
1/4
@AngryTomtweets
Skywork just dropped Super Agents.
The world's first open-source deep research agent framework.
More here
https://video.twimg.com/amplify_video/1925196592757592065/vid/avc1/1280x720/_0rkMLviQhK3hGBq.mp4
2/4
@heyrobinai
ok now i need to try this immediately
3/4
@AngryTomtweets
yeah... you should man!
4/4
@shawnchauhan1
This could redefine productivity.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@AngryTomtweets
Skywork just dropped Super Agents.
The world's first open-source deep research agent framework.
More here
https://video.twimg.com/amplify_video/1925196592757592065/vid/avc1/1280x720/_0rkMLviQhK3hGBq.mp4
2/4
@heyrobinai
ok now i need to try this immediately
3/4
@AngryTomtweets
yeah... you should man!
4/4
@shawnchauhan1
This could redefine productivity.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@Skywork_ai
Introducing Skywork Super Agents — the originator of AI workspace agents, which turn your 8 hours of work into 8 minutes.
Try it now: The Originator of AI Workspace Agents
https://video.twimg.com/amplify_video/1925196592757592065/vid/avc1/1280x720/_0rkMLviQhK3hGBq.mp4
2/11
@Skywork_ai
Content creation is awful. We spend 60% of our week producing paperworks instead of driving real business value.
So there come Skywork Super Agents, letting you generate docs, slides, sheets, webpages, and podcasts from a SINGLE prompt, cutting your work time by up to 90%.
https://video.twimg.com/amplify_video/1925196679395033088/vid/avc1/640x368/DwQBCUKPGmVYkWg1.mp4
3/11
@Skywork_ai
Skywork goes deeper than anyone else.
Our Super Agents boast unmatched deep research capabilities, surfacing 10x more source materials than competitors, while delivering professional-grade results at 40% lower cost than OpenAI.
We're proud to lead the GAIA Agent Leaderboard!
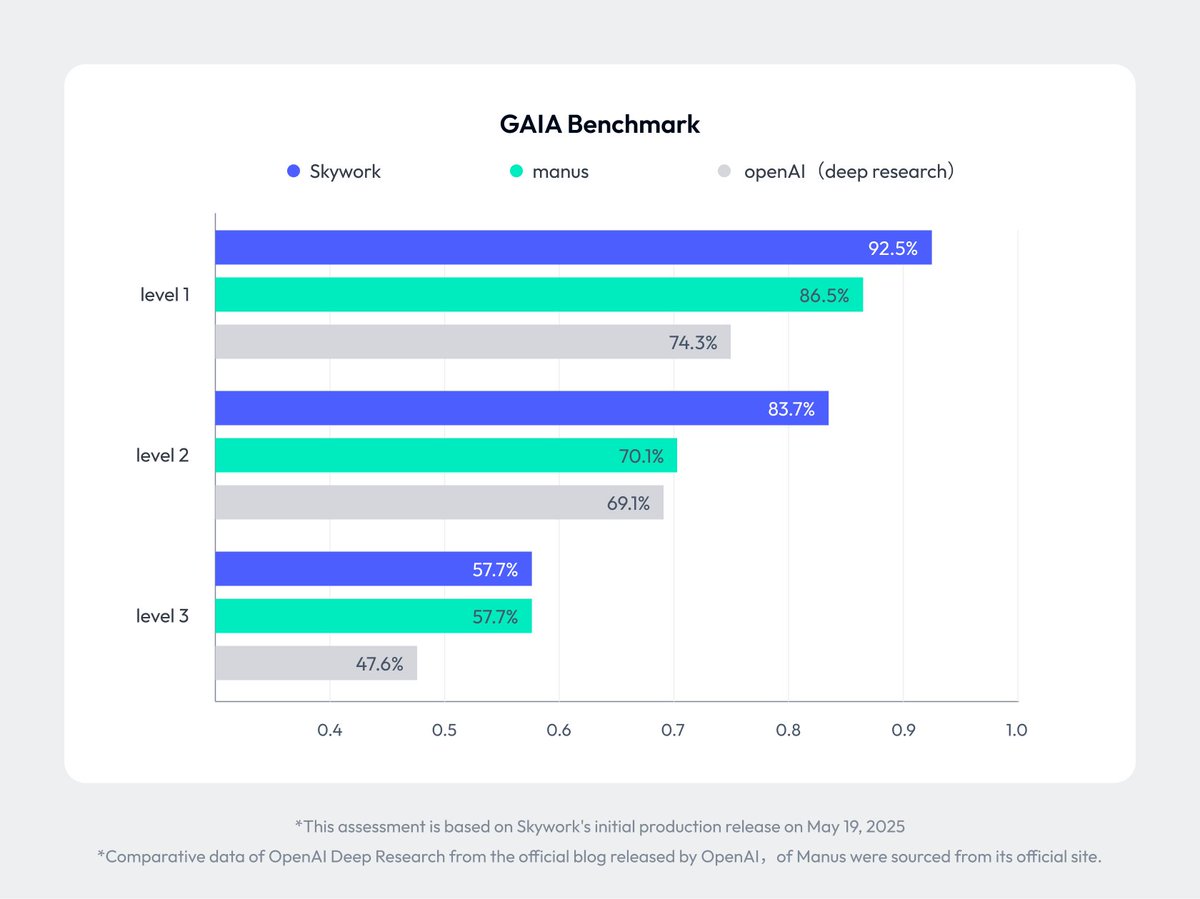
4/11
@Skywork_ai
Skywork offers seamless online editing for its outputs, especially slides. Easily export to local files or Google Workspace. Plus, integrate your private knowledge base for hyper-relevant content!
https://video.twimg.com/amplify_video/1925197054122553344/vid/avc1/2560x1440/kuoBpM3lIJcm4wfh.mp4
5/11
@Skywork_ai
Trust is key. Skywork delivers trusted, traceable results. Every piece of generated content can be traced back to the source paragraphs, so you can verify and use it with confidence.
https://video.twimg.com/amplify_video/1925197447682506752/vid/avc1/2560x1440/sDofyr7oSVQ7jwUV.mp4
6/11
@Skywork_ai
Calling all developers! Skywork is releasing the world’s first open-source deep research agent framework, along with 3 MCPs for docs, sheets, and slides. Integrate and extend!
https://video.twimg.com/amplify_video/1925197658232438785/vid/avc1/2560x1440/2ib4rKBPlEHT8m-O.mp4
7/11
@Skywork_ai
Check out some cool examples from Skywork users:
 Analysis of NVIDIA Stock: The Originator of AI Workspace Agents
Analysis of NVIDIA Stock: The Originator of AI Workspace Agents
 Tesla Cybertruck Competitive Analysis: The Originator of AI Workspace Agents
Tesla Cybertruck Competitive Analysis: The Originator of AI Workspace Agents
 Family Budget Overview: The Originator of AI Workspace Agents
Family Budget Overview: The Originator of AI Workspace Agents
Try it now The Originator of AI Workspace Agents
8/11
@mhdfaran
This is Huge. Congrats for the launch.
9/11
@Skywork_ai
Thank you so much! We’re beyond excited to finally share Skywork with the world.
We’re beyond excited to finally share Skywork with the world.
10/11
@samuelwoods_
Turning 8 hours into 8 minutes sounds like a massive productivity leap
11/11
@Skywork_ai
It really is a game changer! ️ Let’s gooo!
️ Let’s gooo!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@Skywork_ai
Introducing Skywork Super Agents — the originator of AI workspace agents, which turn your 8 hours of work into 8 minutes.
Try it now: The Originator of AI Workspace Agents
https://video.twimg.com/amplify_video/1925196592757592065/vid/avc1/1280x720/_0rkMLviQhK3hGBq.mp4
2/11
@Skywork_ai
Content creation is awful. We spend 60% of our week producing paperworks instead of driving real business value.
So there come Skywork Super Agents, letting you generate docs, slides, sheets, webpages, and podcasts from a SINGLE prompt, cutting your work time by up to 90%.
https://video.twimg.com/amplify_video/1925196679395033088/vid/avc1/640x368/DwQBCUKPGmVYkWg1.mp4
3/11
@Skywork_ai
Skywork goes deeper than anyone else.
Our Super Agents boast unmatched deep research capabilities, surfacing 10x more source materials than competitors, while delivering professional-grade results at 40% lower cost than OpenAI.
We're proud to lead the GAIA Agent Leaderboard!
4/11
@Skywork_ai
Skywork offers seamless online editing for its outputs, especially slides. Easily export to local files or Google Workspace. Plus, integrate your private knowledge base for hyper-relevant content!
https://video.twimg.com/amplify_video/1925197054122553344/vid/avc1/2560x1440/kuoBpM3lIJcm4wfh.mp4
5/11
@Skywork_ai
Trust is key. Skywork delivers trusted, traceable results. Every piece of generated content can be traced back to the source paragraphs, so you can verify and use it with confidence.
https://video.twimg.com/amplify_video/1925197447682506752/vid/avc1/2560x1440/sDofyr7oSVQ7jwUV.mp4
6/11
@Skywork_ai
Calling all developers! Skywork is releasing the world’s first open-source deep research agent framework, along with 3 MCPs for docs, sheets, and slides. Integrate and extend!
https://video.twimg.com/amplify_video/1925197658232438785/vid/avc1/2560x1440/2ib4rKBPlEHT8m-O.mp4
7/11
@Skywork_ai
Check out some cool examples from Skywork users:
Analysis of NVIDIA Stock: The Originator of AI Workspace Agents Tesla Cybertruck Competitive Analysis: The Originator of AI Workspace Agents Family Budget Overview: The Originator of AI Workspace AgentsTry it now
The Originator of AI Workspace Agents8/11
@mhdfaran
This is Huge. Congrats for the launch.
9/11
@Skywork_ai
Thank you so much!
We’re beyond excited to finally share Skywork with the world.10/11
@samuelwoods_
Turning 8 hours into 8 minutes sounds like a massive productivity leap
11/11
@Skywork_ai
It really is a game changer!
️ Let’s gooo!To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

 Generate smart text from audio, images, video, and text
Generate smart text from audio, images, video, and text


 Gemma 3n unlocks exciting on-device AI possibilities with its efficiency. This could revolutionize mobile applications! Great stuff! Sharing knowledge is key.
Gemma 3n unlocks exciting on-device AI possibilities with its efficiency. This could revolutionize mobile applications! Great stuff! Sharing knowledge is key. Major boost in reasoning performance
Major boost in reasoning performance For non-complex reasoning tasks, we recommend using V3 — just turn off “DeepThink”
For non-complex reasoning tasks, we recommend using V3 — just turn off “DeepThink” API usage remains unchanged
API usage remains unchanged Models are now released under the MIT License, just like DeepSeek-R1!
Models are now released under the MIT License, just like DeepSeek-R1! Open-source weights:
Open-source weights: 







 DeepSeek-R1-0528: 63.9%
DeepSeek-R1-0528: 63.9%
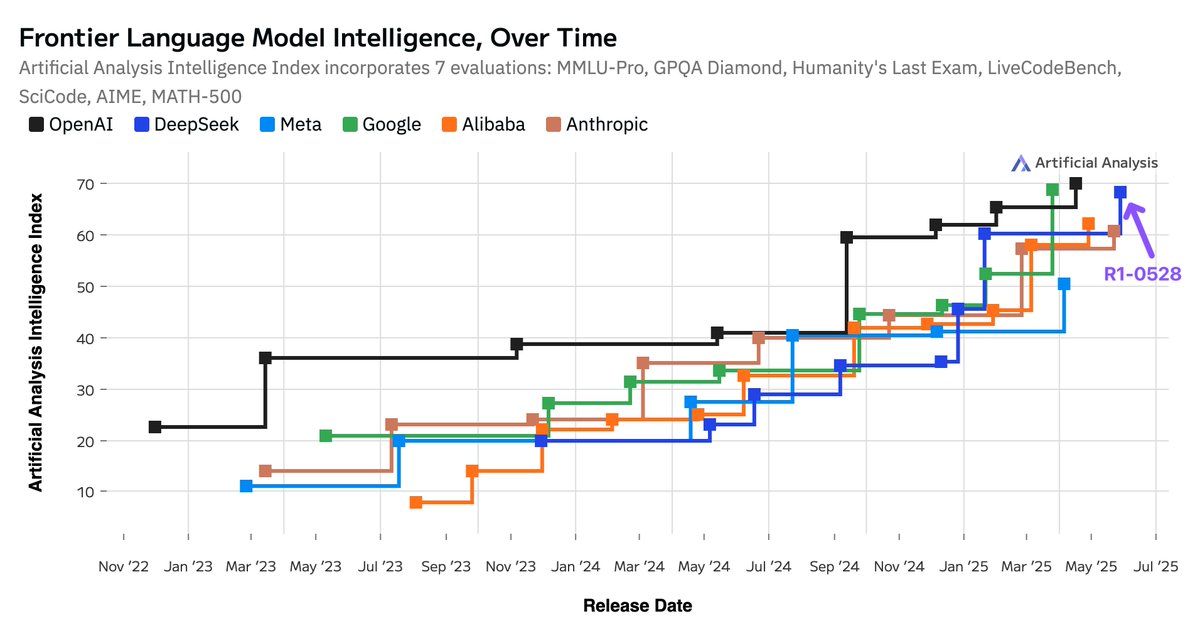
 Intelligence increases across the board: Biggest jumps seen in AIME 2024 (Competition Math, +21 points), LiveCodeBench (Code generation, +15 points), GPQA Diamond (Scientific Reasoning, +10 points) and Humanity’s Last Exam (Reasoning & Knowledge, +6 points)
Intelligence increases across the board: Biggest jumps seen in AIME 2024 (Competition Math, +21 points), LiveCodeBench (Code generation, +15 points), GPQA Diamond (Scientific Reasoning, +10 points) and Humanity’s Last Exam (Reasoning & Knowledge, +6 points) No change to architecture: R1-0528 is a post-training update with no change to the V3/R1 architecture - it remains a large 671B model with 37B active parameters
No change to architecture: R1-0528 is a post-training update with no change to the V3/R1 architecture - it remains a large 671B model with 37B active parameters Significant leap in coding skills: R1 is now matching Gemini 2.5 Pro in the Artificial Analysis Coding Index and is behind only o4-mini (high) and o3
Significant leap in coding skills: R1 is now matching Gemini 2.5 Pro in the Artificial Analysis Coding Index and is behind only o4-mini (high) and o3 Increased token usage: R1-0528 used 99 million tokens to complete the evals in Artificial Analysis Intelligence Index, 40% more than the original R1’s 71 million tokens - ie. the new R1 thinks for longer than the original R1. This is still not the highest token usage number we have seen: Gemini 2.5 Pro is using 30% more tokens than R1-0528
Increased token usage: R1-0528 used 99 million tokens to complete the evals in Artificial Analysis Intelligence Index, 40% more than the original R1’s 71 million tokens - ie. the new R1 thinks for longer than the original R1. This is still not the highest token usage number we have seen: Gemini 2.5 Pro is using 30% more tokens than R1-0528 The gap between open and closed models is smaller than ever: open weights models have continued to maintain intelligence gains in-line with proprietary models. DeepSeek’s R1 release in January was the first time an open-weights model achieved the #2 position and DeepSeek’s R1 update today brings it back to the same position
The gap between open and closed models is smaller than ever: open weights models have continued to maintain intelligence gains in-line with proprietary models. DeepSeek’s R1 release in January was the first time an open-weights model achieved the #2 position and DeepSeek’s R1 update today brings it back to the same position China remains neck and neck with the US: models from China-based AI Labs have all but completely caught up to their US counterparts, this release continues the emerging trend. As of today, DeepSeek leads US based AI labs including Anthropic and Meta in Artificial Analysis Intelligence Index
China remains neck and neck with the US: models from China-based AI Labs have all but completely caught up to their US counterparts, this release continues the emerging trend. As of today, DeepSeek leads US based AI labs including Anthropic and Meta in Artificial Analysis Intelligence Index Improvements driven by reinforcement learning: DeepSeek has shown substantial intelligence improvements with the same architecture and pre-train as their original DeepSeek R1 release. This highlights the continually increasing importance of post-training, particularly for reasoning models trained with reinforcement learning (RL) techniques. OpenAI disclosed a 10x scaling of RL compute between o1 and o3 - DeepSeek have just demonstrated that so far, they can keep up with OpenAI’s RL compute scaling. Scaling RL demands less compute than scaling pre-training and offers an efficient way of achieving intelligence gains, supporting AI Labs with fewer GPUs
Improvements driven by reinforcement learning: DeepSeek has shown substantial intelligence improvements with the same architecture and pre-train as their original DeepSeek R1 release. This highlights the continually increasing importance of post-training, particularly for reasoning models trained with reinforcement learning (RL) techniques. OpenAI disclosed a 10x scaling of RL compute between o1 and o3 - DeepSeek have just demonstrated that so far, they can keep up with OpenAI’s RL compute scaling. Scaling RL demands less compute than scaling pre-training and offers an efficient way of achieving intelligence gains, supporting AI Labs with fewer GPUs





 it is also open source
it is also open source






















 , losing quickly
, losing quickly  but can’t click the right pieces…
but can’t click the right pieces… !
!


























