, despite some work like LIMR introducing metrics to identify impactful examples and reduce dataset size while maintaining performance.
In contrast to the extensive research on data selection in supervised fine-tuning and human feedback-based reinforcement learning, the role of data in RLVR has seen limited exploration. While LIMR demonstrated that using a small subset of data (1.4k out of 8.5k examples) could maintain performance, it did not examine the extreme case of minimal data use. Another concurrent study found that even training with just four PPO examples led to notable improvements, but this finding wasn’t deeply investigated or benchmarked against full-dataset performance. Although RLVR shows great promise for enhancing reasoning in LLMs, a deeper, systematic study of data efficiency and selection in this context is still lacking.
Researchers from the University of Washington, University of Southern California, Microsoft, University of California, Santa Cruz, and Georgia Institute of Technology show that RLVR can significantly enhance large language models’ mathematical reasoning using a single training example, 1-shot RLVR. Applying it to Qwen2.5-Math-1.5B improves its MATH500 accuracy from 36.0% to 73.6%, matching the performance of much larger datasets. The improvements generalize across models, tasks, and algorithms. The study also reveals effects like cross-domain generalization, increased self-reflection, and post-saturation generalization, and highlights the roles of policy gradient loss and entropy-driven exploration.
The study investigates how much the RLVR training dataset can be reduced while retaining comparable performance to the full dataset. Remarkably, the authors find that a single training example—1-shot RLVR—can significantly boost mathematical reasoning in LLMs. The study shows that this effect generalizes across tasks, models, and domains. Interestingly, training on one example often enhances performance on unrelated domains. A simple data selection strategy based on training accuracy variance is proposed, but results show that even randomly chosen examples can yield major gains.
The study evaluates their method using Qwen2.5-Math-1.5B as the primary model and other models like Qwen2.5-Math-7B, Llama-3.2-3 B-Instructt, and DeepSeek-R1-DistillQwen-1.5 BB. They use a 1,209-example subset of the DeepScaleR dataset for data selection, and the MATH dataset for comparison. Training involves the Verl pipeline, with carefully chosen hyperparameters and batch configurations. Surprisingly, training with just one or two examples—especially π1 and π13—leads to strong generalization, even beyond math tasks. This “post-saturation generalization” persists despite overfitting signs. The study also finds increased model self-reflection and shows that even simple examples can significantly enhance performance across domains.

In conclusion, the study explores the mechanisms behind the success of 1-shot RLVR, demonstrating that base models already possess strong reasoning abilities. Experiments show that even a single example can significantly improve performance on reasoning tasks, suggesting the model’s inherent capacity for reasoning. The study highlights that policy gradient loss is key to 1-shot RLVR’s effectiveness, with entropy loss further enhancing performance. Additionally, encouraging exploration through techniques like entropy regularization can improve post-saturation generalization. The findings also emphasize the need for careful data selection to optimize the model’s performance, particularly in data-constrained scenarios.
Check out the Paper and GitHub Page . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit . For Promotion and Partnerships, please talk us .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop

Meta AI Releases Llama Prompt Ops: A Python Toolkit for Prompt Optimization on Llama Models
Meta AI Releases Llama Prompt Ops: A Python Toolkit for Prompt Optimization on Llama Models
www.marktechpost.com
Meta AI Releases Llama Prompt Ops: A Python Toolkit for Prompt Optimization on Llama Models
By Asif Razzaq
May 3, 2025
Meta AI has released Llama Prompt Ops , a Python package designed to streamline the process of adapting prompts for Llama models. This open-source tool is built to help developers and researchers improve prompt effectiveness by transforming inputs that work well with other large language models (LLMs) into forms that are better optimized for Llama. As the Llama ecosystem continues to grow, Llama Prompt Ops addresses a critical gap: enabling smoother and more efficient cross-model prompt migration while enhancing performance and reliability.
Why Prompt Optimization Matters
Prompt engineering plays a crucial role in the effectiveness of any LLM interaction. However, prompts that perform well on one model—such as GPT, Claude, or PaLM—may not yield similar results on another. This discrepancy is due to architectural and training differences across models. Without tailored optimization, prompt outputs can be inconsistent, incomplete, or misaligned with user expectations.
Llama Prompt Ops solves this challenge by introducing automated and structured prompt transformations. The package makes it easier to fine-tune prompts for Llama models, helping developers unlock their full potential without relying on trial-and-error tuning or domain-specific knowledge.
What Is Llama Prompt Ops?
At its core, Llama Prompt Ops is a library for systematic prompt transformation . It applies a set of heuristics and rewriting techniques to existing prompts, optimizing them for better compatibility with Llama-based LLMs. The transformations consider how different models interpret prompt elements such as system messages, task instructions, and conversation history.
This tool is particularly useful for:
- Migrating prompts from proprietary or incompatible models to open Llama models.
- Benchmarking prompt performance across different LLM families.
- Fine-tuning prompt formatting for improved output consistency and relevance.
Features and Design
Llama Prompt Ops is built with flexibility and usability in mind. Its key features include:
- Prompt Transformation Pipeline : The core functionality is organized into a transformation pipeline. Users can specify the source model (e.g.,
gpt-3.5-turbo) and target model (e.g.,llama-3) to generate an optimized version of a prompt. These transformations are model-aware and encode best practices that have been observed in community benchmarks and internal evaluations. - Support for Multiple Source Models : While optimized for Llama as the output model, Llama Prompt Ops supports inputs from a wide range of common LLMs, including OpenAI’s GPT series, Google’s Gemini (formerly Bard), and Anthropic’s Claude.
- Test Coverage and Reliability : The repository includes a suite of prompt transformation tests that ensure transformations are robust and reproducible. This ensures confidence for developers integrating it into their workflows.
- Documentation and Examples : Clear documentation accompanies the package, making it easy for developers to understand how to apply transformations and extend the functionality as needed.
How It Works
The tool applies modular transformations to the prompt’s structure. Each transformation rewrites parts of the prompt, such as:
- Replacing or removing proprietary system message formats.
- Reformatting task instructions to suit Llama’s conversational logic.
- Adapting multi-turn histories into formats more natural for Llama models.
The modular nature of these transformations allows users to understand what changes are made and why, making it easier to iterate and debug prompt modifications.

Conclusion
As large language models continue to evolve, the need for prompt interoperability and optimization grows. Meta’s Llama Prompt Ops offers a practical, lightweight, and effective solution for improving prompt performance on Llama models. By bridging the formatting gap between Llama and other LLMs, it simplifies adoption for developers while promoting consistency and best practices in prompt engineering.
Check out the GitHub Page . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit . For Promotion and Partnerships, please talk us .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
Mem0: A Scalable Memory Architecture Enabling Persistent, Structured Recall for Long-Term AI Conversations Across Sessions
Mem0: A Scalable Memory Architecture Enabling Persistent, Structured Recall for Long-Term AI Conversations Across Sessions
www.marktechpost.com
Mem0: A Scalable Memory Architecture Enabling Persistent, Structured Recall for Long-Term AI Conversations Across Sessions
By Asif Razzaq
April 30, 2025
Large language models can generate fluent responses, emulate tone, and even follow complex instructions; however, they struggle to retain information across multiple sessions. This limitation becomes more pressing as LLMs are integrated into applications that require long-term engagement, such as personal assistance, health management, and tutoring. In real-life conversations, people recall preferences, infer behaviors, and construct mental maps over time. A person who mentioned their dietary restrictions last week expects those to be taken into account the next time food is discussed. Without mechanisms to store and retrieve such details across conversations, AI agents fail to offer consistency and reliability, undermining user trust.
The central challenge with today’s LLMs lies in their inability to persist relevant information beyond the boundaries of a conversation’s context window. These models rely on limited tokens, sometimes as high as 128K or 200K, but when long interactions span days or weeks, even these expanded windows fall short. More critically, the quality of attention degrades over distant tokens, making it harder for models to locate or utilize earlier context effectively. A user may bring up personal details, switch to a completely different topic, and return to the original subject much later. Without a robust memory system, the AI will likely ignore the previously mentioned facts. This creates friction, especially in scenarios where continuity is crucial. The issue is not just forgetting information, but also retrieving the wrong information from irrelevant parts of the conversation history due to token overflow and thematic drift.
Several attempts have been made to tackle this memory gap. Some systems rely on retrieval-augmented generation ( RAG ) techniques, which utilize similarity searches to retrieve relevant text chunks during a conversation. Others employ full-context approaches that simply refeed the entire conversation into the model, which increases latency and token costs. Proprietary memory solutions and open-source alternatives try to improve upon these by storing past exchanges in vector databases or structured formats. However, these methods often lead to inefficiencies, such as retrieving excessive irrelevant information or failing to consolidate updates in a meaningful manner. They also lack effective mechanisms to detect conflicting data or prioritize newer updates, leading to fragmented memories that hinder reliable reasoning.
A research team from Mem0.ai developed a new memory-focused system called Mem0 . This architecture introduces a dynamic mechanism to extract, consolidate, and retrieve information from conversations as they happen. The design enables the system to selectively identify useful facts from interactions, evaluate their relevance and uniqueness, and integrate them into a memory store that can be consulted in future sessions. The researchers also proposed a graph-enhanced version, Mem0g, which builds upon the base system by structuring information in relational formats. These models were tested using the LOCOMO benchmark and compared against six other categories of memory-enabled systems, including memory-augmented agents, RAG methods with varying configurations, full-context approaches, and both open-source and proprietary tools. Mem0 consistently achieved superior performance across all metrics.

The core of the Mem0 system involves two operational stages. In the first phase, the model processes pairs of messages, typically a user’s question and the assistant’s response, along with summaries of recent conversations. A combination of global conversation summaries and the last 10 messages serves as the input for a language model that extracts salient facts. These facts are then analyzed in the second phase, where they are compared with similar existing memories in a vector database. The top 10 most similar memories are retrieved, and a decision mechanism, referred to as a ‘tool call’, determines whether the fact should be added, updated, deleted, or ignored. These decisions are made by the LLM itself rather than a classifier, streamlining memory management and avoiding redundancies.

The advanced variant, Mem0g, takes the memory representation a step further. It translates conversation content into a structured graph format, where entities, such as people, cities, or preferences, become nodes, and relationships, such as “lives in” or “prefers,” become edges. Each entity is labeled, embedded, and timestamped, while the relationships form triplets that capture the semantic structure of the dialogue. This format supports more complex reasoning across interconnected facts, allowing the model to trace relational paths across sessions. The conversion process uses LLMs to identify entities, classify them, and build the graph incrementally. For example, if a user discusses travel plans, the system creates nodes for cities, dates, and companions, thereby building a detailed and navigable structure of the conversation.

The performance metrics reported by the research team underscore the strength of both models. Mem0 showed a 26% improvement over OpenAI’s system when evaluated using the “LLM-as-a-Judge” metric. Mem0g, with its graph-enhanced design, achieved an additional 2% gain, pushing the total improvement to 28%. In terms of efficiency, Mem0 demonstrated 91% lower p95 latency than full-context methods, and more than 90% savings in token cost. This balance between performance and practicality is significant for production use cases, where response times and computational expenses are critical. The models also handled a wide range of question types, from single-hop factual lookups to multi-hop and open-domain queries, outperforming all other approaches in accuracy across categories.
Several Key takeaways from the research on Mem0 include:
- Mem0 uses a two-step process to extract and manage salient conversation facts, combining recent messages and global summaries to form a contextual prompt.
- Mem0g builds memory as a directed graph of entities and relationships, offering superior reasoning over complex information chains.
- Mem0 surpassed OpenAI’s memory system with a 26% improvement on LLM-as-a-Judge, while Mem0g added an extra 2% gain, achieving 28% overall.
- Mem0 achieved a 91% reduction in p95 latency and saved over 90% in token usage compared to full-context approaches.
- These architectures maintain fast, cost-efficient performance even when handling multi-session dialogues, making them suitable for deployment in production settings.
- The system is ideal for AI assistants in tutoring, healthcare, and enterprise settings where continuity of memory is essential.
Check out the Paper . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
DeepSeek-AI Released DeepSeek-Prover-V2: An Open-Source Large Language Model Designed for Formal Theorem, Proving through Subgoal Decomposition and Reinforcement Learning
DeepSeek-AI Released DeepSeek-Prover-V2: An Open-Source Large Language Model Designed for Formal Theorem, Proving through Subgoal Decomposition and Reinforcement Learning
www.marktechpost.com
DeepSeek-AI Released DeepSeek-Prover-V2: An Open-Source Large Language Model Designed for Formal Theorem, Proving through Subgoal Decomposition and Reinforcement Learning
By Asif Razzaq
May 1, 2025
Formal mathematical reasoning has evolved into a specialized subfield of artificial intelligence that requires strict logical consistency. Unlike informal problem solving, which allows for intuition and loosely defined heuristics, formal theorem proving relies on every step being fully described, precise, and verifiable by computational systems. Proof assistants, such as Lean, Coq, and Isabelle, serve as the structural frameworks within which these formal proofs are constructed. Their operation demands logical soundness with no space for omissions, approximations, or unstated assumptions. This makes the challenge particularly demanding for AI systems, especially large language models, which excel in producing coherent natural language responses but typically lack the rigor to produce verifiable formal proofs. However, the desire to blend these strengths, AI’s fluency in informal reasoning and the structure of formal verification, has led to new innovations at the interface of language modeling and formal logic automation.
A major issue arises from the inability of current language models to bridge the conceptual divide between informal and formal reasoning. Language models typically excel at generating human-like explanations and solving math problems written in natural language. However, this reasoning is inherently informal and often lacks the structural precision required by formal logic systems. While humans can intuitively leap from one deductive step to another, proof assistants require a fully specified sequence of steps, free of ambiguity. Thus, the challenge is to guide AI models to produce logically coherent formal outputs from their otherwise informal and intuitive internal reasoning processes. This problem becomes increasingly complex when handling advanced theorems from domains such as number theory or geometry, where precision is crucial.
Recent efforts have attempted to address this issue by guiding models first to generate natural language proof sketches, which are then manually or semi-automatically translated into formal proof steps. A known strategy includes decomposing a complex theorem into smaller subgoals. Each subgoal represents a lemma that can be tackled independently and later combined to form a complete proof. Frameworks like “Draft, Sketch, and Prove” have applied this idea, using language models to generate proof outlines that are then translated into formal language. Another method employs hierarchical reinforcement learning, breaking down complex mathematical problems into simpler layers. However, these models often struggle to produce fully verifiable outputs in Lean or Coq environments. Moreover, the training data for these models is usually limited, and proof attempts frequently fail to yield successful outcomes that provide useful learning signals.
A team of researchers from DeepSeek-AI has introduced a new model, DeepSeek-Prover-V2 , designed to generate formal mathematical proofs by leveraging subgoal decomposition and reinforcement learning. The core of their approach utilizes DeepSeek-V3 to break down a complex theorem into manageable subgoals, each of which is translated into a “have” statement in Lean 4 with a placeholder indicating that the proof is incomplete. These subgoals are then passed to a 7B-sized prover model that completes each proof step. Once all steps are resolved, they are synthesized into a complete Lean proof and paired with the original natural language reasoning generated by DeepSeek-V3. This forms a rich cold-start dataset for reinforcement learning. Importantly, the model’s training is entirely bootstrapped from synthetic data, with no human-annotated proof steps used.

The cold-start pipeline begins by prompting DeepSeek-V3 to create proof sketches in natural language. These sketches are transformed into formal theorem statements with unresolved parts. A key innovation lies in recursively solving each subgoal using the 7B prover, reducing computation costs while maintaining formal rigor. Researchers constructed a curriculum learning framework that increased the complexity of training tasks over time. They also implemented two types of subgoal theorems, one incorporating preceding subgoals as premises, and one treating them independently. This dual structure was embedded into the model’s expert iteration stage to train it on progressively more challenging problem sets. The model’s capability was then reinforced through a consistency-based reward system during training, ensuring that all decomposed lemmas were correctly incorporated into the final formal proof.

On the MiniF2F-test benchmark, the model achieved an 88.9% pass rate with high sampling (Pass@8192), compared to 82.0% by Kimina-Prover and 64.7% by Geodel-Prover. It also solved 49 out of 658 problems from PutnamBench, a platform featuring challenging mathematical tasks. On the newly introduced ProverBench dataset, comprising 325 formalized problems, the model addressed 6 out of 15 issues from the AIME (American Invitational Mathematics Examination) competitions for the years 2024 and 2025. These benchmarks highlight the model’s generalization ability across multiple formal reasoning tasks. Even when compared to DeepSeek-V3, which employs natural-language reasoning, the new model demonstrates competitive performance, solving a comparable number of AIME problems while ensuring formal verifiability.

Several Key Takeaways from the Research on DeepSeek-Prover-V2:
- DeepSeek-Prover-V2 achieved an 88.9% pass rate on the MiniF2F-test (Pass@8192), the highest reported among formal reasoning models so far.
- The model successfully solved 49 out of 658 problems from the PutnamBench dataset, which contains advanced mathematical challenges.
- It tackled 6 out of 15 problems from the recent AIME 2024–2025 competitions, showcasing real-world applicability.
- A new benchmark, ProverBench, comprising 325 formal problems, has been introduced for evaluating formal reasoning models.
- The pipeline unifies natural language proof sketching and formal proof construction by combining DeepSeek-V3 and a 7B prover model.
- Two types of subgoal decompositions—one with and one without dependent premises—were used to train the model in a structured, curriculum-guided manner.
- Reinforcement learning with a consistency-based reward significantly improved proof accuracy by enforcing structural alignment between sketch and solution.
- The entire training strategy relies on synthetic cold-start data, eliminating dependence on manually labeled proofs.
Check out the model on Paper and GitHub Page . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
Meta AI Introduces ReasonIR-8B: A Reasoning-Focused Retriever Optimized for Efficiency and RAG Performance
Meta AI Introduces ReasonIR-8B: A Reasoning-Focused Retriever Optimized for Efficiency and RAG Performance
www.marktechpost.com
Meta AI Introduces ReasonIR-8B: A Reasoning-Focused Retriever Optimized for Efficiency and RAG Performance
By Asif Razzaq
April 30, 2025
Addressing the Challenges in Reasoning-Intensive Retrieval
Despite notable progress in retrieval-augmented generation ( RAG ) systems, retrieving relevant information for complex, multi-step reasoning tasks remains a significant challenge. Most retrievers today are trained on datasets composed of short factual questions, which align well with document-level lexical or semantic overlaps. However, they fall short when faced with longer, abstract, or cross-domain queries that require synthesizing dispersed knowledge. In such cases, retrieval errors can propagate through the pipeline, impairing downstream reasoning by large language models (LLMs). While LLM-based rerankers can improve relevance, their substantial computational cost often renders them impractical in real-world deployments.
Meta AI Introduces ReasonIR-8B, a Retriever Built for Reasoning
Meta AI has released ReasonIR-8B , a retriever model designed explicitly for reasoning-intensive information retrieval. Trained from LLaMA3.1-8B, the model establishes new performance standards on the BRIGHT benchmark, achieving a normalized Discounted Cumulative Gain (nDCG@10) of 36.9 when used with a lightweight Qwen2.5 reranker. Notably, it surpasses leading reranking models such as Rank1-32B while offering 200× lower inference-time compute , making it significantly more practical for scaled RAG applications.
ReasonIR-8B is trained using a novel data generation pipeline, ReasonIR-SYNTHESIZER , which constructs synthetic queries and document pairs that mirror the challenges posed by real-world reasoning tasks. The model is released open-source on Hugging Face , along with training code and synthetic data tools, enabling further research and reproducibility.
Model Architecture, Training Pipeline, and Key Innovations
ReasonIR-8B employs a bi-encoder architecture , where queries and documents are encoded independently into embeddings and scored via cosine similarity. The model’s training relies heavily on synthetically generated data tailored to reasoning scenarios. The ReasonIR-SYNTHESIZER pipeline produces two primary types of training instances:
- Varied-Length (VL) Queries : These are long, information-rich queries (up to 2000 tokens), paired with corresponding documents, encouraging the retriever to handle extended contexts effectively.
- Hard Queries (HQ) : Derived from curated documents with high educational value, these queries are designed to require logical inference. Multi-turn prompts are used to construct hard negatives —documents that appear superficially relevant but do not contain the necessary reasoning pathways.
This approach contrasts with conventional negative sampling methods, which often rely on lexical overlap and are less effective for abstract or multi-hop questions.
Additionally, the model’s attention mask is modified from LLaMA’s causal configuration to a bi-directional one , allowing the encoder to consider the full query context symmetrically, which is beneficial for non-sequential semantic alignment.
Empirical Results on IR and RAG Benchmarks
ReasonIR-8B achieves strong performance across several benchmarks:
- BRIGHT Benchmark (Reasoning-Intensive Retrieval):
- 24.4 nDCG@10 on original queries
- 29.9 with GPT-4 rewritten queries
- 36.9 with Qwen2.5 reranking , outperforming larger LLM rerankers at a fraction of the cost
- Retrieval-Augmented Generation (RAG) Tasks:
- +6.4% improvement on MMLU over a closed-book baseline
- +22.6% improvement on GPQA
These gains are consistent across both standard and rewritten queries, with further improvements observed when combining REASONIR-8B with a sparse retriever like BM25 or a lightweight reranker.

Importantly, the model continues to improve as query lengths scale , unlike other retrievers whose performance plateaus or declines. This suggests that ReasonIR-8B can better exploit information-rich queries, making it particularly well-suited for test-time techniques such as query rewriting.
Conclusion
ReasonIR-8B addresses a key bottleneck in reasoning-focused information retrieval by introducing a retriever optimized not only for relevance but also for computational efficiency. Its design—rooted in synthetic training tailored for reasoning, coupled with architectural and data-centric improvements—enables consistent gains in both retrieval and RAG tasks.
By releasing the model, codebase, and training data generation pipeline as open-source tools, Meta AI encourages the research community to extend this work toward more robust, multilingual, and multimodal retrievers. For applications requiring cost-effective and high-quality retrieval under reasoning constraints, ReasonIR-8B represents a compelling and practical solution.
Check out the Paper , HuggingFace Page and GitHub Page . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup . Don’t Forget to join our 90k+ ML SubReddit .
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop

Training LLM Agents Just Got More Stable: Researchers Introduce StarPO-S and RAGEN to Tackle Multi-Turn Reasoning and Collapse in Reinforcement Learning
Training LLM Agents Just Got More Stable: Researchers Introduce StarPO-S and RAGEN to Tackle Multi-Turn Reasoning and Collapse in Reinforcement Learning
www.marktechpost.com
Training LLM Agents Just Got More Stable: Researchers Introduce StarPO-S and RAGEN to Tackle Multi-Turn Reasoning and Collapse in Reinforcement Learning
By Mohammad Asjad
May 1, 2025
Large language models (LLMs) face significant challenges when trained as autonomous agents in interactive environments. Unlike static tasks, agent settings require sequential decision-making, cross-turn memory maintenance, and adaptation to stochastic environmental feedback. These capabilities are essential for developing effective planning assistants, robotics applications, and tutoring agents that can self-improve through experience. While reinforcement learning (RL) has been applied to LLMs using rule-based rewards, training self-evolving agents that can reason and adapt remains underexplored. Current approaches suffer from training instability, complex reward signal interpretation, and limited generalisation across varying prompts or changing environments, particularly during multi-turn interactions with unpredictable feedback. The fundamental question emerges: which design elements are crucial for creating LLM agents that learn effectively and maintain stability throughout their evolution?
Through diverse methodologies, RL has significantly advanced LLMs’ reasoning capabilities. PPO maintains training stability by clipping policy updates, while GRPO enhances systematic problem-solving abilities. SAC employs entropy-regularised objectives for robust exploration, and meta tokens facilitate structured thinking. PRM and MCTS-based approaches have further improved systematic reasoning. Simultaneously, chain-of-thought techniques like STaR iteratively utilise small rationale examples alongside larger datasets. At the same time, DAPO, Dr. GRPO, and Open Reasoner Zero demonstrate that minimalist RL techniques with decoupled clipping and simple reward schemes can substantially enhance reasoning performance.
LLM agent architectures have evolved from basic reasoning-action frameworks to structured planning approaches and complex multi-agent systems. Testing environments range from specialised platforms like Sokoban and FrozenLake to general-purpose frameworks like HuggingGPT, enabling applications from web navigation to coding assistance and embodied tasks. Despite these advances, challenges persist in architectural complexity and self-correction, particularly for diverse multi-step reasoning tasks where maintaining coherence across interactions remains problematic.
Researchers have approached agent learning through StarPO (State-Thinking-Actions-Reward Policy Optimisation) , a unified framework for trajectory-level agent training with flexible control over reasoning processes, reward mechanisms, and prompt structures. Building on this framework, they developed RAGEN , a modular system implementing complete training loops for analysing LLM agent dynamics in multi-turn stochastic environments. To isolate learning factors from confounding variables like pretrained knowledge, evaluation focuses on three controlled gaming environments: Bandit (single-turn, stochastic), Sokoban (multi-turn, deterministic), and Frozen Lake (multi-turn, stochastic). These minimalistic environments require policy learning through interaction rather than relying on pre-existing knowledge. The analysis reveals three critical dimensions of agent learning: gradient stability issues in multi-turn reinforcement learning, the importance of rollout frequency and diversity in shaping agent evolution, and the need for carefully designed reward signals to develop genuine reasoning capabilities rather than shallow action selection or hallucinated thinking processes.

StarPO represents a unique framework designed specifically for optimising multi-turn interaction trajectories in LLM agents. Unlike traditional approaches that treat each action independently, StarPO optimises entire trajectories—including observations, reasoning traces, actions, and feedback—as coherent units. This trajectory-level approach is particularly suited for interactive environments where agents must maintain memory across turns and adapt to stochastic feedback. StarPO’s objective function focuses on maximising expected rewards across complete trajectories rather than individual steps, making it directly compatible with autoregressive LLMs through decomposition into token-level likelihoods. The framework integrates reasoning-guided structured outputs that combine both intermediate thinking processes and executable actions, enabling agents to develop more sophisticated decision-making capabilities while maintaining learning stability in complex environments.


Experimental results reveal that StarPO-S significantly outperforms vanilla StarPO across multiple agent tasks. By implementing uncertainty-based instance filtering, KL term removal, and asymmetric clipping, StarPO-S effectively delays performance collapse and enhances final task outcomes. The stabilised approach demonstrates particular effectiveness in complex environments like FrozenLake and Sokoban, where retaining only 25-50% of high-variance rollouts dramatically improves training stability while reducing computational requirements by up to 50%.
Task diversity and interaction granularity significantly impact performance. Models trained with higher task diversity and 4-6 actions per turn demonstrate superior generalisation capabilities across novel vocabulary and larger environments. Also, frequent rollout updates prove critical for maintaining alignment between optimisation targets and policy behavior. Agents trained with up-to-date rollouts every 1-10 updates achieve faster convergence and higher success rates compared to those relying on outdated trajectory data.
Symbolic reasoning benefits vary substantially between single-turn and multi-turn tasks. While reasoning traces significantly improve generalisation in single-turn Bandit environments, they provide limited advantage in complex multi-turn settings like Sokoban and FrozenLake. Analysis shows reasoning length consistently declines during training, suggesting models gradually suppress their thought processes when rewards are sparse and delayed. This highlights the need for reward mechanisms that directly reinforce intermediate reasoning steps rather than relying solely on outcome-based feedback.







This research establishes reinforcement learning as a viable approach for training language agents in complex, stochastic environments. StarPO-S represents a significant advancement in stabilising multi-turn agent training through uncertainty-based sampling and exploration encouragement. By transitioning from human supervision to verifiable outcome-based rewards, this framework creates opportunities for developing more capable AI systems across theorem proving, software engineering, and scientific discovery. Future work should focus on multi-modal inputs, enhanced training efficiency, and applications to increasingly complex domains with verifiable objectives.
Check out the Paper and GitHub Page .