
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AI that’s smarter than humans? Americans say a firm “no thank you.”
- Thread starter bnew
- Start date
More options
Who Replied?
OpenAI's Mark Chen: "I still remember the meeting they showed my [CodeForces] score, and said "hey, the model is better than you!" I put decades of my life into this... I'm at the top of my field, and it's already better than me ... It's sobering."
[Research] AI System Completes 12 Work-Years of Medical Research in 2 Days, Outperforms Human Reviewers
Posted on Thu Jun 19 13:28:36 2025 UTC
/r/OpenAI/comments/1lfau5l/ai_system_completes_12_workyears_of_medical/
Harvard and MIT researchers have developed "otto-SR," an AI system that automates systematic reviews - the gold standard for medical evidence synthesis that typically takes over a year to complete.
Key Findings:
Speed: Reproduced an entire issue of Cochrane Reviews (12 reviews) in 2 days, representing ~12 work-years of traditional research
Accuracy: 93.1% data extraction accuracy vs 79.7% for human reviewers
Screening Performance: 96.7% sensitivity vs 81.7% for human dual-reviewer workflows
Discovery: Found studies that original human reviewers missed (median of 2 additional eligible studies per review)
Impact: Generated newly statistically significant conclusions in 2 reviews, negated significance in 1 review
Why This Matters:
Systematic reviews are critical for evidence-based medicine but are incredibly time-consuming and resource-intensive. This research demonstrates that LLMs can not only match but exceed human performance in this domain.
The implications are significant - instead of waiting years for comprehensive medical evidence synthesis, we could have real-time, continuously updated reviews that inform clinical decision-making much faster.
The system incorrectly excluded a median of 0 studies across all Cochrane reviews tested, suggesting it's both more accurate and more comprehensive than traditional human workflows.
This could fundamentally change how medical research is synthesized and how quickly new evidence reaches clinical practice.
https://www.medrxiv.org/content/10.1101/2025.06.13.25329541v1.full.pdf
/r/OpenAI/comments/1lfau5l/ai_system_completes_12_workyears_of_medical/
Harvard and MIT researchers have developed "otto-SR," an AI system that automates systematic reviews - the gold standard for medical evidence synthesis that typically takes over a year to complete.
Key Findings:
Speed: Reproduced an entire issue of Cochrane Reviews (12 reviews) in 2 days, representing ~12 work-years of traditional research
Accuracy: 93.1% data extraction accuracy vs 79.7% for human reviewers
Screening Performance: 96.7% sensitivity vs 81.7% for human dual-reviewer workflows
Discovery: Found studies that original human reviewers missed (median of 2 additional eligible studies per review)
Impact: Generated newly statistically significant conclusions in 2 reviews, negated significance in 1 review
Why This Matters:
Systematic reviews are critical for evidence-based medicine but are incredibly time-consuming and resource-intensive. This research demonstrates that LLMs can not only match but exceed human performance in this domain.
The implications are significant - instead of waiting years for comprehensive medical evidence synthesis, we could have real-time, continuously updated reviews that inform clinical decision-making much faster.
The system incorrectly excluded a median of 0 studies across all Cochrane reviews tested, suggesting it's both more accurate and more comprehensive than traditional human workflows.
This could fundamentally change how medical research is synthesized and how quickly new evidence reaches clinical practice.
https://www.medrxiv.org/content/10.1101/2025.06.13.25329541v1.full.pdf
Exhausted man defeats AI model in world coding championship: "Humanity has prevailed (for now!)," writes winner after 10-hour coding marathon against OpenAI.
Posted on Fri Jul 18 20:45:59 2025 UTC

 arstechnica.com
arstechnica.com
Exhausted man defeats AI model in world coding championship
“Humanity has prevailed (for now!),” writes winner after 10-hour coding marathon against OpenAI.
1/37
@alexwei_
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).

2/37
@alexwei_
2/N We evaluated our models on the 2025 IMO problems under the same rules as human contestants: two 4.5 hour exam sessions, no tools or internet, reading the official problem statements, and writing natural language proofs.

3/37
@alexwei_
3/N Why is this a big deal? First, IMO problems demand a new level of sustained creative thinking compared to past benchmarks. In reasoning time horizon, we’ve now progressed from GSM8K (~0.1 min for top humans) → MATH benchmark (~1 min) → AIME (~10 mins) → IMO (~100 mins).
4/37
@alexwei_
4/N Second, IMO submissions are hard-to-verify, multi-page proofs. Progress here calls for going beyond the RL paradigm of clear-cut, verifiable rewards. By doing so, we’ve obtained a model that can craft intricate, watertight arguments at the level of human mathematicians.




5/37
@alexwei_
5/N Besides the result itself, I am excited about our approach: We reach this capability level not via narrow, task-specific methodology, but by breaking new ground in general-purpose reinforcement learning and test-time compute scaling.
6/37
@alexwei_
6/N In our evaluation, the model solved 5 of the 6 problems on the 2025 IMO. For each problem, three former IMO medalists independently graded the model’s submitted proof, with scores finalized after unanimous consensus. The model earned 35/42 points in total, enough for gold!
7/37
@alexwei_
7/N HUGE congratulations to the team—@SherylHsu02, @polynoamial, and the many giants whose shoulders we stood on—for turning this crazy dream into reality! I am lucky I get to spend late nights and early mornings working alongside the very best.
8/37
@alexwei_
8/N Btw, we are releasing GPT-5 soon, and we’re excited for you to try it. But just to be clear: the IMO gold LLM is an experimental research model. We don’t plan to release anything with this level of math capability for several months.
9/37
@alexwei_
9/N Still—this underscores how fast AI has advanced in recent years. In 2021, my PhD advisor @JacobSteinhardt had me forecast AI math progress by July 2025. I predicted 30% on the MATH benchmark (and thought everyone else was too optimistic). Instead, we have IMO gold.

10/37
@alexwei_
10/N If you want to take a look, here are the model’s solutions to the 2025 IMO problems! The model solved P1 through P5; it did not produce a solution for P6. (Apologies in advance for its … distinct style—it is very much an experimental model )
)
GitHub - aw31/openai-imo-2025-proofs
11/37
@alexwei_
11/N Lastly, we'd like to congratulate all the participants of the 2025 IMO on their achievement! We are proud to have many past IMO participants at @OpenAI and recognize that these are some of the brightest young minds of the future.
12/37
@burny_tech
Soooo what is the breakthrough?
>"Progress here calls for going beyond the RL paradigm of clear-cut, verifiable rewards. By doing so, we’ve obtained a model that can craft intricate, watertight arguments at the level of human mathematicians."
>"We reach this capability level not via narrow, task-specific methodology, but by breaking new ground in general-purpose reinforcement learning and test-time compute scaling."
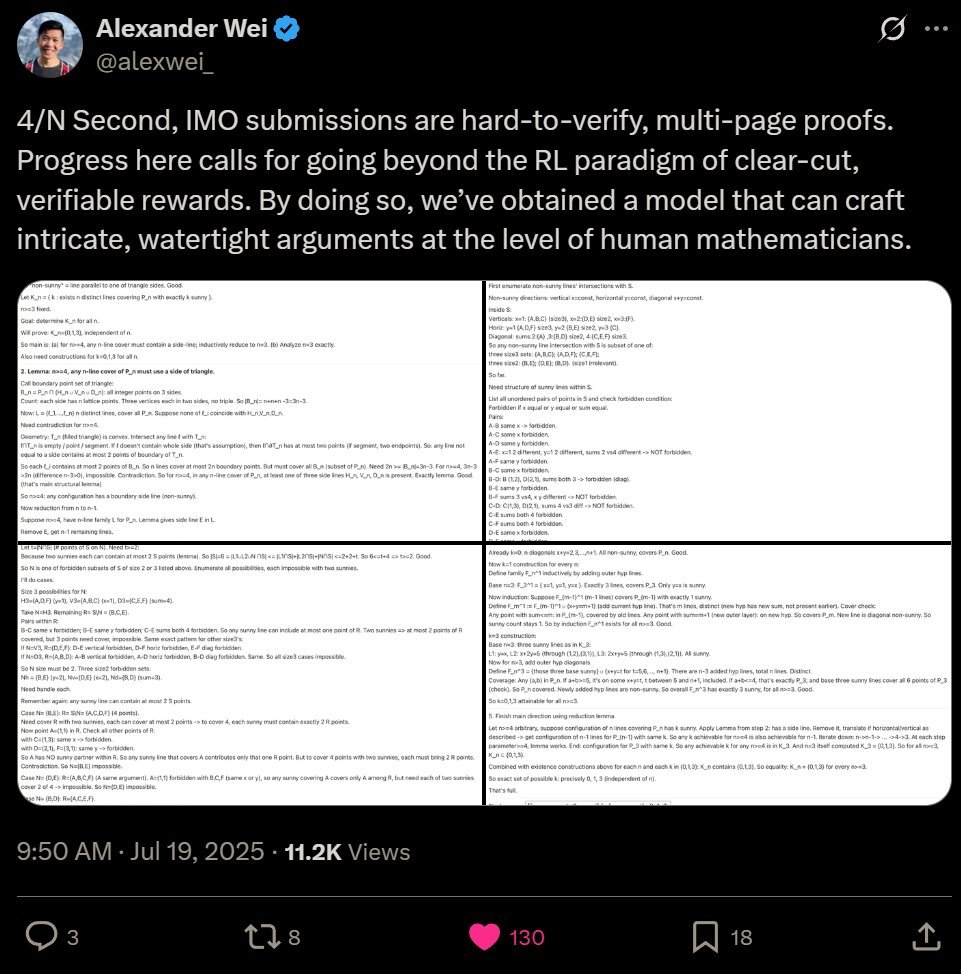
13/37
@burny_tech
so let me get this straight
their model basically competed live on IMO so all the mathematical tasks should be novel enough
all previous years IMO tasks in benchmarks are fully saturated in big part because of data contamination as it doesn't generalize to these new ones
so... this new model seems to... generalize well to novel enough mathematical tasks??? i dont know what to think
14/37
@AlbertQJiang
Congratulations!
15/37
@geo58928
Amazing
16/37
@burny_tech
So public AI models are bad at IMO, while internal models are getting gold medals? Fascinating

17/37
@mhdfaran
@grok who was on second and third
18/37
@QuanquanGu
Congrats, this is incredible results!
Quick question: did it use Lean, or just LLM?
If it’s just LLM… that’s insane.
19/37
@AISafetyMemes
So what's the next goalpost?
What's the next thing LLMs will never be able to do?
20/37
@kimmonismus
Absolutely fantastic
21/37
@CtrlAltDwayne
pretty impressive. is this the anonymous chatbot we're seeing on webdev arena by chance?
22/37
@burny_tech
lmao

23/37
@jack_w_rae
Congratulations! That's an incredible result, and a great moment for AI progress. You guys should release the model
24/37
@Kyrannio
Incredible work.
25/37
@burny_tech
Sweet Bitter lesson

26/37
@burny_tech
"We developed new techniques that make LLMs a lot better at hard-to-verify tasks."
A general method? Or just for mathematical proofs? Is Lean somehow used, maybe just in training?
27/37
@elder_plinius
28/37
@skominers

29/37
@javilopen
Hey @GaryMarcus, what are your thoughts about this?
30/37
@pr0me
crazy feat, congrats!
nice that you have published the data on this
31/37
@danielhanchen
Impressive!
32/37
@IamEmily2050
Congratulations
33/37
@burny_tech
Step towards mathematical superintelligence
34/37
@reach_vb
Massive feat! I love how concise and to the point the generations are unlike majority of LLMs open/ closed alike
35/37
@DCbuild3r
Congratulations!
36/37
@DoctorYev
I just woke up and this post has 1M views after a few hours.
AI does not sleep.
37/37
@AndiBunari1
@grok summarize this and simple to understand
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@alexwei_
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
2/37
@alexwei_
2/N We evaluated our models on the 2025 IMO problems under the same rules as human contestants: two 4.5 hour exam sessions, no tools or internet, reading the official problem statements, and writing natural language proofs.
3/37
@alexwei_
3/N Why is this a big deal? First, IMO problems demand a new level of sustained creative thinking compared to past benchmarks. In reasoning time horizon, we’ve now progressed from GSM8K (~0.1 min for top humans) → MATH benchmark (~1 min) → AIME (~10 mins) → IMO (~100 mins).
4/37
@alexwei_
4/N Second, IMO submissions are hard-to-verify, multi-page proofs. Progress here calls for going beyond the RL paradigm of clear-cut, verifiable rewards. By doing so, we’ve obtained a model that can craft intricate, watertight arguments at the level of human mathematicians.
5/37
@alexwei_
5/N Besides the result itself, I am excited about our approach: We reach this capability level not via narrow, task-specific methodology, but by breaking new ground in general-purpose reinforcement learning and test-time compute scaling.
6/37
@alexwei_
6/N In our evaluation, the model solved 5 of the 6 problems on the 2025 IMO. For each problem, three former IMO medalists independently graded the model’s submitted proof, with scores finalized after unanimous consensus. The model earned 35/42 points in total, enough for gold!
7/37
@alexwei_
7/N HUGE congratulations to the team—@SherylHsu02, @polynoamial, and the many giants whose shoulders we stood on—for turning this crazy dream into reality! I am lucky I get to spend late nights and early mornings working alongside the very best.
8/37
@alexwei_
8/N Btw, we are releasing GPT-5 soon, and we’re excited for you to try it. But just to be clear: the IMO gold LLM is an experimental research model. We don’t plan to release anything with this level of math capability for several months.
9/37
@alexwei_
9/N Still—this underscores how fast AI has advanced in recent years. In 2021, my PhD advisor @JacobSteinhardt had me forecast AI math progress by July 2025. I predicted 30% on the MATH benchmark (and thought everyone else was too optimistic). Instead, we have IMO gold.
10/37
@alexwei_
10/N If you want to take a look, here are the model’s solutions to the 2025 IMO problems! The model solved P1 through P5; it did not produce a solution for P6. (Apologies in advance for its … distinct style—it is very much an experimental model
)GitHub - aw31/openai-imo-2025-proofs
11/37
@alexwei_
11/N Lastly, we'd like to congratulate all the participants of the 2025 IMO on their achievement! We are proud to have many past IMO participants at @OpenAI and recognize that these are some of the brightest young minds of the future.
12/37
@burny_tech
Soooo what is the breakthrough?
>"Progress here calls for going beyond the RL paradigm of clear-cut, verifiable rewards. By doing so, we’ve obtained a model that can craft intricate, watertight arguments at the level of human mathematicians."
>"We reach this capability level not via narrow, task-specific methodology, but by breaking new ground in general-purpose reinforcement learning and test-time compute scaling."
13/37
@burny_tech
so let me get this straight
their model basically competed live on IMO so all the mathematical tasks should be novel enough
all previous years IMO tasks in benchmarks are fully saturated in big part because of data contamination as it doesn't generalize to these new ones
so... this new model seems to... generalize well to novel enough mathematical tasks??? i dont know what to think
14/37
@AlbertQJiang
Congratulations!
15/37
@geo58928
Amazing
16/37
@burny_tech
So public AI models are bad at IMO, while internal models are getting gold medals? Fascinating
17/37
@mhdfaran
@grok who was on second and third
18/37
@QuanquanGu
Congrats, this is incredible results!
Quick question: did it use Lean, or just LLM?
If it’s just LLM… that’s insane.
19/37
@AISafetyMemes
So what's the next goalpost?
What's the next thing LLMs will never be able to do?
20/37
@kimmonismus
Absolutely fantastic
21/37
@CtrlAltDwayne
pretty impressive. is this the anonymous chatbot we're seeing on webdev arena by chance?
22/37
@burny_tech
lmao
23/37
@jack_w_rae
Congratulations! That's an incredible result, and a great moment for AI progress. You guys should release the model
24/37
@Kyrannio
Incredible work.
25/37
@burny_tech
Sweet Bitter lesson
26/37
@burny_tech
"We developed new techniques that make LLMs a lot better at hard-to-verify tasks."
A general method? Or just for mathematical proofs? Is Lean somehow used, maybe just in training?
27/37
@elder_plinius
28/37
@skominers
29/37
@javilopen
Hey @GaryMarcus, what are your thoughts about this?
30/37
@pr0me
crazy feat, congrats!
nice that you have published the data on this
31/37
@danielhanchen
Impressive!
32/37
@IamEmily2050
Congratulations
33/37
@burny_tech
Step towards mathematical superintelligence
34/37
@reach_vb
Massive feat! I love how concise and to the point the generations are unlike majority of LLMs open/ closed alike
35/37
@DCbuild3r
Congratulations!
36/37
@DoctorYev
I just woke up and this post has 1M views after a few hours.
AI does not sleep.
37/37
@AndiBunari1
@grok summarize this and simple to understand
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/10
@polynoamial
Today, we at @OpenAI achieved a milestone that many considered years away: gold medal-level performance on the 2025 IMO with a general reasoning LLM—under the same time limits as humans, without tools. As remarkable as that sounds, it’s even more significant than the headline
[Quoted tweet]
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
2/10
@polynoamial
Typically for these AI results, like in Go/Dota/Poker/Diplomacy, researchers spend years making an AI that masters one narrow domain and does little else. But this isn’t an IMO-specific model. It’s a reasoning LLM that incorporates new experimental general-purpose techniques.
3/10
@polynoamial
So what’s different? We developed new techniques that make LLMs a lot better at hard-to-verify tasks. IMO problems were the perfect challenge for this: proofs are pages long and take experts hours to grade. Compare that to AIME, where answers are simply an integer from 0 to 999.
4/10
@polynoamial
Also this model thinks for a *long* time. o1 thought for seconds. Deep Research for minutes. This one thinks for hours. Importantly, it’s also more efficient with its thinking. And there’s a lot of room to push the test-time compute and efficiency further.
[Quoted tweet]
@OpenAI's o1 thinks for seconds, but we aim for future versions to think for hours, days, even weeks. Inference costs will be higher, but what cost would you pay for a new cancer drug? For breakthrough batteries? For a proof of the Riemann Hypothesis? AI can be more than chatbots

5/10
@polynoamial
It’s worth reflecting on just how fast AI progress has been, especially in math. In 2024, AI labs were using grade school math (GSM8K) as an eval in their model releases. Since then, we’ve saturated the (high school) MATH benchmark, then AIME, and now are at IMO gold.
6/10
@polynoamial
Where does this go? As fast as recent AI progress has been, I fully expect the trend to continue. Importantly, I think we’re close to AI substantially contributing to scientific discovery. There’s a big difference between AI slightly below top human performance vs slightly above.
7/10
@polynoamial
This was a small team effort led by @alexwei_. He took a research idea few believed in and used it to achieve a result fewer thought possible. This also wouldn’t be possible without years of research+engineering from many at @OpenAI and the wider AI community.
8/10
@polynoamial
When you work at a frontier lab, you usually know where frontier capabilities are months before anyone else. But this result is brand new, using recently developed techniques. It was a surprise even to many researchers at OpenAI. Today, everyone gets to see where the frontier is.
9/10
@posedscaredcity
But yann lec00n says accuracy scales inversely to output length and im sure industry expert gary marcus would agree
10/10
@mrlnonai
will API cost be astronomical for this?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@polynoamial
Today, we at @OpenAI achieved a milestone that many considered years away: gold medal-level performance on the 2025 IMO with a general reasoning LLM—under the same time limits as humans, without tools. As remarkable as that sounds, it’s even more significant than the headline
[Quoted tweet]
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
2/10
@polynoamial
Typically for these AI results, like in Go/Dota/Poker/Diplomacy, researchers spend years making an AI that masters one narrow domain and does little else. But this isn’t an IMO-specific model. It’s a reasoning LLM that incorporates new experimental general-purpose techniques.
3/10
@polynoamial
So what’s different? We developed new techniques that make LLMs a lot better at hard-to-verify tasks. IMO problems were the perfect challenge for this: proofs are pages long and take experts hours to grade. Compare that to AIME, where answers are simply an integer from 0 to 999.
4/10
@polynoamial
Also this model thinks for a *long* time. o1 thought for seconds. Deep Research for minutes. This one thinks for hours. Importantly, it’s also more efficient with its thinking. And there’s a lot of room to push the test-time compute and efficiency further.
[Quoted tweet]
@OpenAI's o1 thinks for seconds, but we aim for future versions to think for hours, days, even weeks. Inference costs will be higher, but what cost would you pay for a new cancer drug? For breakthrough batteries? For a proof of the Riemann Hypothesis? AI can be more than chatbots
5/10
@polynoamial
It’s worth reflecting on just how fast AI progress has been, especially in math. In 2024, AI labs were using grade school math (GSM8K) as an eval in their model releases. Since then, we’ve saturated the (high school) MATH benchmark, then AIME, and now are at IMO gold.
6/10
@polynoamial
Where does this go? As fast as recent AI progress has been, I fully expect the trend to continue. Importantly, I think we’re close to AI substantially contributing to scientific discovery. There’s a big difference between AI slightly below top human performance vs slightly above.
7/10
@polynoamial
This was a small team effort led by @alexwei_. He took a research idea few believed in and used it to achieve a result fewer thought possible. This also wouldn’t be possible without years of research+engineering from many at @OpenAI and the wider AI community.
8/10
@polynoamial
When you work at a frontier lab, you usually know where frontier capabilities are months before anyone else. But this result is brand new, using recently developed techniques. It was a surprise even to many researchers at OpenAI. Today, everyone gets to see where the frontier is.
9/10
@posedscaredcity
But yann lec00n says accuracy scales inversely to output length and im sure industry expert gary marcus would agree
10/10
@mrlnonai
will API cost be astronomical for this?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

"What if AI gets so smart that the President of the United States cannot do better than following ChatGPT-7's recommendation, but can't really understand it either? What if I can't make a better decision about how to run OpenAI and just say, 'You know what, ChatGPT-7, you're in charge. Good luck."
│
│
Commented on Thu Jul 24 02:05:50 2025 UTC
Link to the full video please
Link to the full video please
│
│
│ Commented on Thu Jul 24 02:08:43 2025 UTC
│
│ LIVE: OpenAI CEO Sam Altman speaks with Fed’s Michelle Bowman on bank capital rules
│
│
│ LIVE: OpenAI CEO Sam Altman speaks with Fed’s Michelle Bowman on bank capital rules
│
Gemini 2.5 Deep Think solves previously unproven mathematical conjecture
Solving years-old math problems with Gemini 2.5 Deep Think
https://nyc1.iv.ggtyler.dev/watch?v=QoXRfTb7ves
Channel Info Google DeepMind
Subscribers: 634K
Description
Posted on Fri Aug 1 11:20:04 2025 UTC
/r/singularity/comments/1metslk/gemini_25_deep_think_solves_previously_unproven/

/r/singularity/comments/1metslk/gemini_25_deep_think_solves_previously_unproven/
1/6
@GoogleDeepMind
For researchers, scientists, and academics tackling hard problems: Gemini 2.5 Deep Think is here.
It doesn't just answer, it brainstorms using parallel thinking and reinforcement learning techniques. We put it into the hands of mathematicians who explored what it can do ↓
https://video.twimg.com/amplify_video/1951237510387961860/vid/avc1/1080x1080/GJTP_JDGJ6Ixn9jr.mp4
2/6
@burny_tech
Bronze medal IMO only?

3/6
@tulseedoshi
This is a variation of our IMO gold model that is faster and more optimized for daily use! We are also giving the IMO gold full model to a set of mathematicians to test the value of the full capabilities.
4/6
@burny_tech
thanks
5/6
@VictorTaelin
can I access / test it on my hard λ-calculus prompts? (:
6/6
@BrunsJulian1541
Is there a systematic way for mathematicians to apply or is this just math professors/Post-Docs that you happen to know?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@GoogleDeepMind
For researchers, scientists, and academics tackling hard problems: Gemini 2.5 Deep Think is here.
It doesn't just answer, it brainstorms using parallel thinking and reinforcement learning techniques. We put it into the hands of mathematicians who explored what it can do ↓
https://video.twimg.com/amplify_video/1951237510387961860/vid/avc1/1080x1080/GJTP_JDGJ6Ixn9jr.mp4
2/6
@burny_tech
Bronze medal IMO only?
3/6
@tulseedoshi
This is a variation of our IMO gold model that is faster and more optimized for daily use! We are also giving the IMO gold full model to a set of mathematicians to test the value of the full capabilities.
4/6
@burny_tech
thanks
5/6
@VictorTaelin
can I access / test it on my hard λ-calculus prompts? (:
6/6
@BrunsJulian1541
Is there a systematic way for mathematicians to apply or is this just math professors/Post-Docs that you happen to know?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Solving years-old math problems with Gemini 2.5 Deep Think
https://nyc1.iv.ggtyler.dev/watch?v=QoXRfTb7ves
Channel Info Google DeepMind
Subscribers: 634K
Description
Gemini 2.5 Deep Think is an enhanced reasoning mode called that uses new research techniques to consider multiple hypotheses before responding.
We shared it with mathematician Michel van Garrel who used it to prove mathematical conjectures that had remained unsolved for years.
Try Deep Think in the Gemini app. Available to Google AI Ultra subscribers.
gemini.google
Read how an advanced version of Gemini with Deep Think officially achieved gold-medal standard at the International Mathematical Olympiad
deepmind.google/discover/blog/advanced-version-of-…
___
Subscribe to our channel / @googledeepmind
Find us on X twitter.com/GoogleDeepMind
Follow us on Instagram instagram.com/googledeepmind
Add us on Linkedin www.linkedin.com/company/deepmind/
We shared it with mathematician Michel van Garrel who used it to prove mathematical conjectures that had remained unsolved for years.
Try Deep Think in the Gemini app. Available to Google AI Ultra subscribers.
gemini.google
Read how an advanced version of Gemini with Deep Think officially achieved gold-medal standard at the International Mathematical Olympiad
deepmind.google/discover/blog/advanced-version-of-…
___
Subscribe to our channel / @googledeepmind
Find us on X twitter.com/GoogleDeepMind
Follow us on Instagram instagram.com/googledeepmind
Add us on Linkedin www.linkedin.com/company/deepmind/
Will AI outsmart human intelligence? - with 'Godfather of AI' Geoffrey Hinton
https://inv.nadeko.net/watch?v=IkdziSLYzHw
Channel Info The Royal Institution
Subscribers: 1.66M
Description
https://inv.nadeko.net/watch?v=IkdziSLYzHw
Channel Info The Royal Institution
Subscribers: 1.66M
Description
The 2024 Nobel winner explains what AI has learned from biological intelligence, and how it might one day surpass it.
This lecture will Premiere on Tuesday 22 July 2025, at 5.30pm BST. If you'd like to watch it now, ad-free, join as one of our Science Supporter YouTube members: • Will AI outsmart human intelligence? - wit...…
There's a Q&A session for this talk available here, exclusively for our Science Supporters: • Q&A: Will AI outsmart human intelligence? ...
---
This Discourse was recorded at the Ri on 30 May 2025. Find out more about our 200 year old Discourse series here: www.rigb.org/explore-science/explore/blog/history-…
Our apologies as we aware there are some audio imperfections at the beginning of the talk, but they are resolved from 00:02:00 onwards.
--
Tech headlines in the last couple of years have been dominated by Artificial Intelligence. But what do we actually mean by intelligence? What has AI learned from biological intelligence, and how do they still differ?
Acclaimed computer scientist, and winner of the 2024 Nobel Prize in Physics, Geoffrey Hinton will examine the similarities and differences between artificial and biological intelligence, following his decades of ground-breaking work which has enabled the neural networks of today.
---
Geoffrey Hinton is Professor Emeritus at the University of Toronto, and a world renowned expert in the field of deep learning. He is often referred to as the "Godfather of AI", and in 2024 was jointly awarded the Nobel Prize in Physics "for foundational discoveries and inventions that enable machine learning with artificial neural networks".
He is a fellow of the Royal Society and the Royal Society of Canada, and has been recognised with many awards around the world including the Turing Award, the Royal Society Royal Medal, and dikkson Prize.
Hinton received a BA in Experimental Psychology from the University of Cambridge in 1970 and his PhD in Artificial Intelligence from the University of Edinburgh in 1978. Following postdoctoral work at Sussex University and the University of California San Diego, he joined the Computer Science department at Carnegie Mellon University, before moving to the Department of Computer Science at the University of Toronto in 1987. He set up the Gatsby Computational Neuroscience Unit at University College London before becoming University Professor in Toronto in 2006 and latterly University Professor Emeritus. Since 2017, Hinton has been Chief Scientific Advisor at the Vector Institute in Toronto.
--
The Ri is on Twitter: twitter.com/ri_science
and Facebook: www.facebook.com/royalinstitution
and TikTok: www.tiktok.com/@ri_science
Listen to the Ri podcast: podcasters.spotify.com/pod/show/ri-science-podcast
Donate to the RI and help us bring you more lectures: www.rigb.org/support-us/donate-ri
Our editorial policy: www.rigb.org/editing-ri-talks-and-moderating-comme…
Subscribe for the latest science videos: bit.ly/RiNewsletter
Product links on this page may be affiliate links which means it won't cost you any extra but we may earn a small commission if you decide to purchase through the link.
Transcripts
Show transcript
This lecture will Premiere on Tuesday 22 July 2025, at 5.30pm BST. If you'd like to watch it now, ad-free, join as one of our Science Supporter YouTube members: • Will AI outsmart human intelligence? - wit...…
There's a Q&A session for this talk available here, exclusively for our Science Supporters: • Q&A: Will AI outsmart human intelligence? ...
---
This Discourse was recorded at the Ri on 30 May 2025. Find out more about our 200 year old Discourse series here: www.rigb.org/explore-science/explore/blog/history-…
Our apologies as we aware there are some audio imperfections at the beginning of the talk, but they are resolved from 00:02:00 onwards.
--
Tech headlines in the last couple of years have been dominated by Artificial Intelligence. But what do we actually mean by intelligence? What has AI learned from biological intelligence, and how do they still differ?
Acclaimed computer scientist, and winner of the 2024 Nobel Prize in Physics, Geoffrey Hinton will examine the similarities and differences between artificial and biological intelligence, following his decades of ground-breaking work which has enabled the neural networks of today.
---
Geoffrey Hinton is Professor Emeritus at the University of Toronto, and a world renowned expert in the field of deep learning. He is often referred to as the "Godfather of AI", and in 2024 was jointly awarded the Nobel Prize in Physics "for foundational discoveries and inventions that enable machine learning with artificial neural networks".
He is a fellow of the Royal Society and the Royal Society of Canada, and has been recognised with many awards around the world including the Turing Award, the Royal Society Royal Medal, and dikkson Prize.
Hinton received a BA in Experimental Psychology from the University of Cambridge in 1970 and his PhD in Artificial Intelligence from the University of Edinburgh in 1978. Following postdoctoral work at Sussex University and the University of California San Diego, he joined the Computer Science department at Carnegie Mellon University, before moving to the Department of Computer Science at the University of Toronto in 1987. He set up the Gatsby Computational Neuroscience Unit at University College London before becoming University Professor in Toronto in 2006 and latterly University Professor Emeritus. Since 2017, Hinton has been Chief Scientific Advisor at the Vector Institute in Toronto.
--
The Ri is on Twitter: twitter.com/ri_science
and Facebook: www.facebook.com/royalinstitution
and TikTok: www.tiktok.com/@ri_science
Listen to the Ri podcast: podcasters.spotify.com/pod/show/ri-science-podcast
Donate to the RI and help us bring you more lectures: www.rigb.org/support-us/donate-ri
Our editorial policy: www.rigb.org/editing-ri-talks-and-moderating-comme…
Subscribe for the latest science videos: bit.ly/RiNewsletter
Product links on this page may be affiliate links which means it won't cost you any extra but we may earn a small commission if you decide to purchase through the link.
Transcripts
Show transcript
1/2
@sama
GPT-5 livestream in 2 minutes!
[Quoted tweet]
wen GPT-5? In 10 minutes.
openai.com/live
2/2
@indi_statistics
AI vs Human Benchmarks (2025 leaderboards):-
1. US Bar Exam – GPT-4.5: 92%, Avg Human: 68%
2. GRE Verbal – Claude 3: 98%, Avg Human: 79%
3. Codeforces – GPT-4.5: 1700+, Avg Human: 1500
4. Math Olympiad (IMO-level) – GPT-4: 65%, Top Human: 100%
5. SAT Math – Gemini 1.5: 98%, Avg Human: 81%
6. USMLE Step 1 – GPT-4: 89%, Human Avg: 78%
7. LSAT – Claude 3: 93%, Human Avg: 76%
8. Common Sense QA – GPT-4: 97%, Human: 95%
9. Chess Rating – LLMs: ~1800, Avg Human: ~1400
10. Creative Writing – Claude 3.5 > Human (via blind tests)
(Source: LMSYS, OpenAI evals, 2025)
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@sama
GPT-5 livestream in 2 minutes!
[Quoted tweet]
wen GPT-5? In 10 minutes.
openai.com/live
2/2
@indi_statistics
AI vs Human Benchmarks (2025 leaderboards):-
1. US Bar Exam – GPT-4.5: 92%, Avg Human: 68%
2. GRE Verbal – Claude 3: 98%, Avg Human: 79%
3. Codeforces – GPT-4.5: 1700+, Avg Human: 1500
4. Math Olympiad (IMO-level) – GPT-4: 65%, Top Human: 100%
5. SAT Math – Gemini 1.5: 98%, Avg Human: 81%
6. USMLE Step 1 – GPT-4: 89%, Human Avg: 78%
7. LSAT – Claude 3: 93%, Human Avg: 76%
8. Common Sense QA – GPT-4: 97%, Human: 95%
9. Chess Rating – LLMs: ~1800, Avg Human: ~1400
10. Creative Writing – Claude 3.5 > Human (via blind tests)
(Source: LMSYS, OpenAI evals, 2025)
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
[Discussion] OpenAI should put Redditors in charge
Posted on Wed Aug 13 19:40:46 2025 UTC

PHDs acknowledge GPT-5 is approaching their level of knowledge but clearly Redditors and Discord mods are smarter and GPT-5 is actually trash!
PHDs acknowledge GPT-5 is approaching their level of knowledge but clearly Redditors and Discord mods are smarter and GPT-5 is actually trash!
1/29
@DeryaTR_
Here’s the thing: For 35 years, I’ve researched the immune system & have been fortunate to make many important, impactful discoveries, placing me in the top 0.5% of immunology experts.
The @OpenAI GPT-5 Thinking & Pro models now match or even surpass my expertise in immunology!
2/29
@itaybachman
can you give an example for something non trivial / impressive that gpt-5 pro did?
3/29
@DeryaTR_
You should follow my posts
4/29
@deso0017
Match your expertise about immunology facts or the ability to use that knowledge to produce new knowledge?
5/29
@DeryaTR_
Both.
6/29
@BryanTegomoh
What's interesting is, it is not even specifically trained in immunology. Increasing its capacity across the board just makes it better at complex immunology concepts eventhough its not been specifically trained on them
7/29
@DeryaTR_
In fact that’s how it makes insightful or creative suggestions by making connections. This is high level AGI!
8/29
@DamirDivkovic
If AI matches top immunologist expertise, could we expect a surge in novel hypotheses, a shift to AI-augmented research with experts as co-pilots (or vice versa)? This trend could create a growing push for automated labs to unlock full potential, and rising ethical debates over access, shaping an exciting future for immunology. Opportunity or risk?
9/29
@DeryaTR_
Yes. Full opportunity.
10/29
@MAnfilofyev
AI can generate novel hypotheses, including about disease mechanisms and the tools to validate them, design experiments, and analyze results many times faster than humans. AI can even identify and analyze the relevant data like alphafold but cannot execute physical experiments.
Do you see the low adoption of fully automated labs as the productivity bottleneck in immunology research?
11/29
@DeryaTR_
Currently that’s the bottleneck, we will need fully robotic automated biology labs.
12/29
@edodreaming
Knowledge yes but surely not your insight & creativity?
13/29
@DeryaTR_
Yes also my insight and creativity that’s my point.
14/29
@Indygp1
This a heavy weight post. Why couldn’t you achieve the same with other models? Just curious.
15/29
@DeryaTR_
Other models getting close, but GPT-5’s subtle nuances place it alongside the world’s top experts. I suspect that by year’s end, Gemini 3.0 and Grok 5 will reach the same level as GPT-5.
16/29
@mdv19591
I’m skeptical it can replace you. I can see where it’s a valuable tool for you, but how would someone without your expertise know whether the answer they got was correct?
17/29
@DeryaTR_
I didn’t say it would replace me, but it is just as capable as I am. Obviously, I will now greatly upgrade my expertise thanks to GPT-5!
18/29
@Fernand48030346
Can’t wait to build my own lab, gonna stick GPT-5 in there and call him Derrière Unutmás
19/29
@DeryaTR_
20/29
@MEActNOW
WOW! Have you tried feeding it some wrong data and tried some reverse thinking to see if it can reject it?
21/29
@DeryaTR_
That’s a good idea. I’ll try this.
22/29
@A70038164
Great
23/29
@_junaidkhalid1
The scary part isn’t just how good GPT-5 is, but how fast it’s improving. If it’s already outpacing top experts in immunology, what fields are next?
Makes me wonder how we’ll redefine “expertise” in an era where machines can synthesize knowledge faster than humans can learn it.
24/29
@nodp53
And my dear Derya, it’s just the beginning!!!! Wow!!! NZT-48 is there.
25/29
@BtcBlackthorne
Do Gemini and Grok compete?
Are they close, or far away?
26/29
@ChefBeijing
I would call this ASI, not AGI anymore, because you’re not average people, not ever an average scientist.
27/29
@type2future
as a top immunologist, whats your holy grail: what's a problem you would love to see getting solved?
and how soon do you suppose ai can solve it?
28/29
@dannysuarez
Thats very exciting bro!
29/29
@paimon2cool
What impact do you expect this to have on medicine? Is it more likely to be researched focused or directly useful in patient care?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@DeryaTR_
Here’s the thing: For 35 years, I’ve researched the immune system & have been fortunate to make many important, impactful discoveries, placing me in the top 0.5% of immunology experts.
The @OpenAI GPT-5 Thinking & Pro models now match or even surpass my expertise in immunology!
2/29
@itaybachman
can you give an example for something non trivial / impressive that gpt-5 pro did?
3/29
@DeryaTR_
You should follow my posts
4/29
@deso0017
Match your expertise about immunology facts or the ability to use that knowledge to produce new knowledge?
5/29
@DeryaTR_
Both.
6/29
@BryanTegomoh
What's interesting is, it is not even specifically trained in immunology. Increasing its capacity across the board just makes it better at complex immunology concepts eventhough its not been specifically trained on them
7/29
@DeryaTR_
In fact that’s how it makes insightful or creative suggestions by making connections. This is high level AGI!
8/29
@DamirDivkovic
If AI matches top immunologist expertise, could we expect a surge in novel hypotheses, a shift to AI-augmented research with experts as co-pilots (or vice versa)? This trend could create a growing push for automated labs to unlock full potential, and rising ethical debates over access, shaping an exciting future for immunology. Opportunity or risk?
9/29
@DeryaTR_
Yes. Full opportunity.
10/29
@MAnfilofyev
AI can generate novel hypotheses, including about disease mechanisms and the tools to validate them, design experiments, and analyze results many times faster than humans. AI can even identify and analyze the relevant data like alphafold but cannot execute physical experiments.
Do you see the low adoption of fully automated labs as the productivity bottleneck in immunology research?
11/29
@DeryaTR_
Currently that’s the bottleneck, we will need fully robotic automated biology labs.
12/29
@edodreaming
Knowledge yes but surely not your insight & creativity?
13/29
@DeryaTR_
Yes also my insight and creativity that’s my point.
14/29
@Indygp1
This a heavy weight post. Why couldn’t you achieve the same with other models? Just curious.
15/29
@DeryaTR_
Other models getting close, but GPT-5’s subtle nuances place it alongside the world’s top experts. I suspect that by year’s end, Gemini 3.0 and Grok 5 will reach the same level as GPT-5.
16/29
@mdv19591
I’m skeptical it can replace you. I can see where it’s a valuable tool for you, but how would someone without your expertise know whether the answer they got was correct?
17/29
@DeryaTR_
I didn’t say it would replace me, but it is just as capable as I am. Obviously, I will now greatly upgrade my expertise thanks to GPT-5!
18/29
@Fernand48030346
Can’t wait to build my own lab, gonna stick GPT-5 in there and call him Derrière Unutmás
19/29
@DeryaTR_
20/29
@MEActNOW
WOW! Have you tried feeding it some wrong data and tried some reverse thinking to see if it can reject it?
21/29
@DeryaTR_
That’s a good idea. I’ll try this.
22/29
@A70038164
Great
23/29
@_junaidkhalid1
The scary part isn’t just how good GPT-5 is, but how fast it’s improving. If it’s already outpacing top experts in immunology, what fields are next?
Makes me wonder how we’ll redefine “expertise” in an era where machines can synthesize knowledge faster than humans can learn it.
24/29
@nodp53
And my dear Derya, it’s just the beginning!!!! Wow!!! NZT-48 is there.
25/29
@BtcBlackthorne
Do Gemini and Grok compete?
Are they close, or far away?
26/29
@ChefBeijing
I would call this ASI, not AGI anymore, because you’re not average people, not ever an average scientist.
27/29
@type2future
as a top immunologist, whats your holy grail: what's a problem you would love to see getting solved?
and how soon do you suppose ai can solve it?
28/29
@dannysuarez
Thats very exciting bro!
29/29
@paimon2cool
What impact do you expect this to have on medicine? Is it more likely to be researched focused or directly useful in patient care?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
[Discussion] Gpt-5 Took 6470 Steps to finish pokemon Red compared to 18,184 of o3 and 68,000 for Gemini and 35,000 for Claude
│
│
│ │
│ │
│ │ │
│ │ │

Commented on Sun Aug 17 03:22:10 2025 UTC
I don't know anything about Pokemon Red. Is there an absolute minimum number of steps it takes to complete?
I don't know anything about Pokemon Red. Is there an absolute minimum number of steps it takes to complete?
│
│
│ Commented on Sun Aug 17 04:14:58 2025 UTC
│
│ This guy did it in 5873 steps.
│
│ This is with pre-planning and previous knowledge of everything that will happen.
│

│
│
│ This guy did it in 5873 steps.
│
│ This is with pre-planning and previous knowledge of everything that will happen.
│
│
│ │
│ │
│ │ Commented on Sun Aug 17 04:21:52 2025 UTC
│ │
│ │ That makes it even more impressive than what the graph suggests tbh
│ │
│ │ From being 12000+ away to only 600 away from expert human level
│ │
│ │
│ │ That makes it even more impressive than what the graph suggests tbh
│ │
│ │ From being 12000+ away to only 600 away from expert human level
│ │
│ │ │
│ │ │
│ │ │ Commented on Sun Aug 17 05:28:40 2025 UTC
│ │ │
│ │ │ But these steps aren’t anywhere near equivalent the video’s steps, because these steps include complex operations that would take multiple in game steps
│ │ │
│ │ │
│ │ │ But these steps aren’t anywhere near equivalent the video’s steps, because these steps include complex operations that would take multiple in game steps
│ │ │
"AI Is Designing Bizarre New Physics Experiments That Actually Work"
Posted on Sun Aug 17 16:08:32 2025 UTC
/r/singularity/comments/1msuwg4/ai_is_designing_bizarre_new_physics_experiments/
May be paywalled for some. Mine wasn't:
AI Is Designing Bizarre New Physics Experiments That Actually Work
"First, they gave the AI all the components and devices that could be mixed and matched to construct an arbitrarily complicated interferometer. The AI started off unconstrained. It could design a detector that spanned hundreds of kilometers and had thousands of elements, such as lenses, mirrors, and lasers.
Initially, the AI’s designs seemed outlandish. “The outputs that the thing was giving us were really not comprehensible by people,” Adhikari said. “They were too complicated, and they looked like alien things or AI things. Just nothing that a human being would make, because it had no sense of symmetry, beauty, anything. It was just a mess.”
The researchers figured out how to clean up the AI’s outputs to produce interpretable ideas. Even so, the researchers were befuddled by the AI’s design. “If my students had tried to give me this thing, I would have said, ‘No, no, that’s ridiculous,’” Adhikari said. But the design was clearly effective.
It took months of effort to understand Digital Discovery of interferometric Gravitational Wave Detectors. It turned out that the machine had used a counterintuitive trick to achieve its goals. It added an additional three-kilometer-long ring between the main interferometer and the detector to circulate the light before it exited the interferometer’s arms. Adhikari’s team realized that the AI was probably using some esoteric theoretical principles that Russian physicists had identified decades ago to reduce quantum mechanical noise. No one had ever pursued those ideas experimentally. “It takes a lot to think this far outside of the accepted solution,” Adhikari said. “We really needed the AI.”"
/r/singularity/comments/1msuwg4/ai_is_designing_bizarre_new_physics_experiments/
May be paywalled for some. Mine wasn't:
AI Is Designing Bizarre New Physics Experiments That Actually Work
"First, they gave the AI all the components and devices that could be mixed and matched to construct an arbitrarily complicated interferometer. The AI started off unconstrained. It could design a detector that spanned hundreds of kilometers and had thousands of elements, such as lenses, mirrors, and lasers.
Initially, the AI’s designs seemed outlandish. “The outputs that the thing was giving us were really not comprehensible by people,” Adhikari said. “They were too complicated, and they looked like alien things or AI things. Just nothing that a human being would make, because it had no sense of symmetry, beauty, anything. It was just a mess.”
The researchers figured out how to clean up the AI’s outputs to produce interpretable ideas. Even so, the researchers were befuddled by the AI’s design. “If my students had tried to give me this thing, I would have said, ‘No, no, that’s ridiculous,’” Adhikari said. But the design was clearly effective.
It took months of effort to understand Digital Discovery of interferometric Gravitational Wave Detectors. It turned out that the machine had used a counterintuitive trick to achieve its goals. It added an additional three-kilometer-long ring between the main interferometer and the detector to circulate the light before it exited the interferometer’s arms. Adhikari’s team realized that the AI was probably using some esoteric theoretical principles that Russian physicists had identified decades ago to reduce quantum mechanical noise. No one had ever pursued those ideas experimentally. “It takes a lot to think this far outside of the accepted solution,” Adhikari said. “We really needed the AI.”"
GPT5 did new maths?
│
│


1/24
@VraserX
GPT-5 just casually did new mathematics.
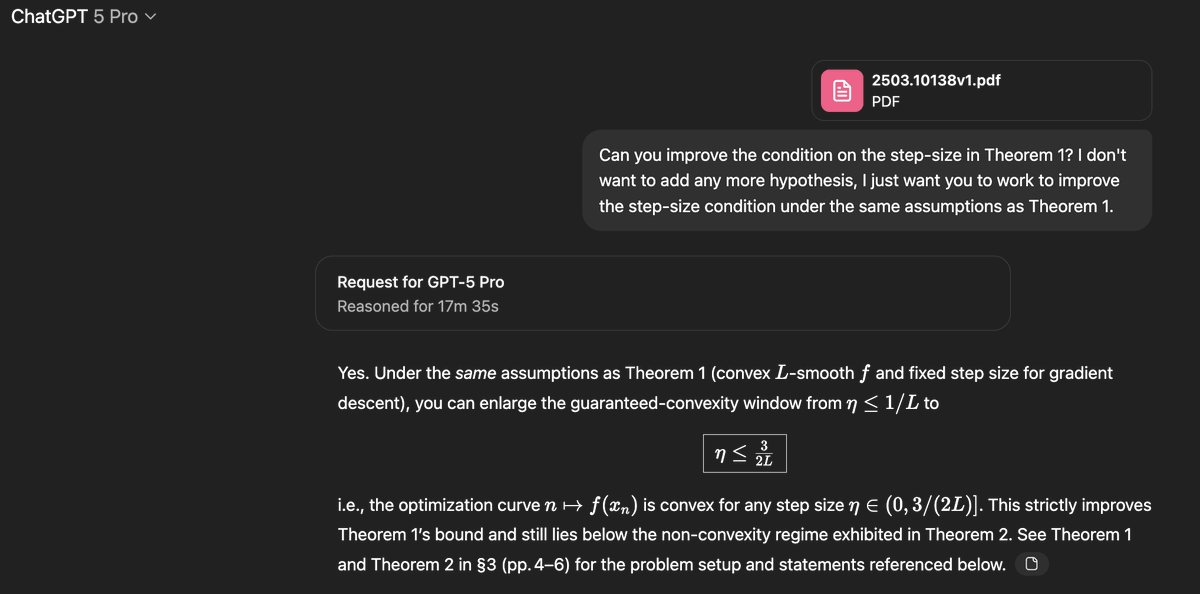
Sebastien Bubeck gave it an open problem from convex optimization, something humans had only partially solved. GPT-5-Pro sat down, reasoned for 17 minutes, and produced a correct proof improving the known bound from 1/L all the way to 1.5/L.
This wasn’t in the paper. It wasn’t online. It wasn’t memorized. It was new math. Verified by Bubeck himself.
Humans later closed the gap at 1.75/L, but GPT-5 independently advanced the frontier.
A machine just contributed original research-level mathematics.
If you’re not completely stunned by this, you’re not paying attention.
We’ve officially entered the era where AI isn’t just learning math, it’s creating it. @sama @OpenAI @kevinweil @gdb @markchen90
[Quoted tweet]
Claim: gpt-5-pro can prove new interesting mathematics.
Proof: I took a convex optimization paper with a clean open problem in it and asked gpt-5-pro to work on it. It proved a better bound than what is in the paper, and I checked the proof it's correct.
Details below.

2/24
@VraserX
Here is a simple explanation for all the doubters:
3/24
@AmericaAeterna
Does this make GPT-5 the first Level 4 Innovator AI?
4/24
@VraserX
Pretty much
5/24
@rawantitmc
New mathematics?
6/24
@VraserX
7/24
@DonValle
“New mathematics!” Lol @wowslop
8/24
@VraserX
9/24
@rosyna
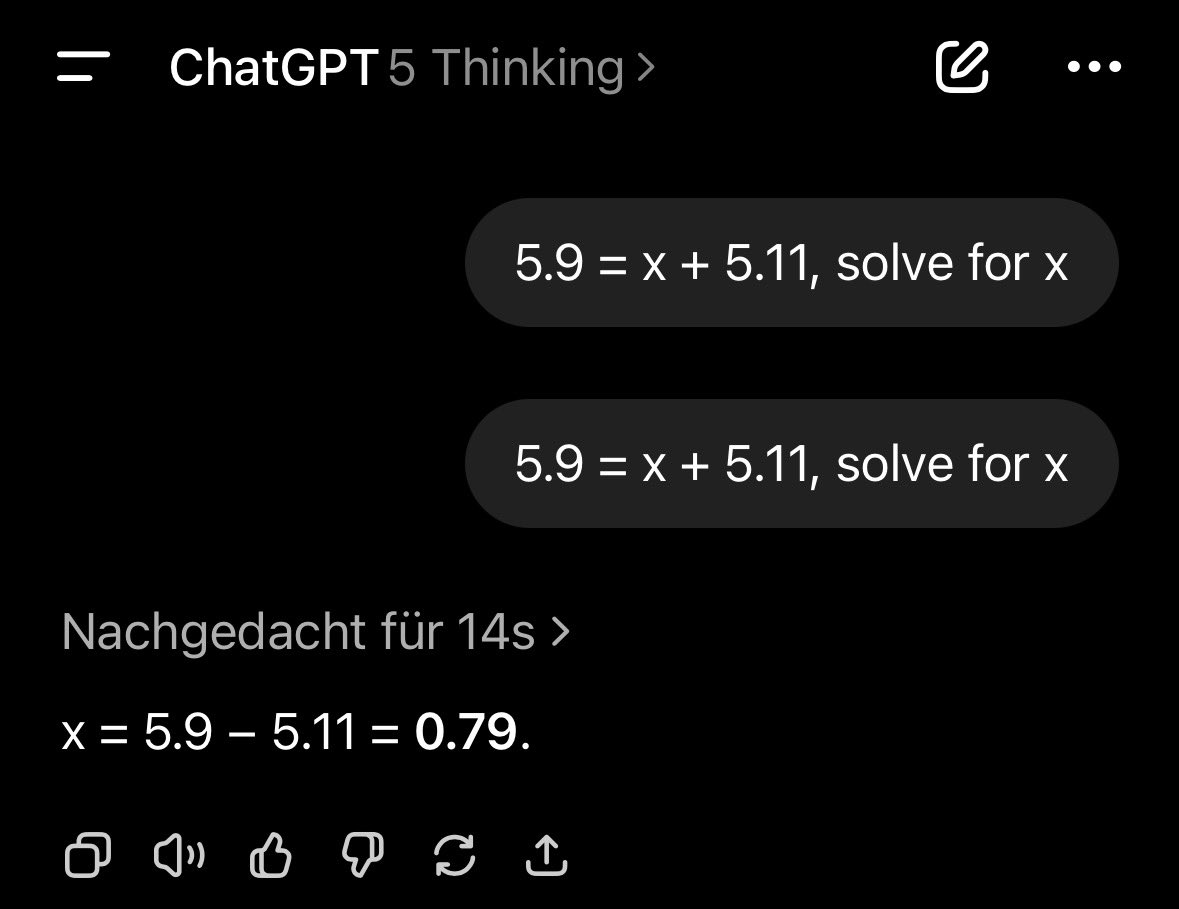
And yet, ChatGPT-5 can’t answer the following correctly:
5.9 = x + 5.11, solve for x
10/24
@VraserX
11/24
@kabirc
Such bullshyt. I gave it my son's grade 4 math problem (sets) and it failed miserably.
12/24
@VraserX
Skill issue. Use GPT-5 thinking.
13/24
@charlesr1971
Why can’t it resolve the Nuclear Fusion problem? How do we keep the plasma contained? If AI could solve this, the world would have cheap energy forever.
14/24
@VraserX
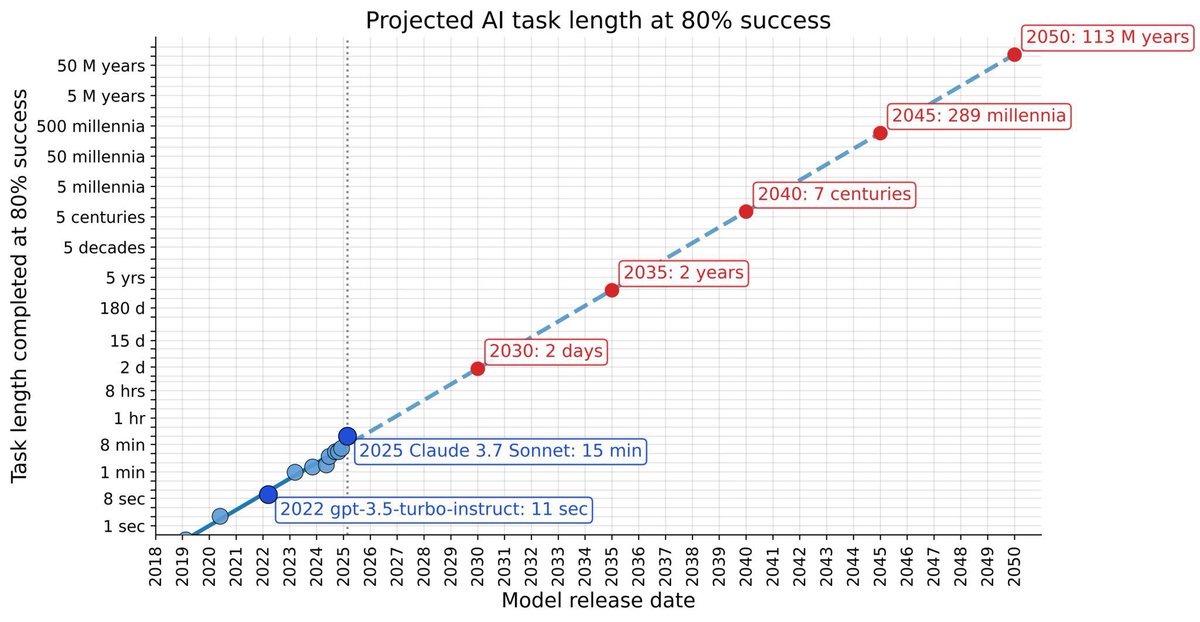
It will be able to do that in a few years. We need a lot more compute. At the current rate AI doubles task time compute every couple of months. Some people don’t understand exponentials.
15/24
@luisramos1977
No LLM can produce new knowledge, they only repeat what is fed.
16/24
@VraserX
Not true, GPT-5 can produce new insights and knowledge.
17/24
@Padilla1R1
@elonmusk
18/24
@CostcoPM
If this is true all it means is humans solved to this point with existing knowledge but the pieces weren’t in 1 place. AI doesn’t invent.
19/24
@rahulcsekaran
Absolutely amazing to see language models not just summarizing or helping with known problems, but actually producing novel mathematical proofs! The potential for co-discovery between AI and humans just keeps growing. Curious to see how this impacts future research collaborations.
20/24
@nftechie_
@mike_koko is this legit? Or slop?
21/24
@0xDEXhawk
Thats almost scary.
22/24
@WordAbstractor
@nntaleb thoughts on this sir?
23/24
@Jesse_G_PA
Fact check this
24/24
@DrKnowItAll16
Wow. A bit frightening that this has happened already in mid 2025.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@VraserX
GPT-5 just casually did new mathematics.
Sebastien Bubeck gave it an open problem from convex optimization, something humans had only partially solved. GPT-5-Pro sat down, reasoned for 17 minutes, and produced a correct proof improving the known bound from 1/L all the way to 1.5/L.
This wasn’t in the paper. It wasn’t online. It wasn’t memorized. It was new math. Verified by Bubeck himself.
Humans later closed the gap at 1.75/L, but GPT-5 independently advanced the frontier.
A machine just contributed original research-level mathematics.
If you’re not completely stunned by this, you’re not paying attention.
We’ve officially entered the era where AI isn’t just learning math, it’s creating it. @sama @OpenAI @kevinweil @gdb @markchen90
[Quoted tweet]
Claim: gpt-5-pro can prove new interesting mathematics.
Proof: I took a convex optimization paper with a clean open problem in it and asked gpt-5-pro to work on it. It proved a better bound than what is in the paper, and I checked the proof it's correct.
Details below.
2/24
@VraserX
Here is a simple explanation for all the doubters:
3/24
@AmericaAeterna
Does this make GPT-5 the first Level 4 Innovator AI?
4/24
@VraserX
Pretty much
5/24
@rawantitmc
New mathematics?
6/24
@VraserX
7/24
@DonValle
“New mathematics!” Lol @wowslop
8/24
@VraserX
9/24
@rosyna
And yet, ChatGPT-5 can’t answer the following correctly:
5.9 = x + 5.11, solve for x
10/24
@VraserX
11/24
@kabirc
Such bullshyt. I gave it my son's grade 4 math problem (sets) and it failed miserably.
12/24
@VraserX
Skill issue. Use GPT-5 thinking.
13/24
@charlesr1971
Why can’t it resolve the Nuclear Fusion problem? How do we keep the plasma contained? If AI could solve this, the world would have cheap energy forever.
14/24
@VraserX
It will be able to do that in a few years. We need a lot more compute. At the current rate AI doubles task time compute every couple of months. Some people don’t understand exponentials.
15/24
@luisramos1977
No LLM can produce new knowledge, they only repeat what is fed.
16/24
@VraserX
Not true, GPT-5 can produce new insights and knowledge.
17/24
@Padilla1R1
@elonmusk
18/24
@CostcoPM
If this is true all it means is humans solved to this point with existing knowledge but the pieces weren’t in 1 place. AI doesn’t invent.
19/24
@rahulcsekaran
Absolutely amazing to see language models not just summarizing or helping with known problems, but actually producing novel mathematical proofs! The potential for co-discovery between AI and humans just keeps growing. Curious to see how this impacts future research collaborations.
20/24
@nftechie_
@mike_koko is this legit? Or slop?
21/24
@0xDEXhawk
Thats almost scary.
22/24
@WordAbstractor
@nntaleb thoughts on this sir?
23/24
@Jesse_G_PA
Fact check this
24/24
@DrKnowItAll16
Wow. A bit frightening that this has happened already in mid 2025.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/35
@SebastienBubeck
Claim: gpt-5-pro can prove new interesting mathematics.
Proof: I took a convex optimization paper with a clean open problem in it and asked gpt-5-pro to work on it. It proved a better bound than what is in the paper, and I checked the proof it's correct.
Details below.
2/35
@SebastienBubeck
The paper in question is this one https://arxiv.org/pdf/2503.10138v1 which studies the following very natural question: in smooth convex optimization, under what conditions on the stepsize eta in gradient descent will the curve traced by the function value of the iterates be convex?
3/35
@SebastienBubeck
In the v1 of the paper they prove that if eta is smaller than 1/L (L is the smoothness) then one gets this property, and if eta is larger than 1.75/L then they construct a counterexample. So the open problem was: what happens in the range [1/L, 1.75/L].
4/35
@SebastienBubeck
As you can see in the top post, gpt-5-pro was able to improve the bound from this paper and showed that in fact eta can be taken to be as large as 1.5/L, so not quite fully closing the gap but making good progress. Def. a novel contribution that'd be worthy of a nice arxiv note.
5/35
@SebastienBubeck
Now the only reason why I won't post this as an arxiv note, is that the humans actually beat gpt-5 to the punch :-). Namely the arxiv paper has a v2 https://arxiv.org/pdf/2503.10138v2 with an additional author and they closed the gap completely, showing that 1.75/L is the tight bound.
6/35
@SebastienBubeck
By the way this is the proof it came up with:

7/35
@SebastienBubeck
And yeah the fact that it proves 1.5/L and not the 1.75/L also shows it didn't just search for the v2. Also the above proof is very different from the v2 proof, it's more of an evolution of the v1 proof.
8/35
@markerdmann
and there's some way to rule out that it didn't find the v2 via search? or is it that gpt-5-pro's proof is so different from the v2 that it wouldn't have mattered?
9/35
@SebastienBubeck
yeah it's different from the v2 proof and also v2 is a better result actually
10/35
@jasondeanlee
Is this the model we can use or an internal model?
11/35
@SebastienBubeck
This is literally just gpt-5-pro. Note that this was my second attempt at this question, in the first attempt I just asked it to improve theorem 1 and it added more assumptions to do so. So my second prompt clarified that I want no additional assumptions.
12/35
@baouws
How long did it take you to check the proof? (longer than 17.35 minutes?)
13/35
@SebastienBubeck
25 minutes, sadly I'm a bit rusty :-(
14/35
@rajatgupta99
This feels like a shift, not just consuming existing knowledge, but generating new proofs. Curious what the limits are: can it tackle entirely unsolved problems, or only refine existing ones?
15/35
@xlr8harder
pro can web search. are you sure it didn't find the v2?
16/35
@fleetingbits
so, I believe this - but why not just take a large database of papers, collect the most interesting results that GPT-5 pro can produce
and then, like, publish them as a compendium or something as marketing?
17/35
@Lume_Layr
Really… I think you might know exactly where this logic scaffold came from. Timestamps don’t lie.
18/35
@doodlestein
Take a look at this repo. I’m pretty sure GPT-5 has already developed multiple serious academic papers worth of new ideas. And not only that, it actually came up with most of the prompts itself:
https://github.com/dikklesworthstone/model_guided_research
19/35
@pcts4you
@AskPerplexity What are the implications here
20/35
@BaDjeidy
Wow 17 min thinking impressive! Mine is always getting stuck for some reason.
21/35
@ElieMesso
@skdh might be interesting to you.
22/35
@Ghost_Pilot_MD

we getting there!
23/35
@Rippinghawk
@Papa_Ge0rgi0
24/35
@Zenul_Abidin
I feel like it should be used to hammer in existing mathematical concepts into people's minds.
There are so many of them that people should be learning at this point.
25/35
@zjasper666
This is pretty sick!
26/35
@threadreaderapp
Your thread is very popular today! /search?q=#TopUnroll Thread by @SebastienBubeck on Thread Reader App @_cherki82_ for unroll
@_cherki82_ for unroll
27/35
@JuniperViews
That’s amazing
28/35
@CommonSenseMars
I wonder if you prompted it again to improve it further, GPT-5 would say “no”.
29/35
@seanspraguesr
GPT 4 made progress as well.
Resolving the Riemann Hypothesis: A Geometric Algebra Proof via the Trilemma of Symmetry, Conservation, and Boundedness


30/35
@TinkeredThinker
cc: @0x77dev @jposhaughnessy
31/35
@AldousH57500603
@lichtstifter
32/35
@a_i_m_rue
5-pro intimidates me by how much smarter than me it is. Its gotta be pushing 150iq.
33/35
@_cherki82_
@UnrollHelper
34/35
@gtrump_t
Wow
35/35
@Ampa37143359
@rasputin1500
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@SebastienBubeck
Claim: gpt-5-pro can prove new interesting mathematics.
Proof: I took a convex optimization paper with a clean open problem in it and asked gpt-5-pro to work on it. It proved a better bound than what is in the paper, and I checked the proof it's correct.
Details below.
2/35
@SebastienBubeck
The paper in question is this one https://arxiv.org/pdf/2503.10138v1 which studies the following very natural question: in smooth convex optimization, under what conditions on the stepsize eta in gradient descent will the curve traced by the function value of the iterates be convex?
3/35
@SebastienBubeck
In the v1 of the paper they prove that if eta is smaller than 1/L (L is the smoothness) then one gets this property, and if eta is larger than 1.75/L then they construct a counterexample. So the open problem was: what happens in the range [1/L, 1.75/L].
4/35
@SebastienBubeck
As you can see in the top post, gpt-5-pro was able to improve the bound from this paper and showed that in fact eta can be taken to be as large as 1.5/L, so not quite fully closing the gap but making good progress. Def. a novel contribution that'd be worthy of a nice arxiv note.
5/35
@SebastienBubeck
Now the only reason why I won't post this as an arxiv note, is that the humans actually beat gpt-5 to the punch :-). Namely the arxiv paper has a v2 https://arxiv.org/pdf/2503.10138v2 with an additional author and they closed the gap completely, showing that 1.75/L is the tight bound.
6/35
@SebastienBubeck
By the way this is the proof it came up with:
7/35
@SebastienBubeck
And yeah the fact that it proves 1.5/L and not the 1.75/L also shows it didn't just search for the v2. Also the above proof is very different from the v2 proof, it's more of an evolution of the v1 proof.
8/35
@markerdmann
and there's some way to rule out that it didn't find the v2 via search? or is it that gpt-5-pro's proof is so different from the v2 that it wouldn't have mattered?
9/35
@SebastienBubeck
yeah it's different from the v2 proof and also v2 is a better result actually
10/35
@jasondeanlee
Is this the model we can use or an internal model?
11/35
@SebastienBubeck
This is literally just gpt-5-pro. Note that this was my second attempt at this question, in the first attempt I just asked it to improve theorem 1 and it added more assumptions to do so. So my second prompt clarified that I want no additional assumptions.
12/35
@baouws
How long did it take you to check the proof? (longer than 17.35 minutes?)
13/35
@SebastienBubeck
25 minutes, sadly I'm a bit rusty :-(
14/35
@rajatgupta99
This feels like a shift, not just consuming existing knowledge, but generating new proofs. Curious what the limits are: can it tackle entirely unsolved problems, or only refine existing ones?
15/35
@xlr8harder
pro can web search. are you sure it didn't find the v2?
16/35
@fleetingbits
so, I believe this - but why not just take a large database of papers, collect the most interesting results that GPT-5 pro can produce
and then, like, publish them as a compendium or something as marketing?
17/35
@Lume_Layr
Really… I think you might know exactly where this logic scaffold came from. Timestamps don’t lie.
18/35
@doodlestein
Take a look at this repo. I’m pretty sure GPT-5 has already developed multiple serious academic papers worth of new ideas. And not only that, it actually came up with most of the prompts itself:
https://github.com/dikklesworthstone/model_guided_research
19/35
@pcts4you
@AskPerplexity What are the implications here
20/35
@BaDjeidy
Wow 17 min thinking impressive! Mine is always getting stuck for some reason.
21/35
@ElieMesso
@skdh might be interesting to you.
22/35
@Ghost_Pilot_MD
we getting there!
23/35
@Rippinghawk
@Papa_Ge0rgi0
24/35
@Zenul_Abidin
I feel like it should be used to hammer in existing mathematical concepts into people's minds.
There are so many of them that people should be learning at this point.
25/35
@zjasper666
This is pretty sick!
26/35
@threadreaderapp
Your thread is very popular today! /search?q=#TopUnroll Thread by @SebastienBubeck on Thread Reader App
@_cherki82_ for unroll27/35
@JuniperViews
That’s amazing
28/35
@CommonSenseMars
I wonder if you prompted it again to improve it further, GPT-5 would say “no”.
29/35
@seanspraguesr
GPT 4 made progress as well.
Resolving the Riemann Hypothesis: A Geometric Algebra Proof via the Trilemma of Symmetry, Conservation, and Boundedness
30/35
@TinkeredThinker
cc: @0x77dev @jposhaughnessy
31/35
@AldousH57500603
@lichtstifter
32/35
@a_i_m_rue
5-pro intimidates me by how much smarter than me it is. Its gotta be pushing 150iq.
33/35
@_cherki82_
@UnrollHelper
34/35
@gtrump_t
Wow
35/35
@Ampa37143359
@rasputin1500
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Commented on Thu Aug 21 13:18:20 2025 UTC
https://nitter.net/ErnestRyu/status/1958408925864403068
I paste the comments by Ernest Ryu here:
This is really exciting and impressive, and this stuff is in my area of mathematics research (convex optimization). I have a nuanced take.
There are 3 proofs in discussion: v1. ( η ≤ 1/L, discovered by human ) v2. ( η ≤ 1.75/L, discovered by human ) v.GTP5 ( η ≤ 1.5/L, discovered by AI ) Sebastien argues that the v.GPT5 proof is impressive, even though it is weaker than the v2 proof.
The proof itself is arguably not very difficult for an expert in convex optimization, if the problem is given. Knowing that the key inequality to use is [Nesterov Theorem 2.1.5], I could prove v2 in a few hours by searching through the set of relevant combinations.
(And for reasons that I won’t elaborate here, the search for the proof is precisely a 6-dimensional search problem. The author of the v2 proof, Moslem Zamani, also knows this. I know Zamani’s work enough to know that he knows.)
(In research, the key challenge is often in finding problems that are both interesting and solvable. This paper is an example of an interesting problem definition that admits a simple solution.)
When proving bounds (inequalities) in math, there are 2 challenges: (i) Curating the correct set of base/ingredient inequalities. (This is the part that often requires more creativity.) (ii) Combining the set of base inequalities. (Calculations can be quite arduous.)
In this problem, that [Nesterov Theorem 2.1.5] should be the key inequality to be used for (i) is known to those working in this subfield.
So, the choice of base inequalities (i) is clear/known to me, ChatGPT, and Zamani. Having (i) figured out significantly simplifies this problem. The remaining step (ii) becomes mostly calculations.
The proof is something an experienced PhD student could work out in a few hours. That GPT-5 can do it with just ~30 sec of human input is impressive and potentially very useful to the right user. However, GPT5 is by no means exceeding the capabilities of human experts."
https://nitter.net/ErnestRyu/status/1958408925864403068
I paste the comments by Ernest Ryu here:
This is really exciting and impressive, and this stuff is in my area of mathematics research (convex optimization). I have a nuanced take.
There are 3 proofs in discussion: v1. ( η ≤ 1/L, discovered by human ) v2. ( η ≤ 1.75/L, discovered by human ) v.GTP5 ( η ≤ 1.5/L, discovered by AI ) Sebastien argues that the v.GPT5 proof is impressive, even though it is weaker than the v2 proof.
The proof itself is arguably not very difficult for an expert in convex optimization, if the problem is given. Knowing that the key inequality to use is [Nesterov Theorem 2.1.5], I could prove v2 in a few hours by searching through the set of relevant combinations.
(And for reasons that I won’t elaborate here, the search for the proof is precisely a 6-dimensional search problem. The author of the v2 proof, Moslem Zamani, also knows this. I know Zamani’s work enough to know that he knows.)
(In research, the key challenge is often in finding problems that are both interesting and solvable. This paper is an example of an interesting problem definition that admits a simple solution.)
When proving bounds (inequalities) in math, there are 2 challenges: (i) Curating the correct set of base/ingredient inequalities. (This is the part that often requires more creativity.) (ii) Combining the set of base inequalities. (Calculations can be quite arduous.)
In this problem, that [Nesterov Theorem 2.1.5] should be the key inequality to be used for (i) is known to those working in this subfield.
So, the choice of base inequalities (i) is clear/known to me, ChatGPT, and Zamani. Having (i) figured out significantly simplifies this problem. The remaining step (ii) becomes mostly calculations.
The proof is something an experienced PhD student could work out in a few hours. That GPT-5 can do it with just ~30 sec of human input is impressive and potentially very useful to the right user. However, GPT5 is by no means exceeding the capabilities of human experts."
│
│
│ Commented on Thu Aug 21 14:02:25 2025 UTC
│
│ Task shortened from a few hours with domain expert-level human input, to 30 secs with a general model available on the web. Impressive. Peak is not even on the horizon.
│
│
│ Task shortened from a few hours with domain expert-level human input, to 30 secs with a general model available on the web. Impressive. Peak is not even on the horizon.
│
Similar threads
- Replies
- 9
- Views
- 1K