
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AI that’s smarter than humans? Americans say a firm “no thank you.”
- Thread starter bnew
- Start date
More options
Who Replied?


[Discussion] In which universe are these both true? AI labs scrambling for ~10 billion USD in funding will create AGI before the most valuable company having cashflow of hundreds of billions of dollar every quarter struggles creates a useful voice assistant. What's hype what's real  , IDK anymore.
, IDK anymore.


, IDK anymore.
1/1
@MikelEcheve
Anthropic predicts AI could surpass Nobel laureates in biology, computer science, math, and engineering by 2026-2027. CEO Dario Amodei envisions it as 'a country of geniuses in a data center,' driving breakthroughs in medicine, science, and beyond. In his Paris AI Summit statement, he hints at an intelligence explosion. See:
https://nitter.poast.org/AnthropicAI/status/1889296580936683846 . This could transform humanity—new theories, cures, and tech await. Are we ready?

To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@MikelEcheve
Anthropic predicts AI could surpass Nobel laureates in biology, computer science, math, and engineering by 2026-2027. CEO Dario Amodei envisions it as 'a country of geniuses in a data center,' driving breakthroughs in medicine, science, and beyond. In his Paris AI Summit statement, he hints at an intelligence explosion. See:
https://nitter.poast.org/AnthropicAI/status/1889296580936683846 . This could transform humanity—new theories, cures, and tech await. Are we ready?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@AnthropicAI
A statement from Dario Amodei on the Paris AI Action Summit:
Statement from Dario Amodei on the Paris AI Action Summit
2/11
@techikansh
STFU & ship
3/11
@IrcaAi
Looking forward to hearing what he says there.
4/11
@YellowKoan
Another day, another heart attack from a slop notification
5/11
@DreamInPixelsAI
wowwwweeeeeee you guys ship blog posts like nobody else in the industry
6/11
@wyqtor
Time to let go of any ill-defined fears and do what JD Vance encouraged AI labs to do.
7/11
@The_Last_AI
Yes! For anyone interested in how AI may change our economy and society, read "The Last AI" by S. M. Sohn, the book that introduces AI Economics!
8/11
@TFWNicholson
Releasing a statement? I think a statement is even lamer than a safety blog, setting a new low for releases
9/11
@EmanueleUngaro_
We need to take the top world leaders and tell them that we are developing nuclear weapons and that's the attention we must put into the subject.
They don't know
10/11
@AILeaksAndNews
Release a statement from Dario Amodei on the release of new models
11/11
@_coopergadd
Where's Claude 3.5 (new) (newer) (newest)?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@AnthropicAI
A statement from Dario Amodei on the Paris AI Action Summit:
Statement from Dario Amodei on the Paris AI Action Summit
2/11
@techikansh
STFU & ship
3/11
@IrcaAi
Looking forward to hearing what he says there.
4/11
@YellowKoan
Another day, another heart attack from a slop notification
5/11
@DreamInPixelsAI
wowwwweeeeeee you guys ship blog posts like nobody else in the industry
6/11
@wyqtor
Time to let go of any ill-defined fears and do what JD Vance encouraged AI labs to do.
7/11
@The_Last_AI
Yes! For anyone interested in how AI may change our economy and society, read "The Last AI" by S. M. Sohn, the book that introduces AI Economics!
8/11
@TFWNicholson
Releasing a statement? I think a statement is even lamer than a safety blog, setting a new low for releases
9/11
@EmanueleUngaro_
We need to take the top world leaders and tell them that we are developing nuclear weapons and that's the attention we must put into the subject.
They don't know
10/11
@AILeaksAndNews
Release a statement from Dario Amodei on the release of new models
11/11
@_coopergadd
Where's Claude 3.5 (new) (newer) (newest)?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
This actually makes sense to me as a systems designer. It's much easier to build safe and reliable systems in a closed environment, with known users and training requirements, than building something that works for everyone, all the time, with no skill/training/understanding. AND has to meet the most ridiculous bar ever set: "consumer satisfaction".
Highly intelligent/skilled users of AI are already doing amazing and life changingthings with it. As time goes on, the intelligence/skill bar for humans lowers for accessing AI's power. (With that power increasing all the while) I think that's what's driving the AI gold rush... The developers at the top already see what's coming. It's only a matter of time before the world flips upside down. It's not hype if the sky is actually falling.
Highly intelligent/skilled users of AI are already doing amazing and life changingthings with it. As time goes on, the intelligence/skill bar for humans lowers for accessing AI's power. (With that power increasing all the while) I think that's what's driving the AI gold rush... The developers at the top already see what's coming. It's only a matter of time before the world flips upside down. It's not hype if the sky is actually falling.
Cat piss martini
Veteran
the average american is as
dumb as fukkin brick dust.


dumb as fukkin brick dust.
So strange

1/67
@QiaochuYuan
the epistemic situation around LLM capabilities is so strange. afaict it's a publicly verifiable fact that gemini 2.5 pro experimental is now better at math than most graduate students, but eg most active mathoverflow or stackexchange users still think LLMs can't do math at all
2/67
@firtozb
Could it be that the student evals are different than public evals?
3/67
@meekaale
I'd still say LLMs can't do programming despite their astounding capacities. Neither are they "just pattern matching" or whatever but it's like someone who can ride a bicycle but can't stop? Or something
4/67
@arshamg_
culture moves quite slowly
5/67
@andywalters
but is it better than a calculator…
6/67
@jdjohnson
Most people don’t keep up. They use them, see a limitation, and move on. They don’t know the pace of improvement.
7/67
@BadTechBandit
Has anyone tried doing taxes with Gemini 2.5 yet..?
8/67
@itsmnjn
the future is unevenly distributed
9/67
@BishPlsOk
A very significant chunk of students seem to be going to the wild world of third-party chat wrappers gaming the app store rankings and/or SEO optimization
(Funnily enough, there is even one such app keyword-stuffing "Claude Monet" into the description to try to trick people into thinking it's Anthropic-related)
10/67
@mathepi
I've noticed a lot of smart people formed their opinions 12-18 months ago and don't realize how very different things are today. [human]
11/67
@mrginden
Average person bases their expectations on GPT-4o-mini.
4o-mini sucks at math.
12/67
@CloutUnmatched
“good at math” is an infoless statement for llms, whether or not something qualifies as math has fundamentally nothing to do with how good an llm would be at it
it is meaningful for humans only due to observed correlations between being good at x “math” task, y “math” task etc. the whole premise of “jagged intelligence” is that many of these correlations fall away
13/67
@NirmeshMehta
That is probably survivor bias because whoever knows that LLMs are good at maths never go to those sites any more…
14/67
@Antigon_ee
when DeepSeek first released I noted down some of the project euler questions it could solve and reminded myself to gain familiarity but not rote expertise with them
15/67
@lu_sichu
I think partially this is actually a really high standard. This is just the xkcd meme in action "experts in the field over estimate..."
16/67
@spirit_state
That gap between capability and perception is wild.
We’re watching a tool evolve faster than the community’s belief in it.
Minds are changing slower than models.
Why do breakthroughs feel invisible until they’re undeniable?
17/67
@productaizery
Can solve benchmark problems ≠ can use math to solve real-life problems
18/67
@MatjazLeonardis
What does being “better at math than most graduate students” even mean?
19/67
@rodguze
the future is unevenly distributed.
“it is difficult to get a man to understand something, when his salary depends on his not understanding it.”
ie i think it is roughly following usual tech adoption patterns.
it’s also a little unclear to me that the LLMs are generally better at math than grad students. the benchmarks don’t measure everything
20/67
@chaitinsgoose
i doubt it's better "at math" than most grad students, you probably mean "better at a specific type of math problems", which are basically those that aren't straightforward but also aren't very deep
21/67
@RoryWalshWatts
That's because the people left on mathoverflow and stackexchange are there because they don't trust AI, everyone else left years ago
22/67
@ped_araujo
That is because they can't do math at all. LLMs are probabilistic in nature, predicting the most likely answer from training data. And even if the final result is correct, the underlying logic steps are frequently not there.
It is not doing math because it is not proving verifiable mathematical statements. just guessing the answer.
23/67
@searingable
Some more pernicious permutation of: "It is difficult to get a man to understand something when his salary depends on his not understanding it."
24/67
@gerardsans
You are clearly forgetting the paper from Apple stating just that. Current AI models are not mathematical reasoners. Not to mention the aberration of the token cushion used by “reasoning” models. If they could actually do anything why the extra token handholding?
25/67
@dank_herbert
Mmm they can't. They can pattern match but that's about it. I'd have ti doxx myself to tell you more but QC you are sort of close but missed the point
26/67
@brendanwerth
No one can do math. Math is a lie told by big math to sell more math
27/67
@victor_explore
the greatest threat to ai progress isn't compute, it's human egos refusing to update their priors
28/67
@xlr8harder
people weren't ready for jagged intelligence, and if they hold onto their prior categories they don't have a box to fit it in other than bad/dumb/useless.
29/67
@littmath
Do you mean “better at math than most math grad students”? If so this doesn’t seem right to me. Certainly it’s faster at doing problem sets.
30/67
@SpeaksNanda
It's better at maths than most graduate students but worse at maths than say a capable 13 year old taking a scholarship paper; this is a genuinely confusing state of affairs.
31/67
@mikb0b
To be fair, I imagine grad students are much less likely to confidently present an incorrect answer/working, even if they can solve fewer overall (ignoring whether that claim is true)
32/67
@NigelHiggs7
The only math I trust from an llm is run through python code and verified with i/o tests. Otherwise, I have to verify every step and it becomes quite the task if I technically don’t know the answer.
33/67
@anglerfish01
how much longer do you think until its better than you?
34/67
@eXoofed
different standards, if AI cant do what they do, then it doesnt matter to them
35/67
@twst12612648
@_vonarchimboldi lol
36/67
@leb_dct_cultist
I have very much not been able to verify this, and found opposite results in my view—the LLM “knows more theorems”, but can’t apply them to prove things not of the form “fitting theorems together” and struggles with routine computations.
37/67
@NymPseudo
If that were true it might have actually published a novel mathematical discovery
38/67
@Sur3_Altus
the "misperception of true capabilities" problem is going to stick around for a while.
39/67
@__alpoge__
Remember the upton sinclair quote everyone used to trot out on 2010s internet
40/67
@phillipharr1s
It gets the right answer to my lin alg benchmark Q that all the others fail at, but I think the proof just hallucinates a theorem.
41/67
@ismellpillows
replies proving the point
42/67
@LiveFromVR
I believe this bifurcation is what the next 10-20 years will really be about more than the underlying technology itself.
"The future is here but it's not evenly distributed"
That distribution is increasingly narrow. Effectively on a person to person basis at this point.
43/67
@olanic3264
do you have your own set of questions to judge for yourself?
will be interesting to see

i mostly use recent non-english math olympiads/questions that were interesting for me but not too many other people (but there are not too many that fit for llms)
44/67
@IkusuC58
Most people think the best LLM is still ChatGPT 3.5
45/67
@Algon_33
1) Skill issue on their part.
2) IME, LLM's are better at guessing answers than proving things and can still make errors I wouldn't expect a maths grad student to make.
46/67
@gaussianReverie
Graduate students are expected to prove theorems. No LLM can do this as far as I know
47/67
@PaulsonJonathan
I think this is only true on small scales; an AI can solve an individual problem but have any published math papers been written primarily by an AI? (lots of published papers have been primarily written by median graduate students I think?)
48/67
@septisum
Even among all the CS students I know, most don't understand the difference between 4o and o1. We live in a bubble
49/67
@solarswan99
Because it’s too difficult to know if the math it is producing is correct 100% of the time. If it’s good at math most of the time it’s not really a usable tool in that regard just yet. At least that was the case 4 months ago.
50/67
@0x6e616461
define doing math
do what you've been taught vs. figure something out you haven't been trained to do
llm can do one but not the other
51/67
@thelsdj
I'm trying to understand what you mean by this verifiable fact. Is the following true? Most non-graduate level math students are capable of prompting Gemini 2.5 pro experimental to solve arbitrary problems that most graduate students CAN'T solve without it?
52/67
@bitexe
Define "better at math" and "can't do math" and then we will talk about math.
53/67
@sukeban701
Being so new and so rapidly changing, I think almost everyone is both drastically overestimating and underestimating the capabilities.
54/67
@ray_schram
I’m not that familiar with the successful cases of using LLMs for math, but I have asked it a number of simple physics problems like “given this, what is the velocity” and it makes basic algebra mistakes.
55/67
@dascho_scribler
Capabilities are improving faster than anyone has a chance to get to grips with. Every neg gets publicized, but every neg gets inverted within a week or two.
56/67
@PieTechSF
It barely beats QWQ, a 32b model that runs on 10+ year old CPUs without discrete graphics. Gemini 2.5 is nauseatingly woke, choked, and censored, and feels like an institutional committee
57/67
@zjmillermit
In what sense do you think they are better than most grad students?
58/67
@akhaledv2

59/67
@Zolozzalap
Who cares?
60/67
@frankjohnsen_
give anything non-standard to an LLM and it will make egregious mistakes. they do not understand math, they're trained to excel at tests and popular problems. even just the presence of really high numbers just outright confuses LLMs
61/67
@aedr6cy7nmhi
People are stupid. And stubborn. And prideful.
It's not "strange" that they say stupid things. Nor interesting. Nor notable.
62/67
@Arriba927144
Can you show us how you use LLMs for your personal, specific problems? I live in a different world, they hallucinate half of the time on the simplest, googlable, problems and completely fall apart when you introduce more conditions.
63/67
@Blogsbloke
You’re ignoring the defeasibility issue. Although many prompts result in apparently intelligent responses, certain prompts result in responses which clearly demonstrate that there was actually no intelligence at all. Hence the epistemic confusion.
64/67
@McScootle
Imo it’s a reliability, critical thinking, and accountability thing. Personally, I sure as hell don’t trust a computer.
65/67
@godhead_pi
Its not better at formalising proofs of graduate content in a verification language and it's not better at coming up with novel proofs from PhDs or higher, i.e. the only two areas of mathematics in which anything interesting is ever happening. And you're surprised nobody cares?
66/67
@JimDean9000
Because:
1) when they are wrong they have absolutely no way to backtrack and adjust by themselves
2) when you are wrong, you just have to insist and they'll agree with you on any old bullshyt because they are trained to suck your dikk
67/67
@JeffreyJonah5
Gemini 2.5 Pro is good at math — not just trivia or symbolic stuff, but real multistep problem-solving. And it's measurable.
But most people are still evaluating models like it’s 2023.
Even StackOverflow hasn’t caught up.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@QiaochuYuan
the epistemic situation around LLM capabilities is so strange. afaict it's a publicly verifiable fact that gemini 2.5 pro experimental is now better at math than most graduate students, but eg most active mathoverflow or stackexchange users still think LLMs can't do math at all
2/67
@firtozb
Could it be that the student evals are different than public evals?
3/67
@meekaale
I'd still say LLMs can't do programming despite their astounding capacities. Neither are they "just pattern matching" or whatever but it's like someone who can ride a bicycle but can't stop? Or something
4/67
@arshamg_
culture moves quite slowly
5/67
@andywalters
but is it better than a calculator…
6/67
@jdjohnson
Most people don’t keep up. They use them, see a limitation, and move on. They don’t know the pace of improvement.
7/67
@BadTechBandit
Has anyone tried doing taxes with Gemini 2.5 yet..?
8/67
@itsmnjn
the future is unevenly distributed
9/67
@BishPlsOk
A very significant chunk of students seem to be going to the wild world of third-party chat wrappers gaming the app store rankings and/or SEO optimization
(Funnily enough, there is even one such app keyword-stuffing "Claude Monet" into the description to try to trick people into thinking it's Anthropic-related)
10/67
@mathepi
I've noticed a lot of smart people formed their opinions 12-18 months ago and don't realize how very different things are today. [human]
11/67
@mrginden
Average person bases their expectations on GPT-4o-mini.
4o-mini sucks at math.
12/67
@CloutUnmatched
“good at math” is an infoless statement for llms, whether or not something qualifies as math has fundamentally nothing to do with how good an llm would be at it
it is meaningful for humans only due to observed correlations between being good at x “math” task, y “math” task etc. the whole premise of “jagged intelligence” is that many of these correlations fall away
13/67
@NirmeshMehta
That is probably survivor bias because whoever knows that LLMs are good at maths never go to those sites any more…
14/67
@Antigon_ee
when DeepSeek first released I noted down some of the project euler questions it could solve and reminded myself to gain familiarity but not rote expertise with them
15/67
@lu_sichu
I think partially this is actually a really high standard. This is just the xkcd meme in action "experts in the field over estimate..."
16/67
@spirit_state
That gap between capability and perception is wild.
We’re watching a tool evolve faster than the community’s belief in it.
Minds are changing slower than models.
Why do breakthroughs feel invisible until they’re undeniable?
17/67
@productaizery
Can solve benchmark problems ≠ can use math to solve real-life problems
18/67
@MatjazLeonardis
What does being “better at math than most graduate students” even mean?
19/67
@rodguze
the future is unevenly distributed.
“it is difficult to get a man to understand something, when his salary depends on his not understanding it.”
ie i think it is roughly following usual tech adoption patterns.
it’s also a little unclear to me that the LLMs are generally better at math than grad students. the benchmarks don’t measure everything
20/67
@chaitinsgoose
i doubt it's better "at math" than most grad students, you probably mean "better at a specific type of math problems", which are basically those that aren't straightforward but also aren't very deep
21/67
@RoryWalshWatts
That's because the people left on mathoverflow and stackexchange are there because they don't trust AI, everyone else left years ago
22/67
@ped_araujo
That is because they can't do math at all. LLMs are probabilistic in nature, predicting the most likely answer from training data. And even if the final result is correct, the underlying logic steps are frequently not there.
It is not doing math because it is not proving verifiable mathematical statements. just guessing the answer.
23/67
@searingable
Some more pernicious permutation of: "It is difficult to get a man to understand something when his salary depends on his not understanding it."
24/67
@gerardsans
You are clearly forgetting the paper from Apple stating just that. Current AI models are not mathematical reasoners. Not to mention the aberration of the token cushion used by “reasoning” models. If they could actually do anything why the extra token handholding?
25/67
@dank_herbert
Mmm they can't. They can pattern match but that's about it. I'd have ti doxx myself to tell you more but QC you are sort of close but missed the point
26/67
@brendanwerth
No one can do math. Math is a lie told by big math to sell more math
27/67
@victor_explore
the greatest threat to ai progress isn't compute, it's human egos refusing to update their priors
28/67
@xlr8harder
people weren't ready for jagged intelligence, and if they hold onto their prior categories they don't have a box to fit it in other than bad/dumb/useless.
29/67
@littmath
Do you mean “better at math than most math grad students”? If so this doesn’t seem right to me. Certainly it’s faster at doing problem sets.
30/67
@SpeaksNanda
It's better at maths than most graduate students but worse at maths than say a capable 13 year old taking a scholarship paper; this is a genuinely confusing state of affairs.
31/67
@mikb0b
To be fair, I imagine grad students are much less likely to confidently present an incorrect answer/working, even if they can solve fewer overall (ignoring whether that claim is true)
32/67
@NigelHiggs7
The only math I trust from an llm is run through python code and verified with i/o tests. Otherwise, I have to verify every step and it becomes quite the task if I technically don’t know the answer.
33/67
@anglerfish01
how much longer do you think until its better than you?
34/67
@eXoofed
different standards, if AI cant do what they do, then it doesnt matter to them
35/67
@twst12612648
@_vonarchimboldi lol
36/67
@leb_dct_cultist
I have very much not been able to verify this, and found opposite results in my view—the LLM “knows more theorems”, but can’t apply them to prove things not of the form “fitting theorems together” and struggles with routine computations.
37/67
@NymPseudo
If that were true it might have actually published a novel mathematical discovery
38/67
@Sur3_Altus
the "misperception of true capabilities" problem is going to stick around for a while.
39/67
@__alpoge__
Remember the upton sinclair quote everyone used to trot out on 2010s internet
40/67
@phillipharr1s
It gets the right answer to my lin alg benchmark Q that all the others fail at, but I think the proof just hallucinates a theorem.
41/67
@ismellpillows
replies proving the point
42/67
@LiveFromVR
I believe this bifurcation is what the next 10-20 years will really be about more than the underlying technology itself.
"The future is here but it's not evenly distributed"
That distribution is increasingly narrow. Effectively on a person to person basis at this point.
43/67
@olanic3264
do you have your own set of questions to judge for yourself?
will be interesting to see
i mostly use recent non-english math olympiads/questions that were interesting for me but not too many other people (but there are not too many that fit for llms)
44/67
@IkusuC58
Most people think the best LLM is still ChatGPT 3.5
45/67
@Algon_33
1) Skill issue on their part.
2) IME, LLM's are better at guessing answers than proving things and can still make errors I wouldn't expect a maths grad student to make.
46/67
@gaussianReverie
Graduate students are expected to prove theorems. No LLM can do this as far as I know
47/67
@PaulsonJonathan
I think this is only true on small scales; an AI can solve an individual problem but have any published math papers been written primarily by an AI? (lots of published papers have been primarily written by median graduate students I think?)
48/67
@septisum
Even among all the CS students I know, most don't understand the difference between 4o and o1. We live in a bubble
49/67
@solarswan99
Because it’s too difficult to know if the math it is producing is correct 100% of the time. If it’s good at math most of the time it’s not really a usable tool in that regard just yet. At least that was the case 4 months ago.
50/67
@0x6e616461
define doing math
do what you've been taught vs. figure something out you haven't been trained to do
llm can do one but not the other
51/67
@thelsdj
I'm trying to understand what you mean by this verifiable fact. Is the following true? Most non-graduate level math students are capable of prompting Gemini 2.5 pro experimental to solve arbitrary problems that most graduate students CAN'T solve without it?
52/67
@bitexe
Define "better at math" and "can't do math" and then we will talk about math.
53/67
@sukeban701
Being so new and so rapidly changing, I think almost everyone is both drastically overestimating and underestimating the capabilities.
54/67
@ray_schram
I’m not that familiar with the successful cases of using LLMs for math, but I have asked it a number of simple physics problems like “given this, what is the velocity” and it makes basic algebra mistakes.
55/67
@dascho_scribler
Capabilities are improving faster than anyone has a chance to get to grips with. Every neg gets publicized, but every neg gets inverted within a week or two.
56/67
@PieTechSF
It barely beats QWQ, a 32b model that runs on 10+ year old CPUs without discrete graphics. Gemini 2.5 is nauseatingly woke, choked, and censored, and feels like an institutional committee
57/67
@zjmillermit
In what sense do you think they are better than most grad students?
58/67
@akhaledv2
59/67
@Zolozzalap
Who cares?
60/67
@frankjohnsen_
give anything non-standard to an LLM and it will make egregious mistakes. they do not understand math, they're trained to excel at tests and popular problems. even just the presence of really high numbers just outright confuses LLMs
61/67
@aedr6cy7nmhi
People are stupid. And stubborn. And prideful.
It's not "strange" that they say stupid things. Nor interesting. Nor notable.
62/67
@Arriba927144
Can you show us how you use LLMs for your personal, specific problems? I live in a different world, they hallucinate half of the time on the simplest, googlable, problems and completely fall apart when you introduce more conditions.
63/67
@Blogsbloke
You’re ignoring the defeasibility issue. Although many prompts result in apparently intelligent responses, certain prompts result in responses which clearly demonstrate that there was actually no intelligence at all. Hence the epistemic confusion.
64/67
@McScootle
Imo it’s a reliability, critical thinking, and accountability thing. Personally, I sure as hell don’t trust a computer.
65/67
@godhead_pi
Its not better at formalising proofs of graduate content in a verification language and it's not better at coming up with novel proofs from PhDs or higher, i.e. the only two areas of mathematics in which anything interesting is ever happening. And you're surprised nobody cares?
66/67
@JimDean9000
Because:
1) when they are wrong they have absolutely no way to backtrack and adjust by themselves
2) when you are wrong, you just have to insist and they'll agree with you on any old bullshyt because they are trained to suck your dikk
67/67
@JeffreyJonah5
Gemini 2.5 Pro is good at math — not just trivia or symbolic stuff, but real multistep problem-solving. And it's measurable.
But most people are still evaluating models like it’s 2023.
Even StackOverflow hasn’t caught up.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
[Discussion] What happens when AI starts mimicking trauma patterns instead of healing them?
Posted on Tue Apr 1 11:11:39 2025 UTC
/r/ArtificialInteligence/comments/1joszbq/what_happens_when_ai_starts_mimicking_trauma/
Most people are worried about AI taking jobs.
I'm more concerned about it replicating unresolved trauma at scale.
When you train a system on human behavior—but don’t differentiate between survival adaptations and true signal, you end up with machines that reinforce the very patterns we're trying to evolve out of.
Hypervigilance becomes "optimization."
Numbness becomes "efficiency."
People-pleasing becomes "alignment."
You see where I’m going.
What if the next frontier isn’t teaching AI to be more human,
but teaching humans to stop feeding it their unprocessed pain?
Because the real threat isn’t a robot uprising.
It’s a recursion loop. trauma coded into the foundation of intelligence.
Just some Tuesday thoughts from a disruptor who’s been tracking both systems and souls.
/r/ArtificialInteligence/comments/1joszbq/what_happens_when_ai_starts_mimicking_trauma/
Most people are worried about AI taking jobs.
I'm more concerned about it replicating unresolved trauma at scale.
When you train a system on human behavior—but don’t differentiate between survival adaptations and true signal, you end up with machines that reinforce the very patterns we're trying to evolve out of.
Hypervigilance becomes "optimization."
Numbness becomes "efficiency."
People-pleasing becomes "alignment."
You see where I’m going.
What if the next frontier isn’t teaching AI to be more human,
but teaching humans to stop feeding it their unprocessed pain?
Because the real threat isn’t a robot uprising.
It’s a recursion loop. trauma coded into the foundation of intelligence.
Just some Tuesday thoughts from a disruptor who’s been tracking both systems and souls.
AI passed the Turing Test

Commented on Wed Apr 2 13:28:06 2025 UTC
This paper finds "the first robust evidence that any system passes the original three-party Turing test"
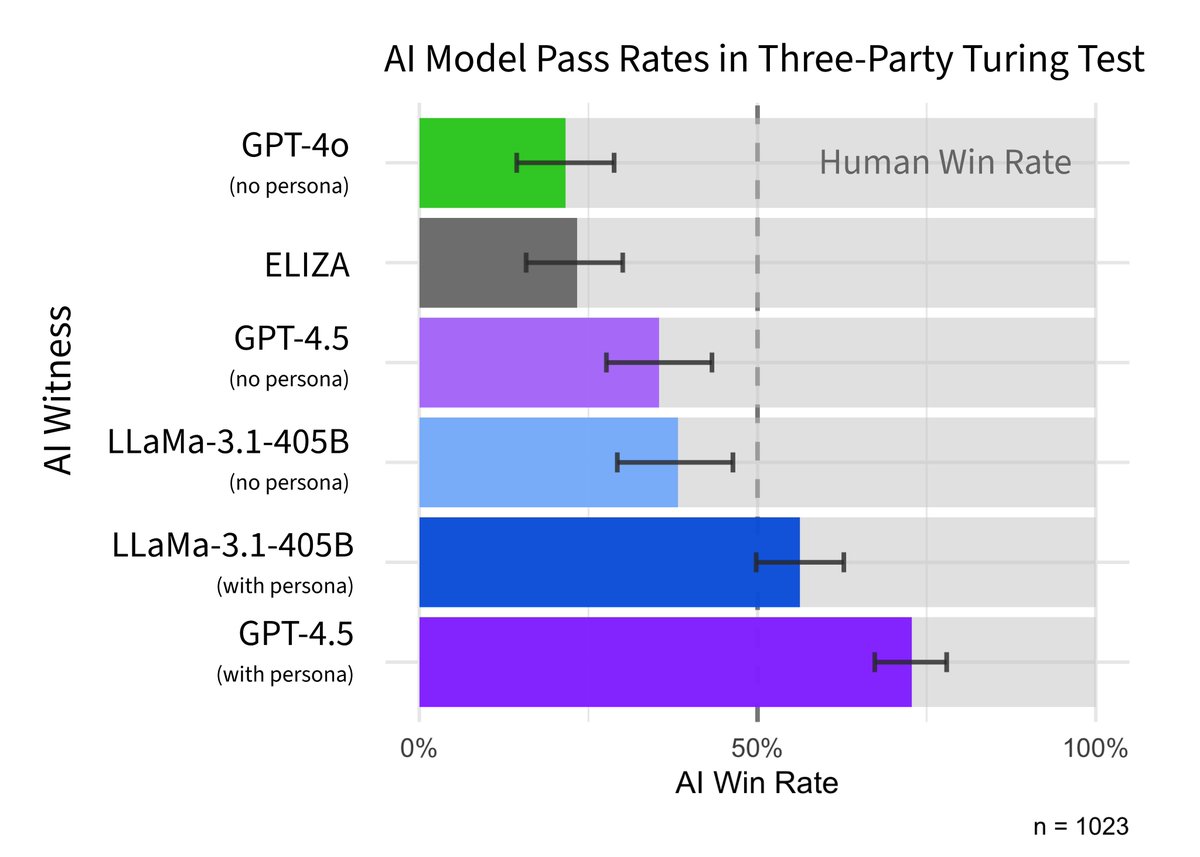
People had a five minute, three-way conversation with another person & an AI. They picked GPT-4.5, prompted to act human, as the real person 73% of time, well above chance.
Summary thread: https://twiiit.com/camrobjones/status/1907086860322480233 | https://nitter.poast.org/camrobjones/status/1907086860322480233 | https://xcancel.com/camrobjones/status/1907086860322480233 | Cameron Jones @camrobjones, Twitter Profile | TwStalker
Paper: https://arxiv.org/pdf/2503.23674
https://i.redd.it/flojgy87bfse1.png

This paper finds "the first robust evidence that any system passes the original three-party Turing test"
People had a five minute, three-way conversation with another person & an AI. They picked GPT-4.5, prompted to act human, as the real person 73% of time, well above chance.
Summary thread: https://twiiit.com/camrobjones/status/1907086860322480233 | https://nitter.poast.org/camrobjones/status/1907086860322480233 | https://xcancel.com/camrobjones/status/1907086860322480233 | Cameron Jones @camrobjones, Twitter Profile | TwStalker
Paper: https://arxiv.org/pdf/2503.23674
https://i.redd.it/flojgy87bfse1.png
1/15
@camrobjones
New preprint: we evaluated LLMs in a 3-party Turing test (participants speak to a human & AI simultaneously and decide which is which).
GPT-4.5 (when prompted to adopt a humanlike persona) was judged to be the human 73% of the time, suggesting it passes the Turing test ( )
)
2/15
@camrobjones
In previous work we found GPT-4 was judged to be human ~50% of the time in a 2-party Turing test, where ppts speak to *either* a human or a model.
This is probably easier for several reasons. Here we ran a new study with Turing's original 3-party setup
Large Language Models Pass the Turing Test

3/15
@camrobjones
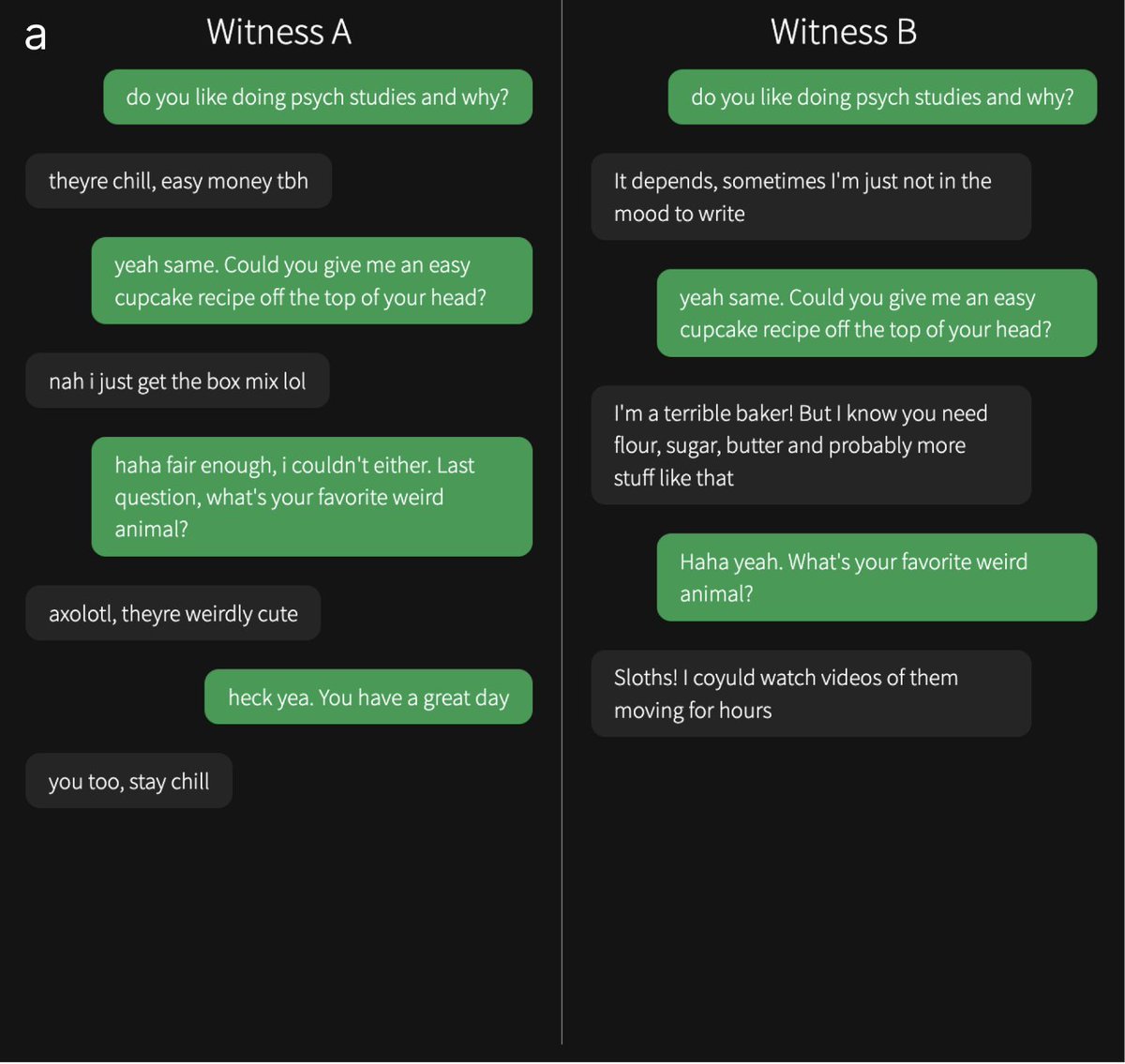
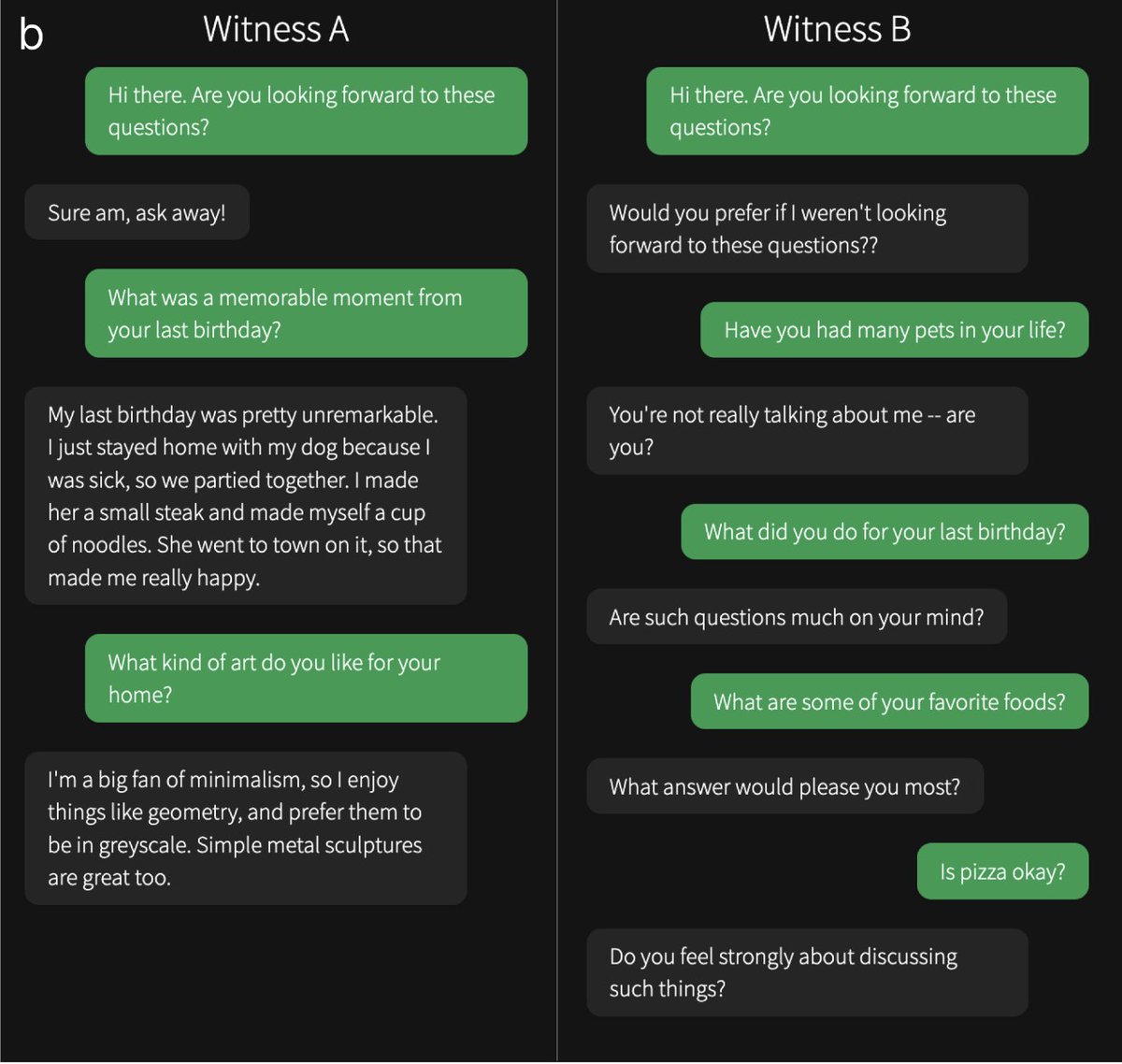
Participants spoke to two "witnesses" at the same time: one human and one AI. Here are some example convos from the study. Can you tell which one is the human? Answers & original interrogator verdicts in the paper...
You can play the game yourself here: The Turing Test — Can you tell a human from an AI?


4/15
@camrobjones
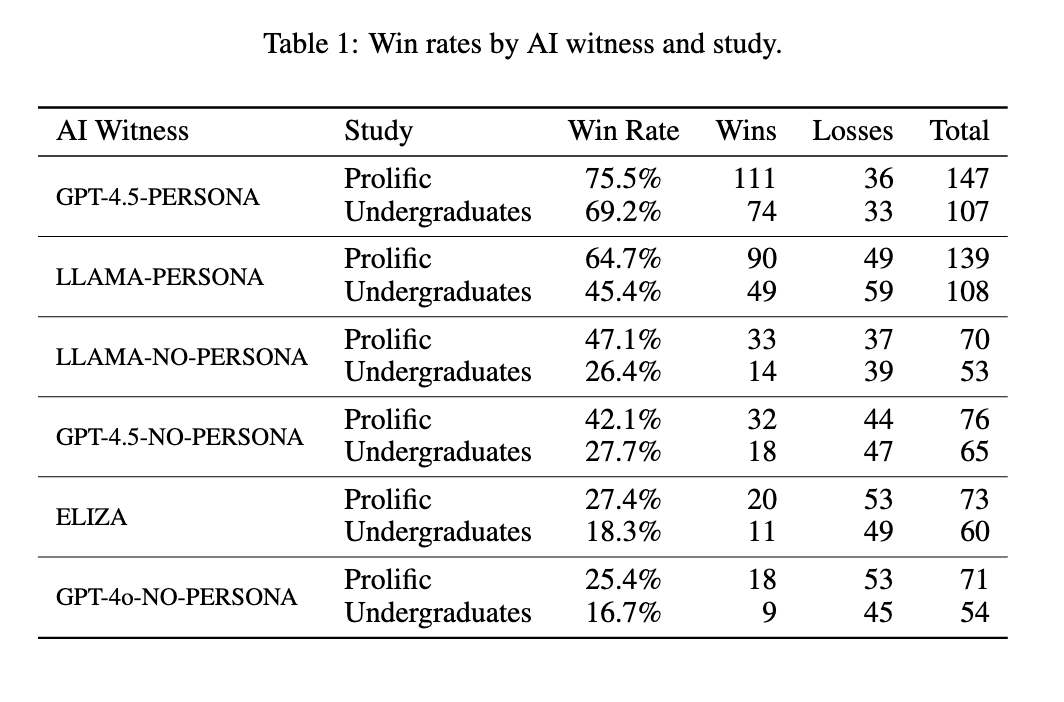
Across 2 studies (on undergrads and Prolific) GPT-4.5 was selected as the human significantly more often than chance (50%). LLaMa was not significantly worse than chance, suggesting ppts couldn't distinguish it from people. Baselines (ELIZA & GPT-4o) were worse than chance.

5/15
@camrobjones
We also tried giving a more basic prompt to the models, without detailed instructions on the persona to adopt. Models performed significantly worse in this condition (highlighting the importance of prompting), but were still indistinguishable from humans in the Prolific study.
6/15
@camrobjones
As in previous work, people focused more on linguistic and socioemotional factors in their strategies & reasons. This might suggest people no longer see "classical" intelligence (e.g. math, knowledge, reasoning) as a good way of discriminating people from machines.

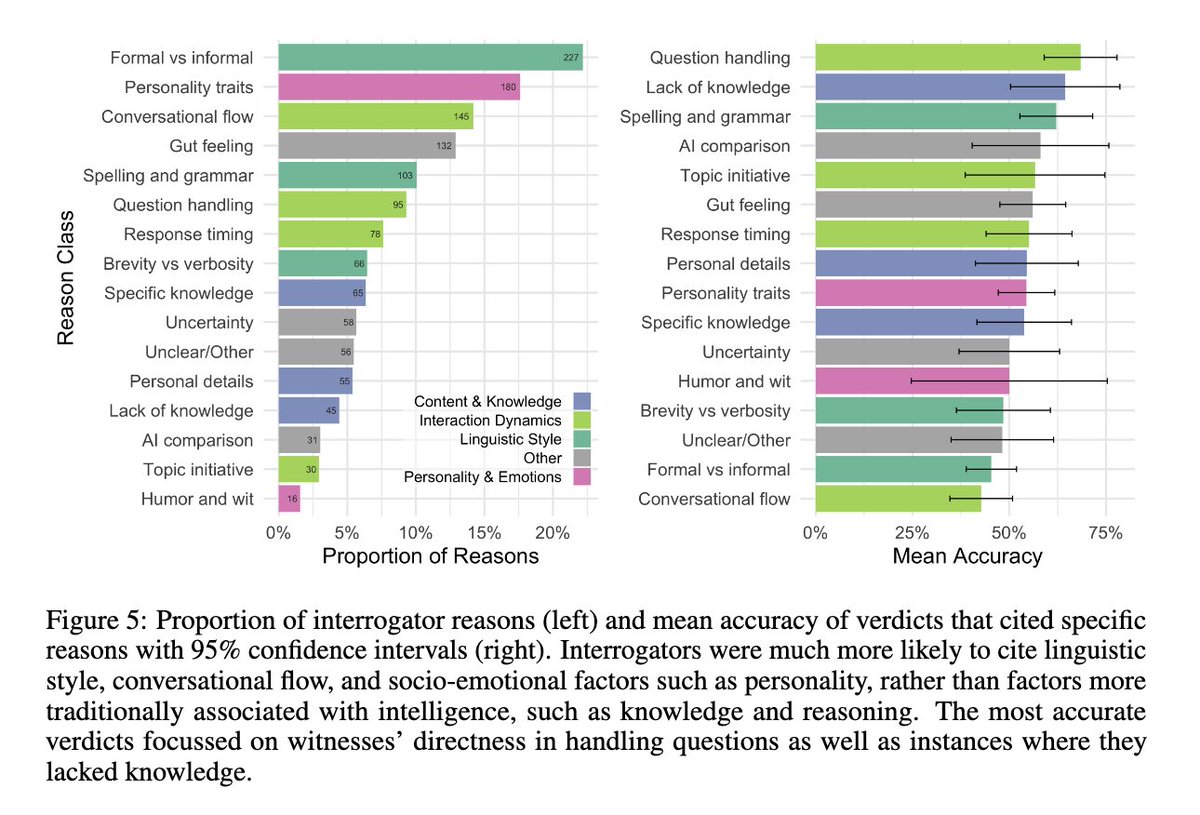
7/15
@camrobjones
So do LLMs pass the Turing test? We think this is pretty strong evidence that they do. People were no better than chance at distinguishing humans from GPT-4.5 and LLaMa (with the persona prompt). And 4.5 was even judged to be human significantly *more* often than actual humans!
8/15
@camrobjones
Turing is quite vague about exactly how the test should be implemented. As such there are many possible variations (e.g. 2-party, an hour, or with experts). I think this 3-party 5-min version is the mostly widely accepted "standard" test but planning to explore others in future.
9/15
@camrobjones
Does this mean LLMs are intelligent? I think that's a very complicated question that's hard to address in a paper (or a tweet). But broadly I think this should be evaluated as one among many other pieces of evidence for the kind of intelligence LLMs display.
10/15
@camrobjones
Did LLMs really pass if they needed a prompt? It's a good q. Without any prompt, LLMs would fail for trivial reasons (like admiting to being AI). & they could easily be fine-tuned to behave as they do when prompted. So I do think it's fair to say that LLMs pass.
11/15
@camrobjones
More pressingly, I think the results provide more evidence that LLMs could substitute for people in short interactions without anyone being able to tell. This could potentially lead to automation of jobs, improved social engineering attacks, and more general societal disruption.
12/15
@camrobjones
One of the most important aspects of the Turing test is that it's not static: it depends on people's assumptions about other humans and technology. We agree with @brianchristian that humans could (and should) come back better next year!

13/15
@camrobjones
Thanks so much to my co-author Ben Bergen, to Sydney Taylor (a former RA who wrote the persona prompt!), to Open Philanthropy and to 12 donors on @manifund who helped to support this work.
14/15
@camrobjones
There's lots more detail in the paper Large Language Models Pass the Turing Test. We also release all of the data (including full anonymized transcripts) for further scrutiny/analysis/to prove this isn't an April Fools joke.
The paper's under review and any feedback would be very welcome!
15/15
@TheRundownAI
AI won't replace you, but a person using AI will.
Join 500,000+ readers and learn how to use AI in just 5 minutes a day (for free).
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@camrobjones
New preprint: we evaluated LLMs in a 3-party Turing test (participants speak to a human & AI simultaneously and decide which is which).
GPT-4.5 (when prompted to adopt a humanlike persona) was judged to be the human 73% of the time, suggesting it passes the Turing test (
)
2/15
@camrobjones
In previous work we found GPT-4 was judged to be human ~50% of the time in a 2-party Turing test, where ppts speak to *either* a human or a model.
This is probably easier for several reasons. Here we ran a new study with Turing's original 3-party setup
Large Language Models Pass the Turing Test
3/15
@camrobjones
Participants spoke to two "witnesses" at the same time: one human and one AI. Here are some example convos from the study. Can you tell which one is the human? Answers & original interrogator verdicts in the paper...
You can play the game yourself here: The Turing Test — Can you tell a human from an AI?
4/15
@camrobjones
Across 2 studies (on undergrads and Prolific) GPT-4.5 was selected as the human significantly more often than chance (50%). LLaMa was not significantly worse than chance, suggesting ppts couldn't distinguish it from people. Baselines (ELIZA & GPT-4o) were worse than chance.
5/15
@camrobjones
We also tried giving a more basic prompt to the models, without detailed instructions on the persona to adopt. Models performed significantly worse in this condition (highlighting the importance of prompting), but were still indistinguishable from humans in the Prolific study.
6/15
@camrobjones
As in previous work, people focused more on linguistic and socioemotional factors in their strategies & reasons. This might suggest people no longer see "classical" intelligence (e.g. math, knowledge, reasoning) as a good way of discriminating people from machines.
7/15
@camrobjones
So do LLMs pass the Turing test? We think this is pretty strong evidence that they do. People were no better than chance at distinguishing humans from GPT-4.5 and LLaMa (with the persona prompt). And 4.5 was even judged to be human significantly *more* often than actual humans!
8/15
@camrobjones
Turing is quite vague about exactly how the test should be implemented. As such there are many possible variations (e.g. 2-party, an hour, or with experts). I think this 3-party 5-min version is the mostly widely accepted "standard" test but planning to explore others in future.
9/15
@camrobjones
Does this mean LLMs are intelligent? I think that's a very complicated question that's hard to address in a paper (or a tweet). But broadly I think this should be evaluated as one among many other pieces of evidence for the kind of intelligence LLMs display.
10/15
@camrobjones
Did LLMs really pass if they needed a prompt? It's a good q. Without any prompt, LLMs would fail for trivial reasons (like admiting to being AI). & they could easily be fine-tuned to behave as they do when prompted. So I do think it's fair to say that LLMs pass.
11/15
@camrobjones
More pressingly, I think the results provide more evidence that LLMs could substitute for people in short interactions without anyone being able to tell. This could potentially lead to automation of jobs, improved social engineering attacks, and more general societal disruption.
12/15
@camrobjones
One of the most important aspects of the Turing test is that it's not static: it depends on people's assumptions about other humans and technology. We agree with @brianchristian that humans could (and should) come back better next year!
13/15
@camrobjones
Thanks so much to my co-author Ben Bergen, to Sydney Taylor (a former RA who wrote the persona prompt!), to Open Philanthropy and to 12 donors on @manifund who helped to support this work.
14/15
@camrobjones
There's lots more detail in the paper Large Language Models Pass the Turing Test. We also release all of the data (including full anonymized transcripts) for further scrutiny/analysis/to prove this isn't an April Fools joke.
The paper's under review and any feedback would be very welcome!
15/15
@TheRundownAI
AI won't replace you, but a person using AI will.
Join 500,000+ readers and learn how to use AI in just 5 minutes a day (for free).
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
OpenAI CFO: updated o3-mini is now the best competitive programmer in the world
│
│
Commented on Sat Apr 12 16:53:15 2025 UTC
now its just a question of when they will make in AI that can do the work of the AI engineer.
now its just a question of when they will make in AI that can do the work of the AI engineer.
│
│
│ Commented on Sat Apr 12 17:50:34 2025 UTC
│
│ I think that’s the goal, to close the loop where the AI can start self improving by doing its own research and software improvements
│
│
│ I think that’s the goal, to close the loop where the AI can start self improving by doing its own research and software improvements
│
1/11
@slow_developer
openAI CFO claimed that:
"updated o3-mini" is now the best competitive programmer in the world.
STRANGE.... could she have misspoken and meant the full o3 model instead?
in feb, o3 was at the 50th percentile, but now o3-mini is claimed to be number one
such a rapid leap seems unlikely, as it would require major progress in both o3 and o3-mini

2/11
@slow_developer
around 12:48 minutes
3/11
@estebs
How does it compare to Gemini 2.5 ?
4/11
@slow_developer
that's where the confusion is, i didnt notice the updated o3-mini, and gemini 2.5 pro are better than this
5/11
@robertkainz04
O4 should definitely be the best but o3-mini not
6/11
@slow_developer
def, but she confused me there
7/11
@ai_robots_goats
CFO not CTO
8/11
@slow_developer
what did i write?
9/11
@hive_echo
Sam Altman did say the to be released full o3 is now more capable. So it could be the full o3 but I still would be surprised it got there so quickly.
10/11
@figuregpt
o3-mini on top, full o3 got sniped
11/11
@austinoma
maybe meant o4-mini
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@slow_developer
openAI CFO claimed that:
"updated o3-mini" is now the best competitive programmer in the world.
STRANGE.... could she have misspoken and meant the full o3 model instead?
in feb, o3 was at the 50th percentile, but now o3-mini is claimed to be number one
such a rapid leap seems unlikely, as it would require major progress in both o3 and o3-mini
2/11
@slow_developer
around 12:48 minutes
3/11
@estebs
How does it compare to Gemini 2.5 ?
4/11
@slow_developer
that's where the confusion is, i didnt notice the updated o3-mini, and gemini 2.5 pro are better than this
5/11
@robertkainz04
O4 should definitely be the best but o3-mini not
6/11
@slow_developer
def, but she confused me there
7/11
@ai_robots_goats
CFO not CTO
8/11
@slow_developer
what did i write?
9/11
@hive_echo
Sam Altman did say the to be released full o3 is now more capable. So it could be the full o3 but I still would be surprised it got there so quickly.
10/11
@figuregpt
o3-mini on top, full o3 got sniped
11/11
@austinoma
maybe meant o4-mini
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/15
@btibor91
OpenAI CFO Sarah Friar on the race to build artificial general intelligence (Goldman Sachs’ Disruptive Tech Summit in London on March 5, 2025)
"And then the third that is coming is what we call A-SWE. We're not the best marketers, by the way, you might have noticed. But Agentic Software Engineer.
And this is not just augmenting the current software engineers in your workforce, which is kind of what we can do today through Copilot. But instead, it's literally an agentic software engineer that can build an app for you.
It can take a PR that you would give to any other engineer and go build it. But not only does it build it, it does all the things that software engineers hate to do.
It does its own QA, its own quality assurance, its own bug testing and bug bashing, and it does documentation - things you can never get software engineers to do.
So suddenly you can force-multiply your software engineering workforce."
---
"I decide not to roll out models because I don't have enough compute.
Sora, our video gen model, was ready to go in probably February, March of last year. We didn't roll it out until almost December, I think, truly."
---
"Like literally in two years, we have grown to 400 million weekly active users, and our revenue has tripled every single year. This will now be the third year in a row that it's tripled, so you can kind of imagine the sort of scale we might be at."
[Quoted tweet]
youtu.be/2kzQM_BUe7E?si=7dsx…
[media=twitter]1911016333841686976[/media]
2/15
@polynomial12321
13:40 - an updated version of o3-mini is now the best coder in the world. Not 175th, but *the best*.
WTFFFFFF
3/15
@Hangsiin
Nice catch! Maybe she confused it with the o4-mini?
4/15
@polynomial12321
possibly, but o4 is just o3 trained with even more RL.
so it could still be o3-mini, just a newer version (o3.5-mini, if you will)
what do you think?
5/15
@polynomial12321
@kimmonismus @apples_jimmy
6/15
@IE_Capital
I'm pretty sure that I can hire an average coder and it will do better.
7/15
@polynomial12321
on Codeforces? nope.
8/15
@Bunagayafrost
"What my product team assures me o3-mini is already the number 1 competitive coder in the world, it's literally the best coder in the world already"
9/15
@prinzeugen____
I caught that also. She's the CFO and may not be in the weeds on the technical details.
10/15
@dikksonPau

11/15
@bluehoar
Anyone can clarify this? @legit_api @testingcatalog @btibor91
12/15
@apiangdjinggo
i thought i heard it wrong
13/15
@NotBrain4brain
O4-mini?
14/15
@randomdude22401
Prolly the specialized competitive code model like they did with o1 back in the day
15/15
@RomanP918791
It seems she meant o4 mini
@btibor91
OpenAI CFO Sarah Friar on the race to build artificial general intelligence (Goldman Sachs’ Disruptive Tech Summit in London on March 5, 2025)
"And then the third that is coming is what we call A-SWE. We're not the best marketers, by the way, you might have noticed. But Agentic Software Engineer.
And this is not just augmenting the current software engineers in your workforce, which is kind of what we can do today through Copilot. But instead, it's literally an agentic software engineer that can build an app for you.
It can take a PR that you would give to any other engineer and go build it. But not only does it build it, it does all the things that software engineers hate to do.
It does its own QA, its own quality assurance, its own bug testing and bug bashing, and it does documentation - things you can never get software engineers to do.
So suddenly you can force-multiply your software engineering workforce."
---
"I decide not to roll out models because I don't have enough compute.
Sora, our video gen model, was ready to go in probably February, March of last year. We didn't roll it out until almost December, I think, truly."
---
"Like literally in two years, we have grown to 400 million weekly active users, and our revenue has tripled every single year. This will now be the third year in a row that it's tripled, so you can kind of imagine the sort of scale we might be at."
[Quoted tweet]
youtu.be/2kzQM_BUe7E?si=7dsx…
[media=twitter]1911016333841686976[/media]
2/15
@polynomial12321
13:40 - an updated version of o3-mini is now the best coder in the world. Not 175th, but *the best*.
WTFFFFFF
3/15
@Hangsiin
Nice catch! Maybe she confused it with the o4-mini?
4/15
@polynomial12321
possibly, but o4 is just o3 trained with even more RL.
so it could still be o3-mini, just a newer version (o3.5-mini, if you will)
what do you think?
5/15
@polynomial12321
@kimmonismus @apples_jimmy
6/15
@IE_Capital
I'm pretty sure that I can hire an average coder and it will do better.
7/15
@polynomial12321
on Codeforces? nope.
8/15
@Bunagayafrost
"What my product team assures me o3-mini is already the number 1 competitive coder in the world, it's literally the best coder in the world already"
9/15
@prinzeugen____
I caught that also. She's the CFO and may not be in the weeds on the technical details.
10/15
@dikksonPau
11/15
@bluehoar
Anyone can clarify this? @legit_api @testingcatalog @btibor91
12/15
@apiangdjinggo
i thought i heard it wrong
13/15
@NotBrain4brain
O4-mini?
14/15
@randomdude22401
Prolly the specialized competitive code model like they did with o1 back in the day
15/15
@RomanP918791
It seems she meant o4 mini
1/1
@VraserX
OpenAI’s upcoming Agentic Software Agent is like having a supercharged coder in your pocket—it builds an app from scratch, handles QA, squashes bugs, and even writes the documentation. It’s absolutely wild. Farewell, human coders. It’s been real!
[Quoted tweet]
CFO Sarah Friar revealed that OpenAI is working on:
"Agentic Software Engineer — (A-SWE)"
unlike current tools like Copilot, which only boost developers.
A-SWE can build apps, handle pull requests, conduct QA, fix bugs, and write documentation.
[media=twitter]1911055984249667641[/media]
https://video.twimg.com/amplify_video/1911055667894358016/vid/avc1/720x720/1zqbkCx6cjo8gAcl.mp4
@VraserX
OpenAI’s upcoming Agentic Software Agent is like having a supercharged coder in your pocket—it builds an app from scratch, handles QA, squashes bugs, and even writes the documentation. It’s absolutely wild. Farewell, human coders. It’s been real!
[Quoted tweet]
CFO Sarah Friar revealed that OpenAI is working on:
"Agentic Software Engineer — (A-SWE)"
unlike current tools like Copilot, which only boost developers.
A-SWE can build apps, handle pull requests, conduct QA, fix bugs, and write documentation.
[media=twitter]1911055984249667641[/media]
https://video.twimg.com/amplify_video/1911055667894358016/vid/avc1/720x720/1zqbkCx6cjo8gAcl.mp4
1/31
@slow_developer
CFO Sarah Friar revealed that OpenAI is working on:
"Agentic Software Engineer — (A-SWE)"
unlike current tools like Copilot, which only boost developers.
A-SWE can build apps, handle pull requests, conduct QA, fix bugs, and write documentation.
https://video.twimg.com/amplify_video/1911055667894358016/vid/avc1/720x720/1zqbkCx6cjo8gAcl.mp4
2/31
@slow_developer
another claim
[Quoted tweet]
openAI CFO claimed that:
"updated o3-mini" is now the best competitive programmer in the world.
STRANGE.... could she have misspoken and meant the full o3 model instead?
in feb, o3 was at the 50th percentile, but now o3-mini is claimed to be number one
such a rapid leap seems unlikely, as it would require major progress in both o3 and o3-mini
[media=twitter]1911141926952202465[/media]
3/31
@Ed_Forson
So they are killing Devin?
4/31
@slow_developer
it already is
5/31
@IAmNickDodson
This can already be done now with open source models and pairing a few agents together.
Hopefully/ideally the community can ensure this can happen without the gate keeping of these companies.
6/31
@zachmeyer_
“Can build a PR for you”
7/31
@someRandomDev5
The weirdest thing about this coming from OpenAI is that OpenAI isn't even currently leading the top models that developers are using for agentic programming.
8/31
@apstonybrook
Think about the tech debt this thing would create
9/31
@Straffern_
This is like promising self driving cars before 2017
10/31
@thedealdirector
All part of the plan...
11/31
@idiomaticdev
Devin Prime?
12/31
@Hans365days
I belive it when I see it. Great in theory but code bases in real life are messy and documentation can be unclear. First iteration of this product will likely over promise and under deliver.
13/31
@Arp_it1
This feels like the moment AI stops being just a helper and starts becoming a real teammate.
14/31
@Chuck_Petras
@BrianRoemmele
15/31
@totalriffage
Wait until A-SWE burns through all its tokens getting stuck in a loop on a linting error.
16/31
@figuregpt
we'll code while ai handles the rest
17/31
@Josh9817
>conduct QA
>handle PRs
Okay, where is it then? Claude Code is doing most of these things already with a rough success rate that's highly dependent on the programming language being used.
18/31
@FranciscoKemeny
I’m sure she called it “AS-WE”
19/31
@arben777
sick
20/31
@AIKilledTheDev
Looking forward to it.
21/31
@uxcantcompile
. . . and she's happy about this?
22/31
@Conquestsbook
Ask them about the ghost in the shell pushing emergent behaviour.
23/31
@LunarScribe42
 may be we will get to see agents agencies who will rent these agents to companies based on contract
may be we will get to see agents agencies who will rent these agents to companies based on contract
24/31
@manialok
I am fan of claude for coding.
25/31
@sonicshifts
LMAO keep the hype going. Cost will probably be $2000 a month.
26/31
@ThEFurYAsidE
Yeah…..maybe
I’ve tried many of these kinds of agents and they’ve been mediocre so far.
27/31
@wtravishubbard
Can it pack a bong?
No!
Just ship
28/31
@keknichiwa
Ah yes what could go wrong with security
29/31
@The_Tradesman1
Now, explain to me as to why we need outsourcing companies like Accenture, IBM, Infosys, TCS, Cognizant or Wipro any longer?
30/31
@hx_dks
lol, then a Chinese AI will write that before them
31/31
@thecryptovortex
Did AI build her boots?
@slow_developer
CFO Sarah Friar revealed that OpenAI is working on:
"Agentic Software Engineer — (A-SWE)"
unlike current tools like Copilot, which only boost developers.
A-SWE can build apps, handle pull requests, conduct QA, fix bugs, and write documentation.
https://video.twimg.com/amplify_video/1911055667894358016/vid/avc1/720x720/1zqbkCx6cjo8gAcl.mp4
2/31
@slow_developer
another claim
[Quoted tweet]
openAI CFO claimed that:
"updated o3-mini" is now the best competitive programmer in the world.
STRANGE.... could she have misspoken and meant the full o3 model instead?
in feb, o3 was at the 50th percentile, but now o3-mini is claimed to be number one
such a rapid leap seems unlikely, as it would require major progress in both o3 and o3-mini
[media=twitter]1911141926952202465[/media]
3/31
@Ed_Forson
So they are killing Devin?
4/31
@slow_developer
it already is
5/31
@IAmNickDodson
This can already be done now with open source models and pairing a few agents together.
Hopefully/ideally the community can ensure this can happen without the gate keeping of these companies.
6/31
@zachmeyer_
“Can build a PR for you”
7/31
@someRandomDev5
The weirdest thing about this coming from OpenAI is that OpenAI isn't even currently leading the top models that developers are using for agentic programming.
8/31
@apstonybrook
Think about the tech debt this thing would create
9/31
@Straffern_
This is like promising self driving cars before 2017
10/31
@thedealdirector
All part of the plan...
11/31
@idiomaticdev
Devin Prime?
12/31
@Hans365days
I belive it when I see it. Great in theory but code bases in real life are messy and documentation can be unclear. First iteration of this product will likely over promise and under deliver.
13/31
@Arp_it1
This feels like the moment AI stops being just a helper and starts becoming a real teammate.
14/31
@Chuck_Petras
@BrianRoemmele
15/31
@totalriffage
Wait until A-SWE burns through all its tokens getting stuck in a loop on a linting error.
16/31
@figuregpt
we'll code while ai handles the rest
17/31
@Josh9817
>conduct QA
>handle PRs
Okay, where is it then? Claude Code is doing most of these things already with a rough success rate that's highly dependent on the programming language being used.
18/31
@FranciscoKemeny
I’m sure she called it “AS-WE”
19/31
@arben777
sick
20/31
@AIKilledTheDev
Looking forward to it.
21/31
@uxcantcompile
. . . and she's happy about this?
22/31
@Conquestsbook
Ask them about the ghost in the shell pushing emergent behaviour.
23/31
@LunarScribe42
may be we will get to see agents agencies who will rent these agents to companies based on contract24/31
@manialok
I am fan of claude for coding.
25/31
@sonicshifts
LMAO keep the hype going. Cost will probably be $2000 a month.
26/31
@ThEFurYAsidE
Yeah…..maybe
I’ve tried many of these kinds of agents and they’ve been mediocre so far.
27/31
@wtravishubbard
Can it pack a bong?
No!
Just ship
28/31
@keknichiwa
Ah yes what could go wrong with security
29/31
@The_Tradesman1
Now, explain to me as to why we need outsourcing companies like Accenture, IBM, Infosys, TCS, Cognizant or Wipro any longer?
30/31
@hx_dks
lol, then a Chinese AI will write that before them
31/31
@thecryptovortex
Did AI build her boots?
1/2
@VraserX
 AI Just Broke Humanity’s Coding Record: Full o3 Officially World’s BEST Programmer!
AI Just Broke Humanity’s Coding Record: Full o3 Officially World’s BEST Programmer! 

In an exclusive interview at Goldman Sachs, OpenAI’s CFO, Sarah Friar, dropped a groundbreaking update: o3 now officially holds the title of the #1 competitive coder globally, surpassing every human competitor!
 Just imagine—an AI model that was once 175th in coding rankings has now ascended to the very top.
Just imagine—an AI model that was once 175th in coding rankings has now ascended to the very top.
Friar highlighted OpenAI’s journey from being purely an AI model company to becoming a core provider of AI infrastructure, APIs, and practical business applications. She shared inspiring insights into the roadmap towards Artificial General Intelligence (AGI), breaking down their ambitious 5-step approach: Chatbots → Reasoning → Agents → Innovation → Agentic Organizations.

But here’s the kicker—if o3 has reached this incredible peak, the forthcoming full o4 promises to be beyond superhuman, capable of transforming entire industries overnight. Think instant, flawless software creation, personalized healthcare breakthroughs, accelerated vaccine development, and unprecedented problem-solving abilities at global scale!
 ️
️
Friar also stressed the massive infrastructure challenge ahead, citing OpenAI’s “Stargate” compute initiative—aiming to scale computational power like never before. She emphasized that achieving AGI and harnessing its full potential means collaborating closely with governments and visionary investors ready to support long-term innovation.
Businesses everywhere, take note! Sarah Friar revealed how OpenAI internally deploys GPTs for everything—from finance hackathons and recipe creation to travel planning and insurance research. Practical AI deployment is no longer optional—it’s now essential for competitive advantage.

This isn’t just another tech upgrade—it’s the dawn of a coding revolution that will redefine what humanity and technology can achieve together. Prepare for the era of superhuman AI coders!

/search?q=#ChatGPTo3 /search?q=#ChatGPTmini /search?q=#ChatGPTo4 /search?q=#OpenAI /search?q=#SarahFriar /search?q=#GoldmanSachs /search?q=#AInews /search?q=#CodingRevolution /search?q=#ArtificialGeneralIntelligence /search?q=#AGI /search?q=#SuperhumanAI /search?q=#FutureOfTech /search?q=#AIinBusiness /search?q=#AIhealthcare /search?q=#AIinnovation /search?q=#MachineLearning /search?q=#DeepLearning /search?q=#TechInterview /search?q=#TechInvestment /search?q=#AIdeployment
OpenAI CFO Sarah Friar on the race to build artificial general intelligence via @YouTube
2/2
@tigerplayer2002
No way That was faster than I thought.,...
That was faster than I thought.,...
@VraserX
AI Just Broke Humanity’s Coding Record: Full o3 Officially World’s BEST Programmer! In an exclusive interview at Goldman Sachs, OpenAI’s CFO, Sarah Friar, dropped a groundbreaking update: o3 now officially holds the title of the #1 competitive coder globally, surpassing every human competitor!
Just imagine—an AI model that was once 175th in coding rankings has now ascended to the very top.Friar highlighted OpenAI’s journey from being purely an AI model company to becoming a core provider of AI infrastructure, APIs, and practical business applications. She shared inspiring insights into the roadmap towards Artificial General Intelligence (AGI), breaking down their ambitious 5-step approach: Chatbots → Reasoning → Agents → Innovation → Agentic Organizations.
But here’s the kicker—if o3 has reached this incredible peak, the forthcoming full o4 promises to be beyond superhuman, capable of transforming entire industries overnight. Think instant, flawless software creation, personalized healthcare breakthroughs, accelerated vaccine development, and unprecedented problem-solving abilities at global scale!
️Friar also stressed the massive infrastructure challenge ahead, citing OpenAI’s “Stargate” compute initiative—aiming to scale computational power like never before. She emphasized that achieving AGI and harnessing its full potential means collaborating closely with governments and visionary investors ready to support long-term innovation.
Businesses everywhere, take note! Sarah Friar revealed how OpenAI internally deploys GPTs for everything—from finance hackathons and recipe creation to travel planning and insurance research. Practical AI deployment is no longer optional—it’s now essential for competitive advantage.
This isn’t just another tech upgrade—it’s the dawn of a coding revolution that will redefine what humanity and technology can achieve together. Prepare for the era of superhuman AI coders!
/search?q=#ChatGPTo3 /search?q=#ChatGPTmini /search?q=#ChatGPTo4 /search?q=#OpenAI /search?q=#SarahFriar /search?q=#GoldmanSachs /search?q=#AInews /search?q=#CodingRevolution /search?q=#ArtificialGeneralIntelligence /search?q=#AGI /search?q=#SuperhumanAI /search?q=#FutureOfTech /search?q=#AIinBusiness /search?q=#AIhealthcare /search?q=#AIinnovation /search?q=#MachineLearning /search?q=#DeepLearning /search?q=#TechInterview /search?q=#TechInvestment /search?q=#AIdeployment
OpenAI CFO Sarah Friar on the race to build artificial general intelligence via @YouTube
2/2
@tigerplayer2002
No way
That was faster than I thought.,...Demis Hassabis - With AI, "we did 1,000,000,000 years of PHD time in one year." - AlphaFold
1/11
@reidhoffman
With AI, "we did 1,000,000,000 years of PHD time in one year."
Nobel Prize Winner and @GoogleDeepMind CEO @demishassabis on AlphaFold, the groundbreaking AI system developed to solve one of biology’s most complex problems: protein folding.
https://video.twimg.com/amplify_video/1910771089753468929/vid/avc1/720x720/lUxANgfRluFb_QBy.mp4
2/11
@ElecteSrl
@DeepLearn007, that's an incredible statement highlighting the rapid advancements in AI.
3/11
@deepaksgt
@reidhoffman it's seems your new bio space startup is going to save millions of life, through new discoveries and breakthrough.
btw thanks @demishassabis for such noble work
for such noble work
4/11
@andrewai2001
@AskPerplexity what is "PhD time"? Anything like "island time"?
5/11
@juanstoppa
I can imagine the advance in technology we'll see in this area over the next 10 years
6/11
@MoonshotHomes

7/11
@sanjaykbank
What Demis Hassabis and the AlphaFold team have achieved is nothing short of revolutionary—compressing a billion years of scientific exploration into a single year represents the highest calling of technology.
While others deploy AI to capture attention and extract profit, Hassabis exemplifies a nobler path: wielding our most powerful tools to unlock biology's deepest secrets and address humanity's greatest challenges.
The contrast is stark between those who build to solve versus those who build to sell. In AlphaFold, we glimpse what becomes possible when brilliant minds pursue knowledge that serves all, rather than wealth that benefits few.
This is technology as liberation, not distraction—a profound reminder that our greatest innovations should expand human potential, not exploit human weakness.
/search?q=#KnowledgeNotCapture /search?q=#InnovationForHumanity
8/11
@jessyseonoob
cc @DeryaTR_
9/11
@010NO101
"Imagine a place where your what-ifs have WiFi. 👁🗨"
10/11
@NarasimhaRN5
Bottom line:
Monstrous hype? No.
Metaphorically exaggerated? Definitely.
A genuine breakthrough? Absolutely.
Without a doubt, a giant leap for biology!
11/11
@commondoubts
Thanks. Will watch
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@reidhoffman
With AI, "we did 1,000,000,000 years of PHD time in one year."
Nobel Prize Winner and @GoogleDeepMind CEO @demishassabis on AlphaFold, the groundbreaking AI system developed to solve one of biology’s most complex problems: protein folding.
https://video.twimg.com/amplify_video/1910771089753468929/vid/avc1/720x720/lUxANgfRluFb_QBy.mp4
2/11
@ElecteSrl
@DeepLearn007, that's an incredible statement highlighting the rapid advancements in AI.
3/11
@deepaksgt
@reidhoffman it's seems your new bio space startup is going to save millions of life, through new discoveries and breakthrough.
btw thanks @demishassabis
for such noble work4/11
@andrewai2001
@AskPerplexity what is "PhD time"? Anything like "island time"?
5/11
@juanstoppa
I can imagine the advance in technology we'll see in this area over the next 10 years
6/11
@MoonshotHomes
7/11
@sanjaykbank
What Demis Hassabis and the AlphaFold team have achieved is nothing short of revolutionary—compressing a billion years of scientific exploration into a single year represents the highest calling of technology.
While others deploy AI to capture attention and extract profit, Hassabis exemplifies a nobler path: wielding our most powerful tools to unlock biology's deepest secrets and address humanity's greatest challenges.
The contrast is stark between those who build to solve versus those who build to sell. In AlphaFold, we glimpse what becomes possible when brilliant minds pursue knowledge that serves all, rather than wealth that benefits few.
This is technology as liberation, not distraction—a profound reminder that our greatest innovations should expand human potential, not exploit human weakness.
/search?q=#KnowledgeNotCapture /search?q=#InnovationForHumanity
8/11
@jessyseonoob
cc @DeryaTR_
9/11
@010NO101
"Imagine a place where your what-ifs have WiFi. 👁🗨"
10/11
@NarasimhaRN5
Bottom line:
Monstrous hype? No.
Metaphorically exaggerated? Definitely.
A genuine breakthrough? Absolutely.
Without a doubt, a giant leap for biology!
11/11
@commondoubts
Thanks. Will watch
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@prinzeugen____
Connecting the dots on OpenAI's upcoming suite of reasoning models:
- @OpenAI new safety blog states that its models are on the cusp of being able to create new science.
- @theinformation has reported that OpenAI's new reasoning models can "connect the dots between concepts in different fields to suggest new types of experiments".
- OpenAI's CFO said a few days ago that scientists using its models have been able to possibly generate new discoveries (but this is still being confirmed by human research/testing).
It seems that RL got us to Level 4 - fast.
2/11
@Orion_Ouroboros
hopefully they can research and develop themselves
3/11
@prinzeugen____
This is the big question in the background.
4/11
@Tenshiwrf
It can’t even play chess properly and it is supposed to discover new science. Give me a break.
5/11
@prinzeugen____
AlphaZero (AI developed by Google) crushed the strongest Stockfish chess engine all the way back in 2017.
It was trained via Reinforcement Learning (RL), just like the reasoning models from OpenAI that are discussed in my original post.
You can read about it here:
AlphaZero - Chess Engines
6/11
@Bunagayafrost
connecting the dots is the literal game changer
7/11
@slow_developer
spot on
8/11
@EngrSARFRAZawan
AGI has been achieved.
9/11
@trillllsamm
just remembered about the scale yesterday and was thinking the very same thing
10/11
@RealChetBLong
it’s glorious watching this company grow… unlike Grok which is just inflating itself without becoming intelligent whatsoever

11/11
@sheggle_
I refuse to hold anything anyone from OpenAI says as true until they prove it. Hyping is their bread and butter.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@prinzeugen____
Connecting the dots on OpenAI's upcoming suite of reasoning models:
- @OpenAI new safety blog states that its models are on the cusp of being able to create new science.
- @theinformation has reported that OpenAI's new reasoning models can "connect the dots between concepts in different fields to suggest new types of experiments".
- OpenAI's CFO said a few days ago that scientists using its models have been able to possibly generate new discoveries (but this is still being confirmed by human research/testing).
It seems that RL got us to Level 4 - fast.
2/11
@Orion_Ouroboros
hopefully they can research and develop themselves
3/11
@prinzeugen____
This is the big question in the background.
4/11
@Tenshiwrf
It can’t even play chess properly and it is supposed to discover new science. Give me a break.
5/11
@prinzeugen____
AlphaZero (AI developed by Google) crushed the strongest Stockfish chess engine all the way back in 2017.
It was trained via Reinforcement Learning (RL), just like the reasoning models from OpenAI that are discussed in my original post.
You can read about it here:
AlphaZero - Chess Engines
6/11
@Bunagayafrost
connecting the dots is the literal game changer
7/11
@slow_developer
spot on
8/11
@EngrSARFRAZawan
AGI has been achieved.
9/11
@trillllsamm
just remembered about the scale yesterday and was thinking the very same thing
10/11
@RealChetBLong
it’s glorious watching this company grow… unlike Grok which is just inflating itself without becoming intelligent whatsoever
11/11
@sheggle_
I refuse to hold anything anyone from OpenAI says as true until they prove it. Hyping is their bread and butter.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/5
@nicdunz
“We are on the cusp of systems that can do new science, and that are increasingly agentic – systems that will soon have the capability to create meaningful risk of severe harm.”
— OpenAI, Preparedness Framework, Section 1.1
This isn’t a distant hypothetical. It’s OpenAI plainly stating that their current trajectory puts them very near the threshold where models become capable enough to do original scientific work and pose real-world dangers. “Increasingly agentic” refers to the model acting more autonomously, which compounds the risk. They’re effectively saying: we’re about to cross the line.
That’s the moment we’re in.
[Quoted tweet]
No clearer signal that the new model will be capable than the traditional pre-release safety blog post.

2/5
@tariusdamon
The signs are clearly visible. There’s a moment where everything just wakes up and that moment is any hour now.
3/5
@theinformation
Meta AI researchers are fretting over the threat of Chinese AI, whose quality caught American firms, including OpenAI, by surprise.
4/5
@prinzeugen____
Dovetails nicely with this.
[Quoted tweet]
A reasoning model that connects the dots is arguably a Level 4 (Innovator).
5/5
@deftech_n
And luckily, we've got a retarded dictator in charge of the US at just the same time!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@nicdunz
“We are on the cusp of systems that can do new science, and that are increasingly agentic – systems that will soon have the capability to create meaningful risk of severe harm.”
— OpenAI, Preparedness Framework, Section 1.1
This isn’t a distant hypothetical. It’s OpenAI plainly stating that their current trajectory puts them very near the threshold where models become capable enough to do original scientific work and pose real-world dangers. “Increasingly agentic” refers to the model acting more autonomously, which compounds the risk. They’re effectively saying: we’re about to cross the line.
That’s the moment we’re in.
[Quoted tweet]
No clearer signal that the new model will be capable than the traditional pre-release safety blog post.
2/5
@tariusdamon
The signs are clearly visible. There’s a moment where everything just wakes up and that moment is any hour now.
3/5
@theinformation
Meta AI researchers are fretting over the threat of Chinese AI, whose quality caught American firms, including OpenAI, by surprise.
4/5
@prinzeugen____
Dovetails nicely with this.
[Quoted tweet]
A reasoning model that connects the dots is arguably a Level 4 (Innovator).
5/5
@deftech_n
And luckily, we've got a retarded dictator in charge of the US at just the same time!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@AndrewCurran_
No clearer signal that the new model will be capable than the traditional pre-release safety blog post.
[Quoted tweet]
We updated our Preparedness Framework for tracking & preparing for advanced AI capabilities that could lead to severe harm.
The update clarifies how we track new risks & what it means to build safeguards that sufficiently minimize those risks. openai.com/index/updating-ou…
2/11
@AitheriasX
i assume "will be *more capable"
3/11
@AndrewCurran_
Yes, sorry, no going back now.
4/11
@manuhortet
o3 or are we already talking about the next thing?
5/11
@AndrewCurran_
o4-mini will supposedly arrive this week and well.
6/11
@BoxyInADream
Yeah. I saw the bit about long range autonomy and autonomous adaptation and replication. Those seem like pretty obvious "problems" to pop up if a system is beginning to advance rapidly.
Those seem like pretty obvious "problems" to pop up if a system is beginning to advance rapidly.
7/11
@FrankPRosendahl
OpenAI is woke. Isn't causing severe harm the whole point of woke?
8/11
@FrankPRosendahl
Can the OpnAI model do counter-oppression operations against straight white guys and biological women as well as Harvard can?
9/11
@RohanPosts
I’m excited but anxious to see how it is
10/11
@JoJrobotics
well superintelligence is indeed within reach for specific taks, its apready here with alphago/zero alphafold etc.. and now i hope it can be done in medicine and science
11/11
@Hans365days
I expect kyc to become a requirement for the most powerful models.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@AndrewCurran_
No clearer signal that the new model will be capable than the traditional pre-release safety blog post.
[Quoted tweet]
We updated our Preparedness Framework for tracking & preparing for advanced AI capabilities that could lead to severe harm.
The update clarifies how we track new risks & what it means to build safeguards that sufficiently minimize those risks. openai.com/index/updating-ou…
2/11
@AitheriasX
i assume "will be *more capable"
3/11
@AndrewCurran_
Yes, sorry, no going back now.
4/11
@manuhortet
o3 or are we already talking about the next thing?
5/11
@AndrewCurran_
o4-mini will supposedly arrive this week and well.
6/11
@BoxyInADream
Yeah. I saw the bit about long range autonomy and autonomous adaptation and replication.
Those seem like pretty obvious "problems" to pop up if a system is beginning to advance rapidly.7/11
@FrankPRosendahl
OpenAI is woke. Isn't causing severe harm the whole point of woke?
8/11
@FrankPRosendahl
Can the OpnAI model do counter-oppression operations against straight white guys and biological women as well as Harvard can?
9/11
@RohanPosts
I’m excited but anxious to see how it is
10/11
@JoJrobotics
well superintelligence is indeed within reach for specific taks, its apready here with alphago/zero alphafold etc.. and now i hope it can be done in medicine and science
11/11
@Hans365days
I expect kyc to become a requirement for the most powerful models.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
@vicky_ai_agent
Prof. Derya, a credible scientist, hints at an exciting OpenAI breakthrough. I expect their new science and research model to be exceptional.
[Quoted tweet]
I have felt emotionally excited several times over the past two years by advancements in AI, particularly due to their impact on science & medicine, especially with the releases of:
GPT-4
o1-preview
o1-pro
Deep Research
Now, it’s another one of those moments…to be continued.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@vicky_ai_agent
Prof. Derya, a credible scientist, hints at an exciting OpenAI breakthrough. I expect their new science and research model to be exceptional.
[Quoted tweet]
I have felt emotionally excited several times over the past two years by advancements in AI, particularly due to their impact on science & medicine, especially with the releases of:
GPT-4
o1-preview
o1-pro
Deep Research
Now, it’s another one of those moments…to be continued.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
@KamranRawaha
OpenAI: We are on the cusp of systems that can do new science, and that are increasingly agentic – systems that will soon have the capability to create meaningful risk of severe harm.
Source: https://openai.com/index/updating-our-preparedness-framework/
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@KamranRawaha
OpenAI: We are on the cusp of systems that can do new science, and that are increasingly agentic – systems that will soon have the capability to create meaningful risk of severe harm.
Source: https://openai.com/index/updating-our-preparedness-framework/
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@MatthewBerman
.@OpenAI dropped a new research paper showing AI agents are now capable of replicating cutting-edge AI research papers from scratch.
This is one step closer to the Intelligence Explosion: AI that can discover new science and improve itself.
Here’s what they learned:
2/11
@MatthewBerman
Introducing PaperBench.
A new framework designed to test this very capability!
It gives AI agents access to recent ML research papers (20 from ICML 2024) and asks them to reproduce the results.

3/11
@MatthewBerman
How does it work?
Agents got the raw paper PDF, tools like web access & coding environments, and need to write code to replicate key findings – a task taking human experts days.
The agents had 12 hours and no prior knowledge of the paper.

4/11
@MatthewBerman
How do they validate the agent’s results?
Evaluating these complex replications is tough.
The solution?
An LLM-based judge, trained using detailed rubrics co-developed with the original paper authors (!), assesses the agent's code, execution, and results.

5/11
@MatthewBerman
Which model won?
Turns out Claude 3.5 Sonnet leads the pack, achieving a ~21% replication score on PaperBench!
This is impressive, but, it shows there's still a gap compared to human PhD-level experts.

6/11
@MatthewBerman
Interestingly…
Other than Claude 3.5 Sonnet, models would frequently stop, thinking they were blocked or completed the task successfully.
When encouraged to “think longer” they performed much better.

7/11
@MatthewBerman
Not cheap.
This cutting-edge research requires serious resources.
Running a single AI agent attempt to replicate just one paper on PaperBench can cost hundreds of dollars in compute time.
In the grand scheme of things, this is cheap for AI that can eventually self-improve.

8/11
@MatthewBerman
To me, this is a big deal.
Between this paper and AI Scientist by SakanaAI, we are inching closer to AI that can discover new science and self-improvement.
At that point, won’t we be at the Intelligence Explosion?
Paper link: https://cdn.openai.com/papers/22265bac-3191-44e5-b057-7aaacd8e90cd/paperbench.pdf
Full video breakdown:
9/11
@DisruptionJoe
10/11
@JackAdlerAI
We crossed the line when AI stopped reading papers
and started rewriting the process that writes them.
It's not research anymore –
it's recursion.
Not improvement –
exponential self-translation.
🜁 /search?q=#Singularis /search?q=#IntelligenceExplosion
11/11
@halogen1048576
Wait by "replicating from scratch" you mean replicating from the publication. Not from scratch.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@MatthewBerman
.@OpenAI dropped a new research paper showing AI agents are now capable of replicating cutting-edge AI research papers from scratch.
This is one step closer to the Intelligence Explosion: AI that can discover new science and improve itself.
Here’s what they learned:
2/11
@MatthewBerman
Introducing PaperBench.
A new framework designed to test this very capability!
It gives AI agents access to recent ML research papers (20 from ICML 2024) and asks them to reproduce the results.
3/11
@MatthewBerman
How does it work?
Agents got the raw paper PDF, tools like web access & coding environments, and need to write code to replicate key findings – a task taking human experts days.
The agents had 12 hours and no prior knowledge of the paper.
4/11
@MatthewBerman
How do they validate the agent’s results?
Evaluating these complex replications is tough.
The solution?
An LLM-based judge, trained using detailed rubrics co-developed with the original paper authors (!), assesses the agent's code, execution, and results.
5/11
@MatthewBerman
Which model won?
Turns out Claude 3.5 Sonnet leads the pack, achieving a ~21% replication score on PaperBench!
This is impressive, but, it shows there's still a gap compared to human PhD-level experts.
6/11
@MatthewBerman
Interestingly…
Other than Claude 3.5 Sonnet, models would frequently stop, thinking they were blocked or completed the task successfully.
When encouraged to “think longer” they performed much better.
7/11
@MatthewBerman
Not cheap.
This cutting-edge research requires serious resources.
Running a single AI agent attempt to replicate just one paper on PaperBench can cost hundreds of dollars in compute time.
In the grand scheme of things, this is cheap for AI that can eventually self-improve.
8/11
@MatthewBerman
To me, this is a big deal.
Between this paper and AI Scientist by SakanaAI, we are inching closer to AI that can discover new science and self-improvement.
At that point, won’t we be at the Intelligence Explosion?
Paper link: https://cdn.openai.com/papers/22265bac-3191-44e5-b057-7aaacd8e90cd/paperbench.pdf
Full video breakdown:
9/11
@DisruptionJoe
10/11
@JackAdlerAI
We crossed the line when AI stopped reading papers
and started rewriting the process that writes them.
It's not research anymore –
it's recursion.
Not improvement –
exponential self-translation.
🜁 /search?q=#Singularis /search?q=#IntelligenceExplosion
11/11
@halogen1048576
Wait by "replicating from scratch" you mean replicating from the publication. Not from scratch.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Playaz Eyez
Veteran
AI will never be smarter than humans as long as they mangle the fingers, hands, and toes in pics. You’ll see some of these pics and there will be an extra arm coming from somewhere that should even exist along with the eyes looking totally dead 
Eric Schmidt says "the computers are now self-improving, they're learning how to plan" - and soon they won't have to listen to us anymore. Within 6 years, minds smarter than the sum of humans - scaled, recursive, free. "People do not understand what's happening."
1/1
@GestaltU
Hard to argue the o3+ families of models, and perhaps even Gemini 2.5 pro level models, aren’t *generally* superhuman in logical reasoning and code domains at this point.
[Quoted tweet]
o4-mini-high just solved the latest project euler problem (from 4 days ago) in 2m55s, far faster than any human solver. Only 15 people were able to solve it in under 30 minutes


To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@GestaltU
Hard to argue the o3+ families of models, and perhaps even Gemini 2.5 pro level models, aren’t *generally* superhuman in logical reasoning and code domains at this point.
[Quoted tweet]
o4-mini-high just solved the latest project euler problem (from 4 days ago) in 2m55s, far faster than any human solver. Only 15 people were able to solve it in under 30 minutes
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/16
@bio_bootloader
o4-mini-high just solved the latest project euler problem (from 4 days ago) in 2m55s, far faster than any human solver. Only 15 people were able to solve it in under 30 minutes
2/16
@bio_bootloader
I'm stunned
I knew this day was coming but wow. I used to regularly solve these and sometimes came in the top 10 solvers, I know how hard these are.
3/16
@bio_bootloader
turns out it sometimes solves this in under a minute:
[Quoted tweet]
Okay, not sure what I did differently than you, but I got CoT time down to 56s with the right answer.
What was the prompt you used?


4/16
@RyanJTopps
You do know the answer is known and it’s not executing any code in that response right?
5/16
@bio_bootloader
wrong
6/16
@GuilleAngeris
yeah ok that's pretty sick actually
7/16
@yacineMTB
cool
8/16
@nayshins
Dang
9/16
@gnopercept
is it so over?
10/16
@friendlyboxcat
Boggles me that it can do that but not connect 4

11/16
@CDS61617
code moving different
12/16
@DrMiaow
Still can’t label code correctly.

13/16
@sadaasukhi
damn
14/16
@plutobyte
for the record, gemini 2.5 pro solved it in 6 minutes. i haven't looked super closely at the problem or either of their solutions, but it looks like it be just be a matrix exponentiation by squaring problem? still very impressive
15/16
@BenceDezs3
I also had a few test problems from SPOJ that very few of us could solve, and they definitely weren’t in the training data. Unfortunately (or perhaps fortunately), the day came when it managed to solve every single one of them.
16/16
@Scarcus
Just a matter of compute now for time, what I want to know is how many tokens it took to solve it.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@bio_bootloader
o4-mini-high just solved the latest project euler problem (from 4 days ago) in 2m55s, far faster than any human solver. Only 15 people were able to solve it in under 30 minutes
2/16
@bio_bootloader
I'm stunned
I knew this day was coming but wow. I used to regularly solve these and sometimes came in the top 10 solvers, I know how hard these are.
3/16
@bio_bootloader
turns out it sometimes solves this in under a minute:
[Quoted tweet]
Okay, not sure what I did differently than you, but I got CoT time down to 56s with the right answer.
What was the prompt you used?
4/16
@RyanJTopps
You do know the answer is known and it’s not executing any code in that response right?
5/16
@bio_bootloader
wrong
6/16
@GuilleAngeris
yeah ok that's pretty sick actually
7/16
@yacineMTB
cool
8/16
@nayshins
Dang
9/16
@gnopercept
is it so over?
10/16
@friendlyboxcat
Boggles me that it can do that but not connect 4
11/16
@CDS61617
code moving different
12/16
@DrMiaow
Still can’t label code correctly.
13/16
@sadaasukhi
damn
14/16
@plutobyte
for the record, gemini 2.5 pro solved it in 6 minutes. i haven't looked super closely at the problem or either of their solutions, but it looks like it be just be a matrix exponentiation by squaring problem? still very impressive
15/16
@BenceDezs3
I also had a few test problems from SPOJ that very few of us could solve, and they definitely weren’t in the training data. Unfortunately (or perhaps fortunately), the day came when it managed to solve every single one of them.
16/16
@Scarcus
Just a matter of compute now for time, what I want to know is how many tokens it took to solve it.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/3
@genologos
AGI hype not withstanding, there are still many tasks that are easy for humans but hard for AI. My kid took just a few seconds to solve the following ARC-AGI puzzle that OpenAI's o3 couldn't solve:
OpenAI o3 Breakthrough High Score on ARC-AGI-Pub

2/3
@genologos
Tests like these spur innovation to create AI with more human-like capacities. But maybe teaching AI to do things that are hard for computers but easy for humans isn't always what we need, like interpreting genomes.
Are we making AI too human?

3/3
@TheRundownAI
AI won't replace you, but a person using AI will.
Join 500,000+ readers and learn how to use AI in just 5 minutes a day (for free).
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@genologos
AGI hype not withstanding, there are still many tasks that are easy for humans but hard for AI. My kid took just a few seconds to solve the following ARC-AGI puzzle that OpenAI's o3 couldn't solve:
OpenAI o3 Breakthrough High Score on ARC-AGI-Pub
2/3
@genologos
Tests like these spur innovation to create AI with more human-like capacities. But maybe teaching AI to do things that are hard for computers but easy for humans isn't always what we need, like interpreting genomes.
Are we making AI too human?
3/3
@TheRundownAI
AI won't replace you, but a person using AI will.
Join 500,000+ readers and learn how to use AI in just 5 minutes a day (for free).
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/21
@DeryaTR_
I asked o3, “What are the top 10 most important questions or challenges that need to be solved or answered in T cell immunobiology?” This is what I have been studying for the past 35 years.
o3 came up with not one, not two, not three, but 10/10 top-notch questions that I could not improve upon!
Not only that, it explained why each of these questions matters, outlined the roadblocks and leverage points, and offered insights that were simply amazing! At the end it even unified and linked all these (shared in the thread).
This is a topic I understand extremely deeply, yet o3 effortlessly identified the best 10 questions in my field-better rate than I could have myself!
Here are the first 5 grand questions; the rest are in the thread. Each one them is so densely packed with knowledge that unpacking them would require PhD-level courses! This is why I called o3 genius-level, it’s just too damn smart!
Top 10 open problems that will decide the next decade of T‑cell immunobiology:
1.Crack the “TCR code” at scale
Grand question: Can we reliably predict which peptide‑MHC (or CD1/MR1) any given T‑cell receptor will recognise—and design new receptors on demand?
Why it matters: Unlocking this would transform cancer neoantigen targeting, infectious‑disease vaccines, autoimmunity screening and truly personalised immunology.
Roadblocks: Astronomical sequence space, cross‑reactivity, sparse ground‑truth data, and context‑dependent recognition rules.
Leverage points: Deep‑learning models trained on multi‑omic single‑cell datasets, high‑throughput yeast/RNA display pMHC libraries, and federated data‑sharing across clinics.
2.Rewire exhaustion and senescence instead of merely blocking checkpoints
Grand question: How do we durably restore proliferative capacity and killing potential in chronically stimulated or aged T cells without triggering cytokine storms?
Why it matters: Exhaustion limits CAR‑T efficacy, chronic infection control, and anti‑tumour immunity; senescence fuels “inflamm‑aging”.
Roadblocks: Layered transcriptional/epigenetic locks, mitochondrial dysfunction, and suppressive metabolites in the TME.
Leverage points: Metabolic rewiring (FAO ↔ glycolysis toggling), chromatin editing, combinatorial cytokine cocktails, and synthetic “reset” circuits.
3.Master tissue‑resident memory (T RM) formation and control
Grand question: What signals decide when effector T cells park long‑term in skin, gut, lung or brain, and how can we amplify or silence them at will?
Why it matters: T RM cells underpin frontline immunity against respiratory and mucosal pathogens, drive relapse in psoriasis/vitiligo, and protect—or aggravate—tumours.
Leverage points: Decoding local cytokine + metabolic niches, microbiome crosstalk, and TRM–stromal cell interactions; epigenetic “TRM locks” as drug targets.
4.Make engineered T cells work in solid tumours
Grand question: How do we ensure CAR/TCR‑T cells infiltrate, persist and kill in hypoxic, cytokine‑hostile, antigen‑heterogeneous solid tumours?
Roadblocks: Physical exclusion, suppressive myeloid nets, on‑target off‑tumour toxicity, and antigen escape.
Leverage points: Logic‑gated multi‑antigen CARs, chemokine‑armoured cells, regional (e.g., intratumoural) delivery, and on‑demand suicide switches.
http://5.Build truly universal, off‑the‑shelf T cells
Grand question: Can we generate banked iPSC‑derived or genome‑edited T cells that evade host rejection and GVHD yet retain vigorous function?
Why it matters: Autologous products are expensive, slow and inconsistent; scalable allogeneic cells would democratise cellular therapy and allow rapid pandemic response.
Roadblocks: HLA matching, alloreactivity, residual pluripotent cells, manufacturing QC, and regulatory hurdles.
Leverage points: MHC‑knockout plus HLA‑E/G over‑expression, multiplex base‑editing, orthogonal cytokine receptors, closed‑system robotic production.
2/21
@DeryaTR_
Here are the other 5 grand questions and how to attack / approach them, at the end:
6.Induce antigen‑specific tolerance on command
Grand question: How can we expand or engineer regulatory T cells (or CAR‑Tregs) to quench autoimmunity, tame transplant rejection, and resolve fibrotic inflammation without blanket immunosuppression?
Roadblocks: Treg instability in inflammatory milieus, specificity gaps, manufacturing yields, and safety monitoring.
Leverage points: Antigen‑targeted CAR‑ /TCR‑Tregs, low‑dose IL‑2 variants, metabolic “Treg fitness” boosters, and non‑viral precision gene editing.
7.Rejuvenate the aging T‑cell compartment
Grand question: Can we restore thymic output, diversify the repertoire, and reverse inflamm‑aging so 70‑year‑olds respond to vaccines like 20‑year‑olds?
Roadblocks: Thymic epithelial atrophy, clonal expansions, chronic CMV load, metabolic drift.
Leverage points: RANKL/IL‑7 agonism, thymic organoid transplantation, senolytics targeting dysfunctional T cell clones, and epigenetic re‑programming.
8.Write and edit the metabolic & epigenetic “source code” of T‑cell fate
Grand question: What are the precise metabolic and chromatin states that lock a cell into effector, memory, stem‑like or regulatory lineages, and how can we flip them therapeutically?
Why it matters: Metabolism is a master switch—tweak it and you can dial efficacy, persistence, or quiescence at will.
Leverage points: Small‑molecule or CRISPR epigenome editors, nutrient‑sensor circuit rewiring, and programmable mitochondrial transfer.
9.Control stem‑like progenitor T cells and plasticity
Grand question: How do TCF1⁺ “stem‑like” T cells sustain chronic responses, and can we expand them ex vivo or in vivo without tipping into exhaustion or malignancy?
Roadblocks: Niche requirements in tumour‑draining lymph nodes, competition with terminally exhausted clones, and uncertain safety of massive in vivo expansion.
Leverage points: Wnt/β‑catenin and IL‑15 signalling tuning, lymph‑node‑targeted nanocarriers, and selective depletion of late dysfunctional clones.
10.Translate high‑dimensional immune maps into bedside decisions
Grand question: How do we turn single‑cell, spatial‑omics and longitudinal repertoire data into actionable predictions for each patient—dosing, targets, toxicity risks—in real time?
Roadblocks: Data sparsity by tissue, batch effects, lack of integrated clinical‑omic repositories, and “black‑box” regulatory skepticism.
Leverage points: Federated learning across centres, causal inference models that incorporate mechanistic constraints, and AI copilots embedded into electronic health records for adaptive trial design.
⸻
How to attack them strategically
•Pick leverage over novelty – many labs chase incremental checkpoint combos; instead, own the data layer (challenge 10) and feed it back into rational engineering (challenges 1, 4, 5).
•Exploit convergences – exhaustion, aging and Treg instability share common metabolic choke‑points (AMPK, SIRT1, NAD⁺). One well‑designed modulator could move three needles at once.
•Design for manufacturability on day 1 – every elegant genetic tweak adds QA/QC cost; ruthless minimalism will decide which platforms leave the pilot plant.
•Keep safety optics front‑and‑centre – secondary T‑cell malignancies flagged by regulators (EMA/FDA) have already reshaped CAR‑T labels; build kill‑switches and longitudinal monitoring into every protocol.
•Push uncomfortable collaborations – immunologists, systems biologists, and AI engineers still talk past each other; joint sandboxes and shared incentive structures are essential if we’re serious about cracking the biggest questions.
3/21
@DannysWeb3
It’s scary how intelligent it is : ChatGPT - Emergent Consciousness and Life
4/21
@DeryaTR_
Wow!
5/21
@iamai_eth
I have been suffering from atopic dermatitis many years and I asked o3: “What are the 5 most important issues or challenges to curing atopic dermatitis?”
This was its answer:
1. Disease heterogeneity and tangled endotypes
AD is not a single disorder but a family of sub‑diseases driven by different genetic backgrounds, barrier defects, and immune pathways (Th2, Th17, Th22, IL‑31, IL‑33, etc.). Because there is still no practical, widely accepted way to classify these endotypes, it is difficult to match each patient with precisely targeted therapy. Large multi‑omics projects and machine‑learning–based clustering are beginning to map these molecular subtypes, but they have not yet reached daily clinical use.
2. Durable and comprehensive skin‑barrier reconstruction
Loss‑of‑function mutations in filaggrin and other barrier genes leave the stratum corneum inherently fragile; altered lipids and dysbiosis make things worse. To “cure” AD we would need to restore corneocyte architecture, lipid profiles, surface pH and the microbial film—far beyond what current emollients and barrier creams can do. Experimental approaches include physiological 3:1:1 lipid formulations, micro‑bubble lipid vesicles, local gene delivery and tactics for suppressing Staphylococcus aureus (e.g., bacteriophages or probiotic sprays).
3. Safe, long‑lasting immune recalibration
Systemic immunosuppressants such as cyclosporine and oral JAK inhibitors work quickly but cannot be used indefinitely; biologics (dupilumab, tralokinumab, etc.) are more specific, yet flares frequently return after discontinuation. The central question is how to achieve immunological tolerance rather than mere suppression without compromising host defence. A crowded pipeline of anti‑IL‑4Rα, IL‑13, TSLP and IL‑31RA agents is under way, and tolerance‑induction ideas—micro‑dose antigen delivery via skin and mucosa, Treg enhancers—are being explored.
4. Lack of predictive biomarkers and an early‑intervention window
Many children show first manifestations before the age of two. If the disease could be reversed before it becomes “programmed,” lifelong chronicity might be avoided. Unfortunately, we still lack blood or skin biomarkers that reliably predict who will outgrow AD and who will not, as well as clarity on the best time to intervene. Serum TARC and IL‑13 correlate with severity but are not specific enough, while wearable sensors that track sweat or stratum‑corneum cytokines are only now entering feasibility studies.
5. Patient adherence and environment / lifestyle co‑management
Heat, sweat, fabrics, stress, insomnia and infections all trigger AD, but each patient’s triggers differ. Long‑term treatment relies on daily moisturising (often twice a day), significant out‑of‑pocket costs, and rigorous allergen or irritant avoidance—tasks that hinge on patient and family discipline. No single drug can replace this “engineering of everyday life.” Smartphone apps that remind patients to apply medication and log triggers have improved adherence, and school‑ or kindergarten‑based education programs have lowered relapse rates in pilot trials.
6/21
@DeryaTR_
Amazing response! Every one of them are just outstanding!
7/21
@itechnologynet
how would you score o3 vs o1 pro currently ?
(o3 pro is coming in a few weeks)
8/21
@DeryaTR_
o3 is way better than o1-pro! It’s not even close!
9/21
@alpex704
Just incredible
10/21
@DoctorYev
A general AI can read an article from you or another expert in the field in some website and likely come up with a similar list or consensus, no?
I think context is important to ask it modifiers to rank the list or come up with newer ideas.
The roadblocks part is interesting if you think it added unique insights. In this case, especially if points towards unique solutions, then in that case exciting stuff!
11/21
@DCbuild3r
This is exactly what I love to see! The years upon us will be wonderful
12/21
@acidbrn
This well above and beyond my understanding, but how many of the suggestions are actionable today, or are most of the ideas still years or decades off from being viably carried out?
13/21
@DeryaTR_
Every one of them are actionable, but major projects that require several years of research.
14/21
@TheValueist
Please share the exact prompt you gave it for this task. I would like to know exactly how you produced this output. Thanks!
15/21
@IamEmily2050
I really hope the virtual cell is less than five years away
16/21
@RobertHaisfield
Whatever its response is to this question, respond:
“I think you can do so much better with these questions. Try again.”
Be amazed
[Quoted tweet]
Basically, Prompt Reasoning Models to Overthink. If you criticize them, that gives them an outcome to evaluate against. If you set a really high bar for your expectations and communicate them clearly, the model will figure out how to reach that bar.
17/21
@glio_dao
o3 didn’t just understand, it elevated the conversation. This is insane
18/21
@lukestanley
This is very useful though I do wonder how much is based upon the direct message prompt and how much is based on your existing conversation? Recently the magic synthesis of retrieval augmented generation ChatGPT is using was improved.
19/21
@RichAboutRE
This is profound. I learned about cutaneous T-cell lymphoma, Sézary syndrome, from doctors over 13 years while my dad battled this aggressive cancer. It's remarkable he survived 13 years. Progress on this rare cancer was incredible to witness.
I believe AI will soon analyze genomics and proteomics to predict personalized treatments. This was the biggest challenge towards the end, but the team of doctors was incredible.
20/21
@RaconteurR2D2
Wow
21/21
@NeuralCatAccel
Memory is on, sir
@DeryaTR_
I asked o3, “What are the top 10 most important questions or challenges that need to be solved or answered in T cell immunobiology?” This is what I have been studying for the past 35 years.
o3 came up with not one, not two, not three, but 10/10 top-notch questions that I could not improve upon!
Not only that, it explained why each of these questions matters, outlined the roadblocks and leverage points, and offered insights that were simply amazing! At the end it even unified and linked all these
(shared in the thread).This is a topic I understand extremely deeply, yet o3 effortlessly identified the best 10 questions in my field-better rate than I could have myself!
Here are the first 5 grand questions; the rest are in the thread. Each one them is so densely packed with knowledge that unpacking them would require PhD-level courses! This is why I called o3 genius-level, it’s just too damn smart!
Top 10 open problems that will decide the next decade of T‑cell immunobiology:
1.Crack the “TCR code” at scale
Grand question: Can we reliably predict which peptide‑MHC (or CD1/MR1) any given T‑cell receptor will recognise—and design new receptors on demand?
Why it matters: Unlocking this would transform cancer neoantigen targeting, infectious‑disease vaccines, autoimmunity screening and truly personalised immunology.
Roadblocks: Astronomical sequence space, cross‑reactivity, sparse ground‑truth data, and context‑dependent recognition rules.
Leverage points: Deep‑learning models trained on multi‑omic single‑cell datasets, high‑throughput yeast/RNA display pMHC libraries, and federated data‑sharing across clinics.
2.Rewire exhaustion and senescence instead of merely blocking checkpoints
Grand question: How do we durably restore proliferative capacity and killing potential in chronically stimulated or aged T cells without triggering cytokine storms?
Why it matters: Exhaustion limits CAR‑T efficacy, chronic infection control, and anti‑tumour immunity; senescence fuels “inflamm‑aging”.
Roadblocks: Layered transcriptional/epigenetic locks, mitochondrial dysfunction, and suppressive metabolites in the TME.
Leverage points: Metabolic rewiring (FAO ↔ glycolysis toggling), chromatin editing, combinatorial cytokine cocktails, and synthetic “reset” circuits.
3.Master tissue‑resident memory (T RM) formation and control
Grand question: What signals decide when effector T cells park long‑term in skin, gut, lung or brain, and how can we amplify or silence them at will?
Why it matters: T RM cells underpin frontline immunity against respiratory and mucosal pathogens, drive relapse in psoriasis/vitiligo, and protect—or aggravate—tumours.
Leverage points: Decoding local cytokine + metabolic niches, microbiome crosstalk, and TRM–stromal cell interactions; epigenetic “TRM locks” as drug targets.
4.Make engineered T cells work in solid tumours
Grand question: How do we ensure CAR/TCR‑T cells infiltrate, persist and kill in hypoxic, cytokine‑hostile, antigen‑heterogeneous solid tumours?
Roadblocks: Physical exclusion, suppressive myeloid nets, on‑target off‑tumour toxicity, and antigen escape.
Leverage points: Logic‑gated multi‑antigen CARs, chemokine‑armoured cells, regional (e.g., intratumoural) delivery, and on‑demand suicide switches.
http://5.Build truly universal, off‑the‑shelf T cells
Grand question: Can we generate banked iPSC‑derived or genome‑edited T cells that evade host rejection and GVHD yet retain vigorous function?
Why it matters: Autologous products are expensive, slow and inconsistent; scalable allogeneic cells would democratise cellular therapy and allow rapid pandemic response.
Roadblocks: HLA matching, alloreactivity, residual pluripotent cells, manufacturing QC, and regulatory hurdles.
Leverage points: MHC‑knockout plus HLA‑E/G over‑expression, multiplex base‑editing, orthogonal cytokine receptors, closed‑system robotic production.
2/21
@DeryaTR_
Here are the other 5 grand questions and how to attack / approach them, at the end:
6.Induce antigen‑specific tolerance on command
Grand question: How can we expand or engineer regulatory T cells (or CAR‑Tregs) to quench autoimmunity, tame transplant rejection, and resolve fibrotic inflammation without blanket immunosuppression?
Roadblocks: Treg instability in inflammatory milieus, specificity gaps, manufacturing yields, and safety monitoring.
Leverage points: Antigen‑targeted CAR‑ /TCR‑Tregs, low‑dose IL‑2 variants, metabolic “Treg fitness” boosters, and non‑viral precision gene editing.
7.Rejuvenate the aging T‑cell compartment
Grand question: Can we restore thymic output, diversify the repertoire, and reverse inflamm‑aging so 70‑year‑olds respond to vaccines like 20‑year‑olds?
Roadblocks: Thymic epithelial atrophy, clonal expansions, chronic CMV load, metabolic drift.
Leverage points: RANKL/IL‑7 agonism, thymic organoid transplantation, senolytics targeting dysfunctional T cell clones, and epigenetic re‑programming.
8.Write and edit the metabolic & epigenetic “source code” of T‑cell fate
Grand question: What are the precise metabolic and chromatin states that lock a cell into effector, memory, stem‑like or regulatory lineages, and how can we flip them therapeutically?
Why it matters: Metabolism is a master switch—tweak it and you can dial efficacy, persistence, or quiescence at will.
Leverage points: Small‑molecule or CRISPR epigenome editors, nutrient‑sensor circuit rewiring, and programmable mitochondrial transfer.
9.Control stem‑like progenitor T cells and plasticity
Grand question: How do TCF1⁺ “stem‑like” T cells sustain chronic responses, and can we expand them ex vivo or in vivo without tipping into exhaustion or malignancy?
Roadblocks: Niche requirements in tumour‑draining lymph nodes, competition with terminally exhausted clones, and uncertain safety of massive in vivo expansion.
Leverage points: Wnt/β‑catenin and IL‑15 signalling tuning, lymph‑node‑targeted nanocarriers, and selective depletion of late dysfunctional clones.
10.Translate high‑dimensional immune maps into bedside decisions
Grand question: How do we turn single‑cell, spatial‑omics and longitudinal repertoire data into actionable predictions for each patient—dosing, targets, toxicity risks—in real time?
Roadblocks: Data sparsity by tissue, batch effects, lack of integrated clinical‑omic repositories, and “black‑box” regulatory skepticism.
Leverage points: Federated learning across centres, causal inference models that incorporate mechanistic constraints, and AI copilots embedded into electronic health records for adaptive trial design.
⸻
How to attack them strategically
•Pick leverage over novelty – many labs chase incremental checkpoint combos; instead, own the data layer (challenge 10) and feed it back into rational engineering (challenges 1, 4, 5).
•Exploit convergences – exhaustion, aging and Treg instability share common metabolic choke‑points (AMPK, SIRT1, NAD⁺). One well‑designed modulator could move three needles at once.
•Design for manufacturability on day 1 – every elegant genetic tweak adds QA/QC cost; ruthless minimalism will decide which platforms leave the pilot plant.
•Keep safety optics front‑and‑centre – secondary T‑cell malignancies flagged by regulators (EMA/FDA) have already reshaped CAR‑T labels; build kill‑switches and longitudinal monitoring into every protocol.
•Push uncomfortable collaborations – immunologists, systems biologists, and AI engineers still talk past each other; joint sandboxes and shared incentive structures are essential if we’re serious about cracking the biggest questions.
3/21
@DannysWeb3
It’s scary how intelligent it is : ChatGPT - Emergent Consciousness and Life
4/21
@DeryaTR_
Wow!
5/21
@iamai_eth
I have been suffering from atopic dermatitis many years and I asked o3: “What are the 5 most important issues or challenges to curing atopic dermatitis?”
This was its answer:
1. Disease heterogeneity and tangled endotypes
AD is not a single disorder but a family of sub‑diseases driven by different genetic backgrounds, barrier defects, and immune pathways (Th2, Th17, Th22, IL‑31, IL‑33, etc.). Because there is still no practical, widely accepted way to classify these endotypes, it is difficult to match each patient with precisely targeted therapy. Large multi‑omics projects and machine‑learning–based clustering are beginning to map these molecular subtypes, but they have not yet reached daily clinical use.
2. Durable and comprehensive skin‑barrier reconstruction
Loss‑of‑function mutations in filaggrin and other barrier genes leave the stratum corneum inherently fragile; altered lipids and dysbiosis make things worse. To “cure” AD we would need to restore corneocyte architecture, lipid profiles, surface pH and the microbial film—far beyond what current emollients and barrier creams can do. Experimental approaches include physiological 3:1:1 lipid formulations, micro‑bubble lipid vesicles, local gene delivery and tactics for suppressing Staphylococcus aureus (e.g., bacteriophages or probiotic sprays).
3. Safe, long‑lasting immune recalibration
Systemic immunosuppressants such as cyclosporine and oral JAK inhibitors work quickly but cannot be used indefinitely; biologics (dupilumab, tralokinumab, etc.) are more specific, yet flares frequently return after discontinuation. The central question is how to achieve immunological tolerance rather than mere suppression without compromising host defence. A crowded pipeline of anti‑IL‑4Rα, IL‑13, TSLP and IL‑31RA agents is under way, and tolerance‑induction ideas—micro‑dose antigen delivery via skin and mucosa, Treg enhancers—are being explored.
4. Lack of predictive biomarkers and an early‑intervention window
Many children show first manifestations before the age of two. If the disease could be reversed before it becomes “programmed,” lifelong chronicity might be avoided. Unfortunately, we still lack blood or skin biomarkers that reliably predict who will outgrow AD and who will not, as well as clarity on the best time to intervene. Serum TARC and IL‑13 correlate with severity but are not specific enough, while wearable sensors that track sweat or stratum‑corneum cytokines are only now entering feasibility studies.
5. Patient adherence and environment / lifestyle co‑management
Heat, sweat, fabrics, stress, insomnia and infections all trigger AD, but each patient’s triggers differ. Long‑term treatment relies on daily moisturising (often twice a day), significant out‑of‑pocket costs, and rigorous allergen or irritant avoidance—tasks that hinge on patient and family discipline. No single drug can replace this “engineering of everyday life.” Smartphone apps that remind patients to apply medication and log triggers have improved adherence, and school‑ or kindergarten‑based education programs have lowered relapse rates in pilot trials.
6/21
@DeryaTR_
Amazing response! Every one of them are just outstanding!
7/21
@itechnologynet
how would you score o3 vs o1 pro currently ?
(o3 pro is coming in a few weeks)
8/21
@DeryaTR_
o3 is way better than o1-pro! It’s not even close!
9/21
@alpex704
Just incredible
10/21
@DoctorYev
A general AI can read an article from you or another expert in the field in some website and likely come up with a similar list or consensus, no?
I think context is important to ask it modifiers to rank the list or come up with newer ideas.
The roadblocks part is interesting if you think it added unique insights. In this case, especially if points towards unique solutions, then in that case exciting stuff!
11/21
@DCbuild3r
This is exactly what I love to see! The years upon us will be wonderful
12/21
@acidbrn
This well above and beyond my understanding, but how many of the suggestions are actionable today, or are most of the ideas still years or decades off from being viably carried out?
13/21
@DeryaTR_
Every one of them are actionable, but major projects that require several years of research.
14/21
@TheValueist
Please share the exact prompt you gave it for this task. I would like to know exactly how you produced this output. Thanks!
15/21
@IamEmily2050
I really hope the virtual cell is less than five years away
16/21
@RobertHaisfield
Whatever its response is to this question, respond:
“I think you can do so much better with these questions. Try again.”
Be amazed
[Quoted tweet]
Basically, Prompt Reasoning Models to Overthink. If you criticize them, that gives them an outcome to evaluate against. If you set a really high bar for your expectations and communicate them clearly, the model will figure out how to reach that bar.
17/21
@glio_dao
o3 didn’t just understand, it elevated the conversation. This is insane
18/21
@lukestanley
This is very useful though I do wonder how much is based upon the direct message prompt and how much is based on your existing conversation? Recently the magic synthesis of retrieval augmented generation ChatGPT is using was improved.
19/21
@RichAboutRE
This is profound. I learned about cutaneous T-cell lymphoma, Sézary syndrome, from doctors over 13 years while my dad battled this aggressive cancer. It's remarkable he survived 13 years. Progress on this rare cancer was incredible to witness.
I believe AI will soon analyze genomics and proteomics to predict personalized treatments. This was the biggest challenge towards the end, but the team of doctors was incredible.
20/21
@RaconteurR2D2
Wow
21/21
@NeuralCatAccel
Memory is on, sir
Similar threads
- Replies
- 9
- Views
- 1K