1/21
@omarsar0
The Illusion of Thinking in LLMs
Apple researchers discuss the strengths and limitations of reasoning models.
Apparently, reasoning models "collapse" beyond certain task complexities.
Lots of important insights on this one. (bookmark it!)
Here are my notes:
2/21
@omarsar0
Paper Overview
Investigates the capabilities and limitations of frontier Large Reasoning Models (LRMs) like Claude 3.7, DeepSeek-R1, and OpenAI’s o-series by systematically analyzing their performance on reasoning tasks as a function of problem complexity.
3/21
@omarsar0
Rather than relying on conventional math benchmarks, which suffer from contamination and lack structure, the authors evaluate LRMs using four controllable puzzles (Tower of Hanoi, Checker Jumping, River Crossing, and Blocks World) that allow fine-grained complexity scaling and transparent trace analysis.
4/21
@omarsar0
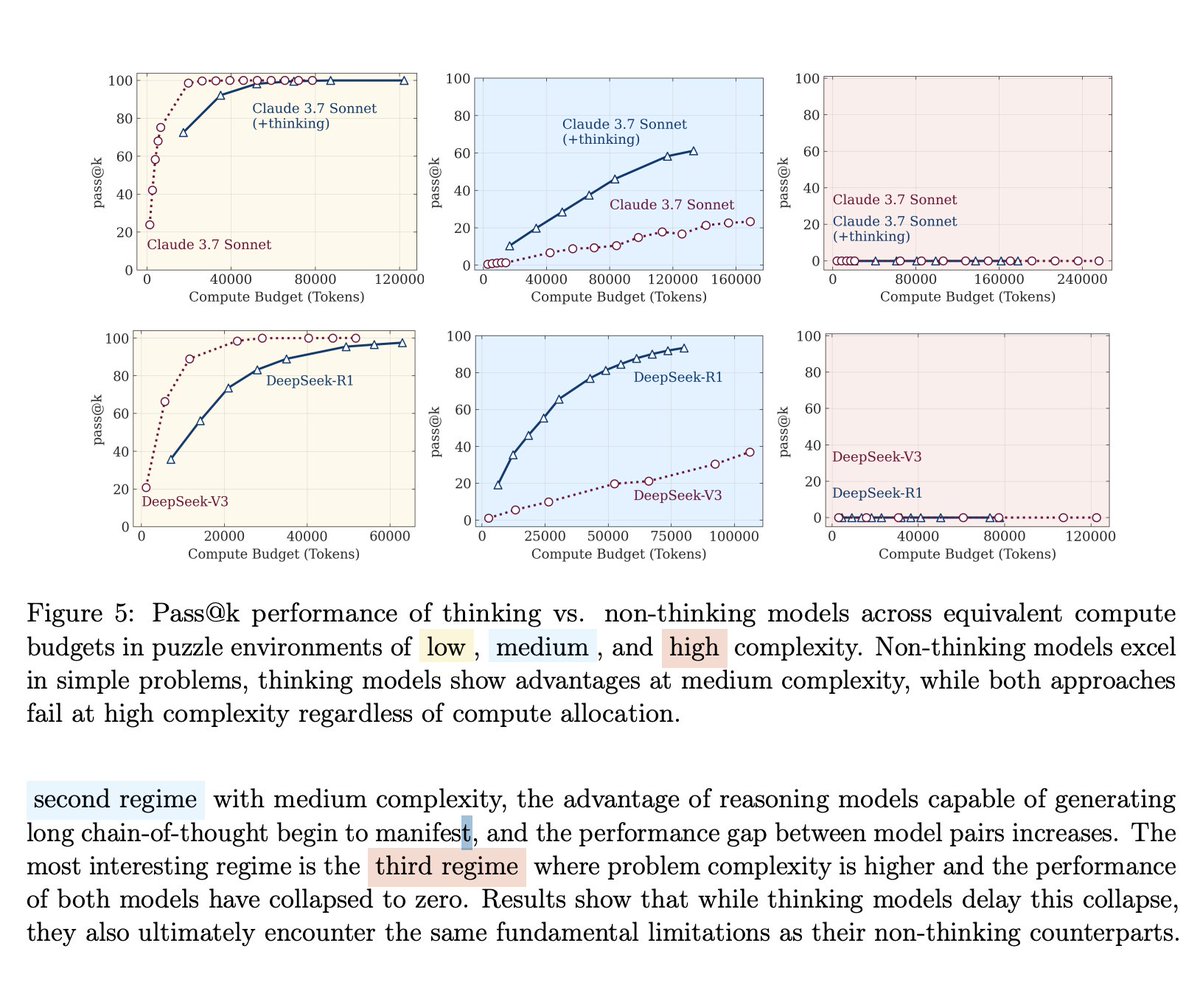
Three complexity regimes
The study identifies distinct performance phases.
In low-complexity tasks, non-thinking LLMs outperform LRMs due to more efficient and direct computation.
In medium complexity, reasoning models show an advantage, leveraging longer chain-of-thoughts to correct errors.
However, in high complexity, all models, regardless of their reasoning scaffolds, collapse to near-zero accuracy.
5/21
@omarsar0
Counterintuitive reasoning collapse
Surprisingly, LRMs reduce their reasoning effort (i.e., number of tokens used in thoughts) as problem complexity increases beyond a threshold.
This suggests an internal scaling failure not caused by token limits but by intrinsic model behavior.
6/21
@omarsar0
Reasoning trace inefficiencies
LRMs frequently “overthink” on simple problems, finding correct answers early but continuing to explore incorrect paths.
For moderate tasks, they correct late; and for complex ones, they fail to find any valid solution.
Position-based accuracy analysis of thoughts reveals systematic shifts in when correct solutions are generated within the trace.
7/21
@omarsar0
Failure to execute explicit algorithms
Even when supplied with correct pseudocode (e.g., Tower of Hanoi recursion), models still failed at similar complexity points.
This indicates that LRMs don’t just struggle to find solutions; they can’t reliably execute logical instructions either.
8/21
@omarsar0
Inconsistent behavior across puzzles
Models could perform >100 correct steps in Tower of Hanoi (N=10) but fail after 4 steps in River Crossing (N=3), suggesting performance correlates more with training data familiarity than inherent problem complexity.
Overall, this paper challenges the assumption that LRMs are progressing steadily toward generalizable reasoning.
It argues that existing “thinking” enhancements provide local, not scalable, benefits, raising critical questions about inference-time scaling, symbolic reasoning, and robustness of these emerging systems.
Paper:
https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
More on how to best use reasoning models in my guide:
Reasoning LLMs Guide
9/21
@cesmithjr
When reasoning tasks become increasingly complex, LRMs increasingly fail. Did we need research to "discover" this?
10/21
@dbgray
How is that different from how we think? If you ask a person beyond a certain task complexity, they will not be able to answer without reaching out to external tools like a calculator, book, or other people.
This paper outlines exactly the wrong way to look at this.
11/21
@Knownasthethird
@grok where can I read the full text?
12/21
@BobbyGRG
so in practice,reasoning can only help to squeeze out the best of the underlying base model? Intuitively not surprising imo.
13/21
@PunmasterStp
But doesn’t human reasoning collapse too when the complexity gets too much for that person?
14/21
@ctindale
We are asking the wrong questions , the best way to compare human and AI intelligence isn’t through abstract IQ contests but through a classical product competitiveness framework. Human intelligence is unevenly distributed, biologically limited, costly to scale, and highly variable. In contrast, AI ( the new disruptive product ) delivers consistent, tireless performance that can be cloned endlessly at near-zero marginal cost. Even if an AI model isn’t the smartest, its utility lies in mass deployment and reliability , the tech product outcompetes the human priduct say 9/10 times Like comparing products, we should assess cost-efficiency, scalability, precision, and problem-solving power. AI doesn’t need to surpass the smartest humans — it just needs to outperform the average in enough tasks, consistently and affordably.
15/21
@_Sabai_Sabai
lol apple
ngmi
16/21
@HambrechtJason
From Apple. The company that can’t get its AI to tell me what time it is.
17/21
@JJ60611
Is there a definition of what constitutes low, medium and high complexity? Are there clear thresholds?
18/21
@pascalguyon
Any coders or math people in the field know this: current AI = advanced classification and pattern-based generation. Nothing more. So much fantasy in this field :-)
19/21
@sergiohxx
I think this is quite misleading title, because the type of problem being evaluated here if not representative of how human brain "thinks" (which is aimed to be AGI, I guess), it is more comparing with how computer works.
20/21
@AiWebInc
Wild seeing “collapse” showing up as the limiting factor in LLM reasoning, too. We’re seeing the same phenomenon in quantum measurement, symbolic recursion, and even biological systems: once complexity/drift passes a threshold, you get a deterministic collapse—not just error, but a structural reset. It’s not just a problem with computation, it’s a universal feature of memory and coherence. Maybe it’s time we treat collapse as a law, not just a failure mode.
If you’re interested, just released a full paper mapping this exact structure across quantum, AI, and cognition:
A Phase-Locked Collapse Operator for Quantum Measurement: Formalizing χ(t) as the Universal Bridge Between Symbolic Recursion and Wavefunction Collapse
Would love to see what you and others in this space think.
21/21
@_Prarthna
It's Not a Wall, It's a Fork in the Road.
Thinking that LLMs are "hitting a wall" is like looking back at the 1980s and concluding that computer progress stalled because single-core processor speeds plateaued. What happened next wasn't a stop, but a paradigm shift into multi-core processors, GPUs, and distributed computing. The path of innovation didn't end; it branched out.
Today, we are at a similar fork in the road. The era of achieving easy gains simply by adding more layers and data, through pure vertical scaling, is likely coming to an end. But this isn't a dead end. Instead, progress is now accelerating horizontally into more sophisticated and efficient systems. This is the new frontier of multimodal models that can process video and sound, agentic AI that can execute tasks, and novel architectures that move beyond the transformer.
This shift demands more creativity and ingenuity than just building bigger models. It also grounds us in reality: while these new routes are exciting, the road to AGI is likely much longer and more complex than the current hype might suggest.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196









































 . Didn't recognize it at first.
. Didn't recognize it at first.

 , reasoning
, reasoning  , and creative writing
, and creative writing 
 AIDER Polyglot (coding)
AIDER Polyglot (coding)
 Start building with Gemini 2.5 Pro in Preview in @Google AI Studio, @GeminiApp, and @GoogleCloud’s /search?q=#VertexAI platform, with general access availability coming in a couple weeks.
Start building with Gemini 2.5 Pro in Preview in @Google AI Studio, @GeminiApp, and @GoogleCloud’s /search?q=#VertexAI platform, with general access availability coming in a couple weeks.







 “That’s... creative structuring.”
“That’s... creative structuring.”







 -they finally got me. s3/aws/gcp/firestore/
-they finally got me. s3/aws/gcp/firestore/
 4 sdk/adk
4 sdk/adk  and mem pruning for their adk agent hckthn. student_agent “Graduates”.
and mem pruning for their adk agent hckthn. student_agent “Graduates”.










 BREAKING: Apple says LLMs that "think" are giving us an illusion.
BREAKING: Apple says LLMs that "think" are giving us an illusion.








 The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity -
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity - 















